Naukę  języka SQL w zakresie pisania zapytań, powinieneś rozpocząć właśnie od tego rozdziału. Zrozumienie procesu przetwarzania kwerendy jest niezbędne, aby w pełni świadomie tworzyć polecenia SQL i móc wykorzystać ich możliwości.
języka SQL w zakresie pisania zapytań, powinieneś rozpocząć właśnie od tego rozdziału. Zrozumienie procesu przetwarzania kwerendy jest niezbędne, aby w pełni świadomie tworzyć polecenia SQL i móc wykorzystać ich możliwości.
W artykule tym, znajdziesz informacje o kolejności kroków przetwarzania zapytań.
Analizując ten proces, nie skupiaj się proszę na szczegółach i możliwościach konkretnych poleceń. Chciałbym abyś uchwycił tu ogólne zasady, w jaki sposób wykonywane są kwerendy. Temat ten, z uwagi na zakres materiału podzieliłem na dwie części. W tej, omawiam pełen proces na prostym przykładzie zapytania do pojedynczej tabeli.
Druga część wymaga znajomości zasad łączenia tabel i umieściłem ją zaraz po rozdziale opisującym te zagadnienia. Wyjaśniam w niej aspekty kolejności łączenia tabel.
Kolejność kroków przetwarzania zapytań
Wykonywanie każdej kwerendy przez silnik bazodanowy odbywa się krokowo, w ściśle określonej kolejności. Reguły te są spójne dla wszystkich relacyjnych baz danych.
W konstrukcji zapytań możemy wyszczególnić 6 głównych bloków logicznych.
(Step 5) SELECT -- określanie kształtu wyniku, selekcja pionowa (kolumn)
(Step 1) FROM -- określenie źródła (źródeł) i relacji między nimi
(Step 2) WHERE -- filtracja rekordów
(Step 3) GROUP BY -- grupowanie rekordów
(Step 4) HAVING -- filtrowanie grup
(Step 6) ORDER BY -- sortowanie wyniku
W ramach każdego z nich, możemy umieszczać całkiem złożone konstrukcje. Podzapytania, zapytania skorelowane, dodatkowe polecenia, takie jak operator DISTINCT czy TOP w SELECT. Poszczególne klauzule i zakres ich możliwości omawiam szczegółowo w kolejnych rozdziałach tego kursu.
Najprostsze polecenie SQL może składać się z samego SELECTa np. :
SELECT 'Hello World!'
Takie „zapytania” rzadko kiedy nas interesują i tak naprawdę trudno nawet nazwać je zapytaniami. Zazwyczaj chcemy pobierać dane z jakiegoś źródła np. tabeli czy widoku. Do ich określenia, służy klauzula FROM. Ustalmy więc, że kwerenda to konstrukcja składająca się przynajmniej z bloków SELECT oraz FROM.
Poza nimi, wszystkie pozostałe są opcjonalne. Warto jednak zauważyć, że stosowanie HAVING bez GROUP BY również za bardzo nie będzie miało sensu. Z punktu widzenia samej konstrukcji jest jednak możliwe.
Wynikiem przetwarzania każdego z kroków jest tabela wirtualna (VT) , będąca jednocześnie obiektem wejściowym kolejnego etapu. Do tabel wirtualnych, czyli produktów pośrednich kroków przetwarzania, nie mamy dostępu z zewnątrz. Są one logicznymi strukturami, które rozpatrujemy tylko w kontekście analizy teoretycznej.
Trzeba podkreślić, że faktyczny sposób realizacji zapytań, jest wykonywany za pomocą efektywnych i zoptymalizowanych przez silnik bazodanowy metod. W efekcie końcowym, pozwalają one na osiągnięcie dokładnie tego samego wyniku co w analizie teoretycznej. Podkreślam to, bo szczególnie opis iloczynów kartezjańskich czy konieczność czytania całej zawartości tabel może słusznie budzić w Tobie niedowierzanie czy wewnętrzny sprzeciw 🙂
W analizie teoretycznej tak właśnie się dzieje, aby osiągnąć określony wynik. W praktyce, silnik bazodanowy zna skróty, które doprowadzają dokładnie do tego samego celu – znacznie szybciej.
