Ostatnim krokiem logicznego przetwarzania zapytań jest operacja sortowania, którą możemy określić właśnie w ORDER BY.
(5) SELECT
(1) FROM
(2) WHERE
(3) GROUP BY
(4) HAVING
(6) ORDER BY
W tym miejscu, silnik relacyjny, ma już w pełni uformowany zbiór wynikowy. Pozostało tylko posortowanie go zgodnie z określonymi w ORDER BY wymogami.
Po czym możemy sortować
Zazwyczaj sortujemy zbiór wynikowy według określonych atrybutów (kolumn) elementów, znajdujących się w klauzuli SELECT. Ponieważ jest to kolejny krok po SELECT, silnik relacyjny wykonujący zapytaniem zna także nazwy aliasów które tam mogliśmy użyć.
Możemy zatem odwoływać się zarówno do nazw kolumn, tabel (zbiorów) z których pobieramy dane (wyszczególnione w klauzuli FROM) jak również aliasów które nadaliśmy w SELECT.
USE AdventureWorks2008
GO
-- sortowanie po aliasie i nazwie kolumny źródłowej
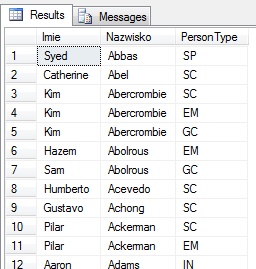
select FirstName as Imie,
LastName as Nazwisko,
PersonType
from Person.Person
order by Nazwisko, FirstName
Kolejną możliwością jest sortowanie po numerach kolumn tabeli wynikowej. Poniższy zapis jest tożsamy z poprzednim przykładem – zwróci identyczny wynik.
select FirstName as Imie,
LastName as Nazwisko,
PersonType
from Person.Person
order by 2, 1
Nie jest to jednak zalecany sposób z uwagi na możliwość zmiany kolejności kolumn, zatem ich numerów w zbiorze wynikowym. Wystarczy że dopiszemy dodatkową kolumnę, lub zamienimy kolejność w SELECT i wynik sortowania będzie niezgodny z pierwotnym zamierzeniem. Sposób wygodny, ale polecany tylko do szybkich kwerend adhoc, w których nie chce nam się przepisywać nazw kolumn.
W standardzie ANSI SQL:1999 wprowadzono możliwość sortowania nie tylko po kolumnach, które określamy w SELECT. Możemy sortować po dowolnych atrybutach tabel (zbiorów) do których odwołujemy się w klauzuli FROM zapytania, pod warunkiem, że nie używamy DISTINCTa.
-- zauważ, że BusinessEntityID nie występuje w SELECT
select FirstName as Imie,
LastName as Nazwisko,
PersonType
from Person.Person
order by Nazwisko, FirstName, BusinessEntityID
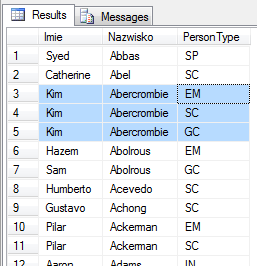
Zauważ, że kolejność rekordów dla osób nazywających się Kim Abercombie, różni się od poprzedniego przykładu – widać to po kolumnie PersonType. Jest zgodna z sortowaniem wewnątrz tej grupy po BusinessEntityID, której w tym zapytaniu nie wyciągam w SELECT.
Pewnym wyjątkiem od tej zasady (oprócz sytuacji z DISINCT), są zapytania w których grupujemy dane. W kwerendach grupujących w wyrażeniu SELECT jak i ORDER BY, możemy odwoływać się tylko do kolumn lub ich aliasów, tworzących grupy oraz do pozostałych kolumn ale tylko poprzez funkcje agregujące. Nie można odwoływać się bezpośrednio do części surowej (RAW data) w ramach grupy – jest to szerzej wyjaśnione w rozdziale tego kursu, dotyczącym grupowania danych.
