W relacyjnych systemach baz danych, elementy (wiersze) przechowywane w tabelach, mogą być opisywane przez atrybuty (kolumny) określone jak i nieokreślone, czyli poprostu zawierające wartości bądź nie.
Atrybut nieokreślony to taki, który nie ma wartości. „Wartość” taką, oznaczamy jako NULL (w teorii baz danych NULL oznaczany jest małą grecką literą – omega ω ). Zazwyczaj będzie to atrybut opcjonalny, nieobowiązkowy lub po prostu nie określony.
Ten sposób postrzegania rzeczywistości i modelowania jej w bazach, od lat dostarcza wielu dyskusji z uwagi na potencjalne nieścisłości, które z tego tytułu się pojawiają. Artykuł ten, nie ma na celu odnoszenia się do dyskutowania problemów relacyjnych. Przedstawiam tutaj wszystkie fakty istnienia NULL w SQL Server od strony praktycznej, związanej z pisaniem zapytań.
Logika Trójwartościowa
Z uwagi na to, że nie wszystkie kolumny muszą posiadać określone wartości (dane), wprowadzono pojęcie logiki trójwartościowe. Zgodnie z nią, rezultat porównania dwóch wartości, może przyjmować jeden z 3 stanów :
- TRUE – gdy wartości są równe
- FALSE – gdy się różnią
- UNKNOWN – wynik porównania nie jest znany
Dwóch pierwszych nie ma co omawiać, bo z pewnością były dokładnie wytłumaczone w pierwszych latach szkoły podstawowej. Ciekawszym stanem jest wynik UNKNOWN – który jest związany właśnie z wartością NULL – czyli wartością nieznaną / nieokreśloną.
Wartość NULL definiuje atrybut lub logiczny wynik porównania jako nieokreślony, niezdefiniowany. Może występować w rekordach (elementach zbioru), w kolumnach, którym nie zostały określone wartości.
NULL nie jest równy 0, ani też nie jest to wartość pusta w sensie pustego stringu ”. Lepszym porównaniem byłaby tu próżnia – coś co nic w sobie nie zawiera.
Praca z NULL
Warunki logiczne
Wartości nieokreślonej nie możemy sensownie porównać z czymkolwiek gdyż wynikiem takiego porównania będzie również wartość nieokreślona czyli UNKNOWN. Trudno odnieść się do czegoś czego się nie zna lub czego nie ma – więc jak to porównać. A co w takim razie da porównanie dwóch wartości NULL ?
-- deklaracja zmiennych, bez przypisania wartości,
-- każdy z nich przechowuje wartość nieznaną NULL
declare @wartosc_a int,@wartosc_b int
select CASE WHEN @wartosc_a = @wartosc_b THEN 'EQUAL'
WHEN NOT (@wartosc_a = @wartosc_b ) then 'NOT EQUAL'
WHEN @wartosc_a != @wartosc_b then 'VARIOUS'
ELSE 'UNKNOWN' END as NULLsComaprisionResult
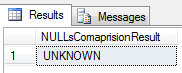
Wynik porównania dwóch wartości NULL to także wartość nieznana. Nie jest ani większa, ani równa. Podobnie, jeśli byśmy chcieli porównać wartość znaną, z czymś czego nie znamy – wynik zawszę będzie UNKNOWN.
Znajomość NULL skutkuje w wielu miejscach związanych z pisaniem zapytań.
W warunkach filtracji, obojętnie czy będzie to filtracja w WHERE, we FROM – jako warunek złączenia czy w HAVING, zwracane są tylko te wiersze, dla których wynik porównania jest spełniony – czyli zwraca wartość TRUE.
Ponieważ porównanie czegokolwiek z NULL, zwraca wartość UNKNOWN, dlatego w interpretacji filtrowania rekordów, wiersze dla których taki wynik zostanie wyznaczony – będą odrzucone.