Analiza przetwarzania kwerendy na przykładzie
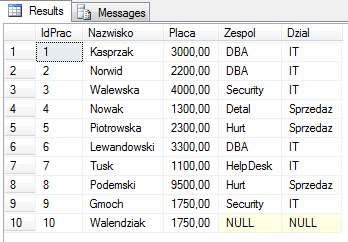
Cały proces najlepiej prześledzić na przykładzie. Na początek coś prostego – zapytanie pobierające dane tylko z jednej tabeli dbo.Pracownicy. Zawartość tego zbioru jest następująca :
IdPrac Nazwisko Placa Zespol Dzial ------ --------------- --------------------- ---------- ---------- 1 Kasprzak 3000,00 DBA IT 2 Norwid 2200,00 DBA IT 3 Walewska 4000,00 Security IT 4 Nowak 1300,00 Detal Sprzedaz 5 Piotrowska 2300,00 Hurt Sprzedaz 6 Lewandowski 3300,00 DBA IT 7 Tusk 1100,00 HelpDesk IT 8 Podemski 9500,00 Hurt Sprzedaz 9 Gmoch 1750,00 Security IT 10 Walendziak 1750,00 NULL NULL (10 row(s) affected)
W naszym scenariuszu, będziemy chcieli wyświetlić informacje o liczbie pracowników, pracujących w zespołach wieloosobowych (więcej niż jeden pracownik) w ramach Działu IT. Końcowy wynik posortujemy rosnąco po liczbie pracowników.
Kwerenda realizująca to zadanie będzie wyglądała następująco :
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy
WHERE Dzial = 'IT'
GROUP BY Zespol
HAVING COUNT ( IdPrac ) > 1
ORDER BY LiczbaPracowników
Zapytanie to wykorzystuje wszystkie bloki logiczne z jakich może składać się dowolna kwerenda. Na razie celowo nie omawiam logiki łączenia tabel (pobieramy dane tylko z jednego zbioru), aby lepiej przedstawić generalne zasady.
Krok 1 : FROM – określenie źródła (źródeł) i relacji między nimi
Na początku trzeba określić skąd będziemy czerpać dane. Dlatego pierwszym krokiem jest klauzula FROM. W naszym przykładzie zbiorem wejściowym jest jedna tabela – dbo.Pracownicy. Wynikiem przetwarzania pierwszego kroku będzie zatem tabela wirtualna VT1, zawierającą całą (tak, CAŁĄ !) zawartość tego zbioru.
W tym momencie powinna zapalić się u Ciebie lampka ostrzegawcza. Jak to? Czy faktycznie tak jest, że jak odpytuję tabelę zawierającą 100 milionów rekordów to wszystkie te elementy są czytane i przekazywane do jakiejś VT1? Teoretycznie, zgodnie z zasadami logicznego przetwarzania – tak właśnie się dzieje.
Tylko teoretycznie. Jak już wspominałem, w praktyce silnik serwera zna efektywne sposoby dostępu do danych. Z pewnością jeśli nie są potrzebne wszystkie dane tabeli w kolejnych krokach, to nie będzie do nich sięgał.
Zawartość tabeli VT1 będzie więc wyglądała identycznie jak tabeli dbo.Pracownicy :
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy -- wynik VT1
WHERE Dzial = 'IT'
GROUP BY Zespol
HAVING COUNT ( IdPrac ) > 1
ORDER BY LiczbaPracowników
Krok 2 : WHERE – filtrowanie rekordów
Krok ten, działa na wyniku poprzedniego. Czyli w naszym wypadku będzie operował na tabeli VT1. Może to się wydawać oczywiste, ale świadomie tu podkreślę, że filtrować (wyszukiwać) możemy rekordy tylko takie, które są obecne w tabeli VT1.