Podsumowując, możemy sortować po
- dowolnych kolumnach tabel źródłowych użytych we FROM (pod warunkiem że nie korzystamy z DISTINCT lub w przypadku grupowania – sortujemy po kolumnach tworzących grupy)
- wyrażeniach tworzących nowe kolumny zbioru wynikowego
- aliasach użytych w SELECT
- numerach kolumn zbioru wynikowego
Sortowanie po wartościach losowych
Składnia klauzuli ORDER BY pozwala nadać losowości elementom zbioru. Trochę to może być mylące, ponieważ by definition, każdy zbiór, który nie jest jawnie posortowany jest losowy. Jest to podstawa rozważań teorii zbiorów i tak powinniśmy w ogólności do tematu podchodzić. Jednak owa losowość – jest zawsze w pewien sposób uwarunkowana np. fizycznym składowaniem rekordów (lub sposobem przechowywania danych w pamięci podręcznej). Pamiętajmy, że jeśli tabela posiada indeks klastrowy – jej elementy będą już zawsze fizycznie posortowane według tego indeksu.
Dlatego czasem potrzebujemy nadać dodatkowej losowości np. nowym produktom wyświetlanym na stronie głównej sklepu (żeby przy każdej wizycie był to jakiś losowy podzbiór).
Nadanie losowości elementom w zbiorze możemy wykonać np. z zastosowaniem funkcji NEWID(). Obydwa poniższe zapytania są równoważne w sensie wydajnościowym (plany wykonania będą identyczne) i obrazują one skrót, jaki możemy wykonać sortując wyniki po wartości losowej :
select NEWID() as RandomValue ,FirstName as Imie,
LastName as Nazwisko,
PersonType
from Person.Person
order by 1
-- obydwa zapytania zwracają ten sam rezultat. W drugim sortujemy po NEWID()
select FirstName as Imie,
LastName as Nazwisko,
PersonType
from Person.Person
order by NEWID()
Sposób sortowania
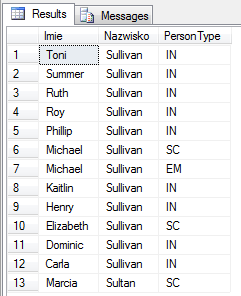
Operacja sortowania odbywa się zawsze w określony sposób – malejąco lub rosnąco. Możemy sortować po jednej lub kilku kolumnach. Operacja taka wykonywana jest zawsze od lewej do prawej. W naszym przypadku było to najpierw sortowanie po Nazwisku, następnie w ramach podzbiorów (gdzie wartość nazwiska jest taka sama) – sortowanie po kolumnie FirstName.
Domyślnie, sortowanie odbywa się w sposób rosnący (ASC ang. ascending). Dla każdej z kolumn możemy określić właściwy kierunek sortowania rekordów :
- rosnąco ASC ascending – jest to domyślny sposób i nie trzeba go jawnie określać.
- malejąco DESC descending – konieczne jest jawne określenie przy atrybucie, po którym chcemy w ten sposób sortować.
-- sortujemy najpierw po nazwisku (rosnąco), następnie po imieniu (malejąco)
select FirstName as Imie,
LastName as Nazwisko,
PersonType
from Person.Person
where LastName like 'SUL%'
order by Nazwisko, FirstName DESC
COLLATION – czyli sposób porównania wartości
Każde sortowanie sprowadza się do wykonania operacji porównania wartości. Porównywanie dwóch liczb jest zawsze jednoznaczne – matematyka nie daje nam w tej materii żadnej interpretacji. Albo coś jest większe, równe ew. mniejsze.
Inaczej sprawa ma się z wartościami tekstowymi – stringami. Istnieją przecież różne alfabety i dialekty, w których panują różne reguły. SQL Server dostarcza możliwości ustawienia reguł porównywania wartości tekstowych na różnych poziomach – np. bazy danych, tabeli czy nawet konkretnej kolumny.
W skryptach, zapytaniach SQL, wszędzie tam gdzie wykonujemy operacje porównywania wartości znakowych, możemy jawnie określić sposób w jaki chcemy to czynić. Do tego celu stosujemy słowo kluczowe COLLATE wraz z nazwą reguły według której będą wykonywane porównania.
Porównywanie wartości tekstowych sprowadza się do zasad ogólnych panujących w danym języku (alfabecie) – a także do określenia w jaki sposób traktowane będą małe / wielkie litery CS lub CI (case sensitivity) oraz czy będziemy rozróżnili znaki akcentowane występujące w niektórych językach AS / AI (accent sensitivity). Istnieją jeszcze dwie inne, ale rzadko stosowane w praktyce własności – KS / KI (kana sensitivity) dotyczy tylko języka japońskiego oraz WS / WI (width sensitivity) – porównywanie tych samych znaków kodowanych na jednym lub dwóch bajtach (UNICODE).