Jeśli spróbowalibyśmy odnieść się do wartości NULL w ten sposób :
USE Northwind
GO
-- Pomimo istnienia rekordów dla których Region nie jest nullem,
-- tak skonstruowane zapytanie nic nie zwróci
select * from dbo.Employees
where Region <> null
Zapytanie nie zwróci żadnego rekordu :
(0 row(s) affected)
Pomimo że istnieją rekordy, dla których wartość kolumny Region nie jest NULLem, ale żadne z takich porównań nie zwróci TRUE (chyba że mamy ustawiony brak zgodności ze standardem ANSI – opisuje to w dalszej części artykułu). Wynik jakichkolwiek porównań z NULL to zawsze wartość nieznana UNKNOWN, choć czasem mylnie interpretowany jako FALSE. Dlatego jeśli zależy nam na porównaniach odnoszących się do NULL musimy jawnie używać specjalnie do tego celu stworzonego zapisu czyli IS NULL lub IS NOT NULL :
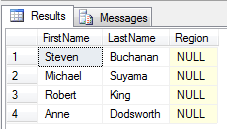
-- poprawne porównywanie do NULL
select LastName, FirstName, Region from Employees
where Region IS NOT NULL
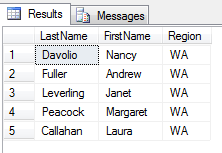
Z tego samego powodu, zapytanie w którym użyjemy w warunku WHERE, operatora IN – tłumaczonego na szereg warunków logicznych OR, nie zwróci rekordów dla których kolumna wartość zawiera NULL
select LastName, FirstName, Region
from Employees
-- IN to równoważnik poniższego zapisu : Region = 'WA' or Region = NULL
where Region IN ('WA',NULL)
Wartość NULL w wyrażeniach
Wykonując jakiekolwiek działania na wartościach nieznanych, należy spodziewać się również, że i wynik będzie tak samo dokładny jak i wartości na których operujemy czyli UNKNOWN.
Zobaczmy do jakiego rezultatu doprowadzą, wszelkiego rodzaju działania z wartością nieokreśloną :
Select 100000 + NULL as wynik1,
(5000+300) * 2 - null as wynik2,
'Ala ma ' + 'kota' + null + '!' as wynik3
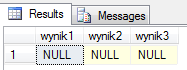
Wszystkie operacje z udziałem wartości nieznanej – dają zawsze w wyniku NULL. Niezależnie czy są wartości przechowywane jako zmienne, kolumny czy stałe – cokolwiek połączymy z NULL – da nam NULL.
Ponieważ wartości nieokreślone są często spotykane w bazach, musimy sobie jakoś z nimi radzić. Tylko w jaki sposób je traktować. Pawdopodobnie przy operacjach matematycznych, chcielibyśmy traktować NULL jak 0 natomiast w wyrażeniach łączącym stringi – interpretować jako string pusty ”. Jest to więc bardzo subiektywne, w zależności od konkretnego scenariusza. Rozpatrzmy następujący przypadek :
USE AdventureWorks2008
GO
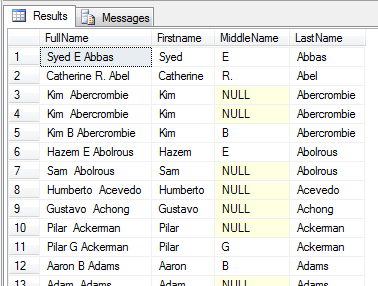
SELECT FirstName + ' ' + MiddleName + ' ' + LastName AS FullName,
Firstname, MiddleName, LastName
FROM Person.Person
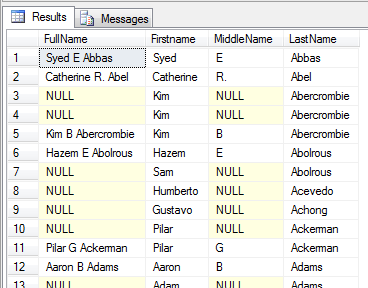
Kolumna MiddleName, zawiera wartości NULL, stąd wszędzie tam gdzie się pojawia wartość nieokreślona, wynik złączenia tekstu jest również nieokreślony.
Wpływ NULLi na określone działania możemy zniwelować za pomocą wyrażeń warunkowych CASE WHEN, podstawiając w tym przypadku wartość stringu pustego ” w miejsce NULL:
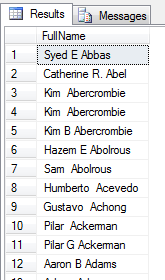
SELECT FirstName + ' ' +
CASE WHEN MiddleName is null THEN '' ELSE MiddleName END
+ ' ' + LastName AS FullName,
FirstName, MiddleName, LastName
FROM Person.Person
Sposób skuteczny, ale mało wygodny. Mamy na szczęście do dyspozycji kilka funkcji wbudowanych, które pomagają w radzeniu sobie z NULLami i upraszaczją kod SQL.