W WHERE, dla każdego wiersza wyznaczany jest wynik logiczny zastosowanych wyrażeń (warunków). W naszym przykładzie stawiamy tylko jeden warunek. Interesują nas elementy zbioru VT1, dla których wartość kolumny Dział jest równa ciągowi znaków 'IT’.
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy
WHERE Dzial = 'IT' -- wynik VT2
GROUP BY Zespol
HAVING COUNT ( IdPrac ) > 1
ORDER BY LiczbaPracowników
Do tabeli wynikowej VT2 – czyli rezultatu przetwarzania kroku WHERE, zostaną wstawione tylko takie rekordy, dla których wynik postawionych warunków (wyrażeń) będzie TRUE.
Przyjrzyjmy się zatem, jakie wyniki logiczne naszego wyrażenia, przyjmą kolejne rekordy.
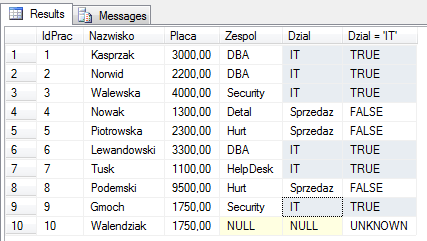
Relacyjne systemy baz danych, w tym także SQL Server, bazują na logice trójwartościowej. Jak sama nazwa wskazuje, wynik porównań może przyjmować trzy wartości – TRUE, FALSE lub UNKNOWN. TRUE oraz FALSE nie trzeba tłumaczyć – albo jest coś równe czemuś, albo nie.
Wartość UNKNKOWN, czyli nieznana została wyznaczona dla ostatniego (10) rekordu. Jest ona bezpośrednio związana z koncepcją wartości nieokreślonych – NULL. Jakiekolwiek porównanie, czy operacje z NULLem, skutkują zawsze wartością nieznaną – UNKNOWN. Szczegółowe wyjaśnienie tego zagadnienia, znajdziesz w artykule poświęconym NULL.
Podsumowując, do kolejnego kroku, zostanie przekazana tabela VT2. Zawierać będzie tylko 6 rekordów – te dla których wynik wyrażeń wynosi TRUE.
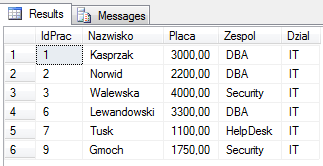
Krok 3 – GROUP BY – grupowanie rekordów
Podobnie jak filtrowanie, GROUP BY jest blokiem opcjonalnym. W tym kroku tworzone są grupy rekordów. Definicję grupy tworzą kolumny (atrybuty) grupujące, wyszczególnione w GROUP BY.
W naszym prostym przykładzie, potrzebujemy znać informacje o liczbie pracowników w ramach zespołów. Grupować będziemy po kolumnie Zespol.
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy
WHERE Dzial = 'IT'
GROUP BY Zespol -- wynik VT3
HAVING COUNT ( IdPrac ) > 1
ORDER BY LiczbaPracowników
Każdy element tabeli wejściowej, czyli wynik pochodzący z kroku WHERE – VT2, może znaleźć się tylko w jednej grupie. Utworzonych zostanie tyle grup, ile jest unikalnych wartości w kombinacjach wszystkich kolumn grupujących. W naszym przypadku utworzone zostaną 3 grupy rekordów, reprezentujące zespoły DBA, HelpDesk oraz Security :
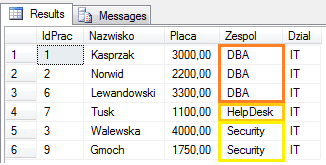
Ten krok przetwarzania jest szczególny, gdyż jego istnienie wprowadza bardzo ważne konsekwencje we wszystkich kolejnych krokach. Każda grupa, reprezentowana będzie przez jeden rekord tabeli wynikowej VT3, określony wartościami kolumn grupujących.