Funkcja systemowa fn_helpcollations(),pokaże nam informacje o wszystkich dostępnych sposobach porównywania (collations) ciągów znakowych.
SELECT Name, Description FROM fn_helpcollations()
where name like '%pol%'
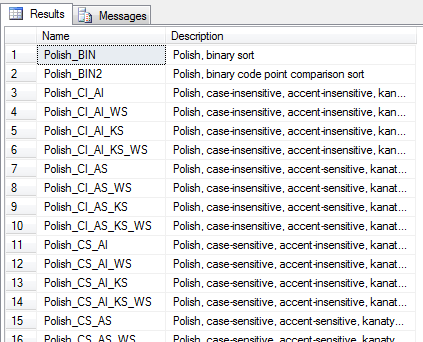
Sprawdźmy zatem wynik porównywania stringów na przykładzie zawierającym polskie znaki. W tym celu posłużymy stwórzmy tabelkę testową :
create table dbo.collate_test
(
id int identity(1,1),
opis nvarchar(10)
)
insert into dbo.collate_test(opis)
values (N'Pączek'), (N'Paczek'), (N'pączek'),
(N'paczek'), (N'paCzek'), (N'PACZEK'), (N'PĄCZEK')
Nowo utworzona tabela posiada collation dziedziczone po ustawieniach bazy. Aby sprawdzić jakie faktycznie ma collation, zerknijmy do jej definicji (poprzez widok systemowy sys.columns) :
-- wynik zależny od ustawień bazy danych w której utworzyliśmy tabelę
SELECT c.name, c.collation_name
FROM sys.columns c
where OBJECT_ID = OBJECT_ID('dbo.collate_test')
and c.name = 'opis'
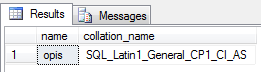
Przykład zastosowania COLLATION – polski alfabet, z uwzględnieniem małych i wielkich liter (a<A) oraz bez wrażliwości na akcent (w polskim języku i tak nie ma znaczenia).
Sortowanie ze wskazanym collation :
select * from collate_test
order by opis collate Polish_CS_AI
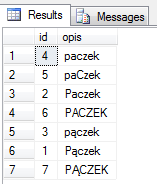
Zauważ, że pomimo wybrania kolacji z accent insensitive, wciąż są rozróżniane polskie znaczki (w sortowaniu a < ą). Nadal działamy w ramach polskiego alfabetu – litery ą, ę itd. nie są akcentami tylko są regularnymi znakami, stąd ustawienia AI/AS nie ma znaczenia. Jeśli chcesz spłaszczyć polski język – pozbyć się ogonków, trzeba użyć specjalnej kolacji Azerskiej, która jest idealna do tego zadania :
select * from collate_test
order by opis collate Azeri_Cyrillic_90_CI_AI
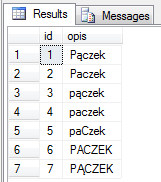
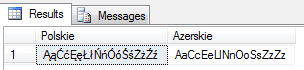
Wszystkie rekordy traktowane są płasko jako ‘paczek’ – tak więc zwrócone są w kolejności odpowiadającej fizycznemu zapisowi w tabeli (widać to po ID).
Sprawdźmy szerzej, co wyprawia collation azerskie z polskim alfabetem :
declare @alfabet varchar(100) = 'ĄąĆćĘꣳŃńÓ󌜯żŹź'
select @alfabet as Polskie,
@alfabet COLLATE Azeri_Cyrillic_90_CI_AI as Azerskie
Rozszerzone możliwości ORDER BY
Implementacja ORDER BY w T-SQL do wersji 10.5 (SQL Server 2008R2), obejmuje w zasadzie tylko określenie kolejności w jakiej mają być posortowane kolumny + sposób porównywania (collation). W SQL Server 2012 klauzula ta jest rozszerzona o obsługę stronnicowania wyników – operatory OFFSET i FETCH. W celach demonstracyjnych użyłem funkcji ROW_NUMBER do ponumerowanie rekordów, aby pokazać, które faktycznie ze zbioru wynikowe są zwracane.