Sednem działania tego kroku, jest utworzone dwóch sekcji danych. Sekcji grupującej – opisanej przez kolumny, według których grupujemy oraz sekcji danych surowych. Ta z kolei, zawiera wszystkie pozostałe atrybuty (kolumny) nie występujące w klauzuli GROUP BY.
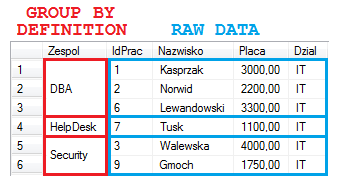
Od tego momentu, bezpośrednio odwoływać się można tylko do kolumn sekcji grupującej. To one tworzą elementy tabeli VT3 – są po prostu ich atrybutami.
Tabela VT3 zawierać będzie 3 elementy (rekordy), opisane atrybutem Zespol. Z każdym z tych rekordów będzie skojarzona sekcja danych surowych, tworzona przez wszystkie pozostałe kolumny. Do kolumn sekcji danych surowych, możemy odwoływać się w kolejnych krokach, tylko poprzez funkcje agregujące – np. COUNT().
Jest to całkiem logiczne. Zastanów się, jaką wartość kolumny Nazwisko, silnik bazodanowy miałby zwrócić w reprezentacji relacyjnej dla rekordu grupy DBA. Pierwsze? Ostatnie? A może losowe? Nic z tych rzeczy. SQL bazuje na matematycznej teorii zbiorów i nie ma w niej miejsca na przypadek. Wszystko musi odbywać się wedle ściśle określonych zasad.
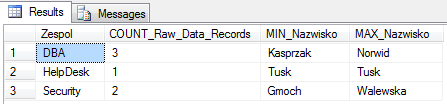
W wyniku działania GROUP BY, otrzymamy tabelę VT3 zawierającą 3 rekordy. Każdy z nich, reprezentuje grupę. Z każdą z grup, skojarzona jest sekcja surowa. Celem lepszego zobrazowania, poniżej przedstawiam zawartość tabeli VT3. Dodatkowe trzy kolumny, pokazują wynik działania funkcji agregujących.
COUNT(idPrac) – zlicza wystąpienia wartości idPrac, wszystkich rekordów w ramach sekcji danych surowych. MAX i MIN zwracają największą i najmniejszą wartość w kolumnie Nazwisko.
SELECT Zespol , COUNT( IdPrac ) as COUNT_Raw_Data_Records,
MIN( Nazwisko ) MIN_Nazwisko, MAX( Nazwisko ) MAX_Nazwisko
FROM dbo.Pracownicy
WHERE Dzial='IT'
GROUP BY Zespol
Krok 4 – HAVING – filtrowanie grup
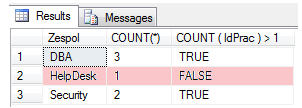
HAVING jest bezpośrednio związany z operacjami na grupach. Jest więc logicznym, że ten krok przetwarzania nastąpi po etapie tworzenia grup czyli po GROUP BY. Ogólne zasady filtrowania są identyczne jak w WHERE. Do tabeli wynikowej VT4, trafią tylko takie rekordy (grupy), dla których wynik wyrażeń logicznych będzie TRUE.
Budując warunki filtracji grup rekordów, trzeba pamiętać o konsekwencji grupowania. Bezpośrednio odwoływać możemy się tylko do kolumn sekcji grupującej, do pozostałych za pośrednictwem funkcji agregujących.
W naszym scenariuszu, interesuje nas liczba elementów w sekcji danych surowych w obrębie grupy. Czyli z ilu pracowników składa się każda grupa. Wynik logiczny określony w HAVING, spełniają dwa rekordy i tylko te dwie grupy znajdą się w tabeli wynikowej VT4.
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy
WHERE Dzial = 'IT'
GROUP BY Zespol
HAVING COUNT ( IdPrac ) > 1 -- wynik VT4
ORDER BY LiczbaPracowników
Krok 5 – SELECT – selekcja pionowa i kształtowanie wyniku
SELECT odpowiada za ostateczny kształt zbioru wynikowego czyli prezentowanie wyników. Możemy dokonać wyboru interesujących nas kolumn (selekcja pionowa), przekształceń (np. dodać do siebie wartości dwóch kolumn) czy wywoływać funkcje skalarne.
Pełne możliwości tego kroku opisuje w rozdziale poświęconym SELECT. Warto wspomnieć o dwóch dodatkowych operatorach, które mogą się w SELECT pojawić. DISTINCT – czyli usuwanie duplikatów oraz TOP – ograniczenie wyników.
Z punktu widzenia kolejności wykonywanych kroków, najpierw wykonywane są wszelkie działania mające na celu ostateczne określenie wartości kolumn (np. złączenia stringów czy obliczenia matematyczne). Następnie, jeśli jest stosowane polecenie DISTINCT – usuwane są wszystkie duplikaty. Polecenie TOP – wykonywane jest na samym końcu przetwarzania kwerendy, czyli po sortowaniu.
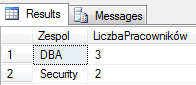
Wynik działania naszej kwerendy – kroku SELECT – czyli zawartość VT5 będzie następująca :
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników -- wynik VT5
FROM dbo.Pracownicy
WHERE Dzial = 'IT'
GROUP BY Zespol
HAVING COUNT ( IdPrac ) > 1
ORDER BY LiczbaPracowników
Jeśli nadajesz tutaj aliasy (alternatywne nazwy kolumn), widoczne one będą tylko w ostatnim kroku – ORDER BY. Przecież te nazwy, to nic innego jak atrybuty tabeli VT5 – czyli produktu przetwarzania SELECT. Taki zapis będzie więc nieprawidłowy :
-- alias LiczbaPracownikow, znany będzie dopiero w kroku
-- następujących po SELECT czyli w ORDER BY
SELECT z.Nazwa as Zespol , COUNT(*) as LiczbaPracownikow, LiczbaPracownikow + 1
......
Krok 6 : ORDER BY – sortowanie wyniku
Sortujemy oczywiście efekt kroku SELECT, czyli tabelę VT5. Tylko tutaj w kwerendzie, możemy odwoływać się do zastosowanych w SELECT aliasów nazw kolumn.
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy
WHERE Dzial = 'IT'
GROUP BY Zespol
HAVING COUNT ( IdPrac ) > 1
ORDER BY LiczbaPracowników
W tym kroku otrzymujemy finalny rezultat przetwarzania kwerendy – posortowany w określony sposób zbiór elementów (domyślnie rosnąco ASCending).
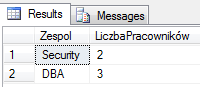
Wyjątkiem jest stosowanie w SELECT polecenia TOP – ograniczające ilość zwracanych rekordów. Wtedy, wykonywana jest dodatkowa filtracja ze względu na istnienie tego polecenia.
Jednym z ciekawszych możliwości ORDER BY, jest wprowadzona w dialekt T-SQL (SQL Server 2012) możliwość stronnicowania wyników – opisuję to w artykule poświęconym ORDER BY.
Podsumowanie
W SQL Server dostępnych jest szereg rozszerzeń funkcjonalnych pisania kwerend. Na przykład elementy składniowe stosowane do tworzenia i przeszukiwania dokumentów XML (FOR XML, XQuery, OPENXML) czy tabel przestawnych (PIVOT, UNPIVOT).
Nie stanowią one jednak fundamentu logiki przetwarzania zapytań.
Opisany powyżej proces, ma zastosowanie do wszystkich typowych zapytań. Oczywiście można je mocno skomplikować, stosując np. zapytania skorelowane czy podzapytania. Jednak ich przetwarzanie i tak odbywa się zgodnie z opisanym powyżej sposobem.