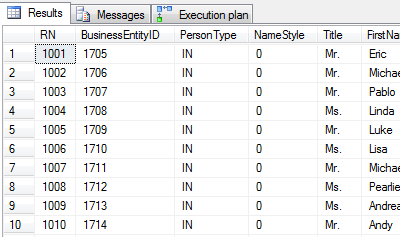
OFFSET – czyli przesunięcie o n rekordów – zwraca zbiór wynikowy z pominięciem pierwszych n wierszy :
-- zwracamy wiersze, startując od pozycji 1001 (1000 pierwszych pomijamy zgodnie z zastosowanym
-- sposobem sortowania - po RN)
select ROW_NUMBER() OVER(order by BusinessEntityId) as RN, *
from [Person].[Person]
ORDER BY RN OFFSET 1000 ROWS
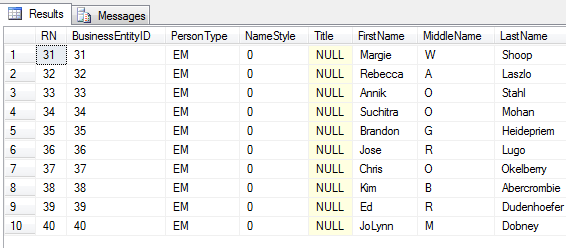
OFFSET + FETCH – czyli stronnicowanie wyniku. Podajemy ile rekordów pomijamy za pomocą OFFSET a w FETCH określamy rozmiar strony. Chcemy np. wyświetlić czwartą stronę wyników, w ramach której pokazujemy 10 rekordów :
select ROW_NUMBER() OVER(order by BusinessEntityId) as RN, * from [Person].[Person]
ORDER BY RN OFFSET 30 ROWS
--FETCH FIRST 10 ROWS ONLY -– FIRST/NEXT oraz ROW/ROWS
-- są synonimami zgodnymi ze standardem ANSI
-- możemy je stosować wymiennie
FETCH NEXT 10 ROWS ONLY
Na wstępie chciałabym podziękować za kurs, jestem bardzo początkująca jeśli chodzi o bazy danych i SQL.
Mam pytanie związane z tym przykładem:
select ROW_NUMBER() OVER(order by BusinessEntityId) as RN, *
from [Person].[Person]
ORDER BY RN OFFSET 1000 ROWS
A mianowicie, co dokładnie oznacza słowo OVER, czy jest to jakaś część funkcji ROW_NUMBER?
Funkcja OVER jest opisana tutaj http://www.sqlpedia.pl/mozliwosci-funkcji-okna-over/ ale jest to zagadnienie dosyć zaawansowane, dlatego proponuję abyś na razie opuściła i je, i ten przykład. Lepiej dobrze zrozumieć samo OFFSET i FETCH. Najprostsze wytłumaczenie to:
SELECT kolumna1, kolumna2
FROM jakas_tabela
ORDER BY kolumna2
OFFSET 3 ROWS
FETCH NEXT 5 ROWS ONLY;
Powyższe polecenie powoduje pobranie danych z dwóch kolumn i posortowanie wyniku, w ten sposób, że zostają odrzucone trzy pierwsze wiersze, a zostanie wyświetlonych pięć następnych. I załatwione 🙂
Witam,
mam problem z ostatnimi operatorami 'OFFSET’ oraz 'FETCH’
błąd składni i niepoprawne użycie opcji 'NEXT’ prawdopodobnie wynikające z pierwszego błędu składni 'OFFSET’
„Incorrect syntax near 'OFFSET’.
Invalid usage of the option NEXT in the FETCH statement.”
Wie Pan co może być przyczyną tego błędu?
Dodam, że używam MS SQL Managment Studio 2012 i przykład kopiowałem aby sprawdzić, że nie popełniłem błędu przy przepisywaniu.
Pozdrawiam i z góry dziękuje za odpowiedź
Przykład jest poprawny w wersji SQL Server od 2012 wzwyż (baza AdventureWorks2012) wystarczy copy & paste. Management Studio 2012 to nie wszystko 😉 Sprawdź czy na pewno Twoja wersja serwera to min. 11.
i czy przypadkiem nie masz jakiś literówek 🙂 Pozdr !