Kolejnym krokiem w poznawaniu SQL, jest wiedza na temat wymienionych tu bloków funkcjonalnych oraz zasad łączenia tabel. Opisuję te zagadnienia w kolejnych rozdziałach tego kursu.
Świetnie wytłumaczone. Choć trochę się przeraziłam stwierdzeniem, że tak wygląda łatwe zapytanie na początek 😉 Dzięki Tobie okazało się naprawdę łatwe! Ani na wykładzie, ani na laboratoriach z BD nie miałam tak jasno pokazane o co w tym chodzi. A wystarczyło odnieść się do kolejności przetwarzania…
Bardzo się cieszę, że jest to pomocne. Wszystko jest trudne dopóki nie stanie się proste 😉 pozdrawiam !
Witam,
Mam Pytanko.
Powiedzmy że będę chciał pogrupować rekordy po polu np. Nazwisko oraz także odfiltrować po tym polu (np. po jego fragmencie). To czy lepiej będzie filtrować w klauzuli WHERE czy w klauzuli HAVING?
W podstawowym scenariuszu – efekt będzie taki sam, warto zerknąć na plan wykonnia – filtracja będzie przerzucona na operatory dostępu do danych czyli skanowanie lub przeszukiwanie indeksu. Generalnie jeśli myślimy o filtorwaniu rekordów = Where, jeśli myślimy o filtrowaniu grup = having.
Świetny kurs dla początkujących, bardzo ustrukturyzowany, dzięki!
Trochę walczyłam, bo pojawiał się u mnie błąd w miejscu
WHERE Dział = 'IT’, okazało się, że w MS SQL Server trzeba wpisać 'like’ zamiast '=’ i wtedy jest ok 🙂
mam nadzieję, że wiesz jaka jest różnica 😉
Strasznie dla mnie nie intuicyjne było, że na początku w momencie gdzie piszę co chce wyciągnąć, mam podawać co zrobić z wyciągniętą daną. Dziękuję za rozjaśnienie tematu. Więcej takich nauczycieli.
Zdecydowanie się zgadzam z Krzysztofem, Markiem i Aleksandrem.
Bardzo przydatny artykuł, który wyjaśnia sytuację i przyczyny problemów – dziękuję Jakub! Faktycznie, też nie od razu załapałam, że nie można używać aliasów z SELECT np. w HAVING – więc zdecydowanie lepiej przeczytać najpierw całość (lub po prostu zwracać uwagę na szczegóły podanego tekstu poprawnej kwerendy…). I niestety ta składnia SQL’a dla mnie też jest dość niejasna – jak na początku coś definiuję, to naturalnie zakładam, że mogę z tego od razu korzystać – a tak nie jest, bo „początek” nie jest wykonywany na początku….
Natomiast nadal mam problem z ostatnim etapem – ORDER BY. Na razie piszę kwerendy SQL w Accesie (365). U mnie nawet w ORDER BY nie mogę użyć aliasu LiczbaPracownikow, bo jak użyję, to pojawia się okienko „Enter Parameter Value” i muszę recznie wpisać Count( IdPrac ), i wtedy kwerenda daje poprawny wynik. Dlaczego tak się dzieje? Czy można to jakoś poprawić (i jak??), czy też może w Accessie zawsze trzeba wpisywać pełne wyrażenia, a nie aliasy? Będę bardzo wdzięczna za pomoc 🙂
Access używa uproszczonego dialektu SQL i ma okrojone możliwości w porównaniu z T-SQL. Szczerze przyznam, że nie pamiętam kiedy ostatnio używałem Accessa, więc niestety nie pomogę 🙂 pozdrowienia
Bardzo dobry opis poszczególnych bloków logicznych, konkretne wyjaśnienia, obrazowe przykłady.
Napotkałem jednak pewien problem, mianowicie – chcąc uniknąć uczenia się „na sucho” i już na tym etapie wywoływać te same efekty, które opisano w kursie, długie minuty spędziłem na dochodzeniu, dlaczego nie jestem w stanie uzyskać wyników przedstawionych w załączonych screenach (VT1 itd).
Koniec końców, polecenie:
SELECT Zespol , COUNT( IdPrac ) AS LiczbaPracowników
FROM dbo.Pracownicy — wynik VT1
Nie zwróci wszystkich kolumn, a jedynie Zespol i Liczbe Pracowników, a screen VT1 zawiera całość.
Próba wpisania: SELECT * From dbo.Pracownicy
z kolei wywołuje problemy przy przejściu do GROUP BY, które są co prawda opisane bardzo konkretnie („Do kolumn sekcji danych surowych, możemy odwoływać się w kolejnych krokach, tylko poprzez funkcje agregujące – np. COUNT().”),
jednak dopiero pod koniec danego bloku i próby symulowania jego działania na bieżąco trafiają na ścianę w postaci błędów.
także taka drobna uwaga z mojej strony dla nowych ludzi czytających ten kurs – w przypadku tego konkretnego rozdziału, warto najpierw przeczytać całośc, a później dopiero odtwarzać samemu.
Podobnie jak jeden z moich przedmówców, pochwalę niniejszy rozdział za przedstawienie niezgodności pomiędzy samą konstrukcją kwerendy, a kolejnością operacji wykonywanych przez silnik bazodanowy. Jest to moim zdaniem jedna z największych słabości SQL, którego kwerendy miały rzekomo odwoływać się swoją konstrukcją do języka naturalnego. A już sam język naturalny, w swoich założeniach raczej nakazuje stwierdzenie: „Z tabeli 'A’ WYBIERZ kolumny 1,2,3”. Nie rozumiem dlaczego ta niekonsekwencja nie została przez lata naprawiona. Nie rozumiem również, dlaczego wciąż niedopuszczalnym jest konstruowanie zapytań zgodnie z kolejnością wykonywania operacji. Jest to uciążliwe zwłaszcza dla początkujących użytkowników, którzy np. nie rozumieją dlaczego nadane w SELECT aliasy kolumn, nie są rozpoznawane w WHERE, a można nimi operować w ORDER BY. Jeszcze raz – wielki plus za naświetlenie tematu. Rzecz zwykle pomijana, a bardzo istotna.
Jestem nowy w temacie, ale te artykuly bardzo mi pomagaja. Swietna robota!
PS. Sry ta brak znakow wlasnych, nie mam polskiej klawaitury
Ja również przyłączę się do podziękowań za naprawdę świetny artykuł. Zazwyczaj zabierając się za czytanie różnych poradników i objaśnień na blogach skupiam się na treści merytorycznej, ale wszystko zostawiam bez komentarza. Tutaj nie mogłam – naprawdę bardzo dobra robota. Bardzo ładnie wszystko usystematyzowane i przedstawione na prostym przykładzie.
To jest bardzo dobry rozdział, który w skrótowy sposób przedstawia podstawową, ale kompletną składnię zapytania do bazy danych. Takiego rozdziału zwykle brakuje w podręcznikach do nauki SQL-a, gdyż autorzy od razu rozbijają zapytanie na pojedyncze klauzule omawiane w osobnych rozdziałach. Przez to czytelnik skupia się na szczegółach, i traci ogląd całości. A potrzebny jest właśnie taki wprowadzający, syntetyczny opis składni zapytania, jak ten powyższy. Drugi plus wpisu, to pokazanie że logiczna kolejność wykonania zapytania jest inna niż wynikająca z zapisu – chodzi mi o „miejsce” wykonania klauzuli SELECT. To też jest niezbyt często omawiane w podręcznikach.
Dzięki za pozytywny feedback 🙂
A jak się ma do kolejności JOIN?
Dziękuję za świetny artykuł
Super wytłumaczone.