Funkcje wspierające przy pracy z NULL
ISNULL ( wartość , wartość_zastępcza ) jedna z dwóch najczęściej stosowanych i użytecznych do pracy z NULLami. Podstawia wartość wskazaną w drugim argumencie, jeśli wykryje w danej kolumnie NULL. Zastosujmy ją więc do poprzedniego przykładu, zamiast CASE WHEN :
SELECT FirstName + ' ' + ISNULL(MiddleName,'') + ' ' + LastName AS FullName
FROM Person.Person
COALESCE ( wartosc_1 , wartosc_2 … wartosc_n ) – zwraca pierwszą nie-nullową wartość z listy. Startuje od wartości podanej jako pierwsza, jeśli nie jest NULLem to ją zwraca a jeśli jest to analizuje kolejną podaną w jej definicji. Równoważnik takiego zapisu np. dla 3 argumentów :
COALESCE ( wartosc_1 , wartosc_2 , wartosc_3)
-- równoważnik z wykorzystaniem IS NULL
ISNULL ( ISNULL( wartosc_1 , wartosc_2 ), wartosc_3 )
-- z wykorzystaniem CASE WHEN
CASE WHEN wartosc_1 is not null then wartosc_1
WHEN wartosc_2 is not null then wartosc_2
WHEN wartosc_3
end
NULLIF (wartosc1, wartosc2) – porównuje dwie wartości i zwraca NULL jeśli są równe.
Jest logicznym odpowiednikiem zapisu warunkowego :
CASE WHEN wartosc1 = wartosc2 THEN NULL ELSE wartosc1 END
Logicznie uzasadnione wyjątki
Są wyjątki w implementacji logiki trójwartościowej (TRUE, FALSE, UNKNOWN), które po analizie możemy zakwalifikować do łamiących jej reguły.
Poniższe przypadki, mają na celu pokazanie kilku uzasadnionych odstępstw, aby bardziej świadomie patrzeć na obowiązujące zasady w bazach danych.
Miejsca, gdzie wynik porównania wartości NULL traktowany jest jako TRUE :
- ORDER BY – wszystkie wartości kolumny, które zawierają NULL i po której sortujemy – są traktowane jako równe – występują obok siebie.
- GROUP BY – wszystkie elementy, grupowane po atrybucie zawierającym NULL, tworzą jedną grupę, zatem również traktowane są jak równe.
- UNIQUE CONSTRAINT – w kolumnie unikalnej, gdy jest już w niej wartość NULL, przy próbie wpisania kolejnego, traktowane są jakby NULLe były sobie równe (jeden już jest, więcej nie można).
- budowanie indeksu na kolumnie zawierającej NULLe – traktuje wartości nieokreślone jak równe. Efektywność indeksu na kolumnie zawierającej nulle maleje.
Porównanie NULL z wartością znaną, czasem daje TRUE
- jeśli zdefiniujesz ograniczenie np. CHECK CONSTRAINT >0 na kolumnie przechowującej wartości liczbowe. Przy próbie wpisania wartości NULL – wynik porównania będzie spełniony tak jakby NULL faktycznie był większy od 0 (tylko liczby ujemne i 0 nie spełnią tego ograniczenia).
Standard ANSI
Sposób porówynania wartości null opisany do tej pory, jest zgodny ze standardem ANSI SQL:92. W SQL Server, dostępna jest możliwość wyłączenia tej zgodności np. na poziomie połączenia (sesji), poprzez ustawienie
SET ANSI_NULLS OFF
Szczerze mówiąc, nie spotkałem się z przypadkami w rzeczywistych systemach, gdzie korzystało by się z globalnego wyłączenia zgodności ze standardem ANSI w kontekście całej bazy. W sporadycznych sytuacjach, można łatwo zmienić sposób interpretacji porównania z null. Jeśli ustawisz ANSI_NULLS na OFF – wtedy NULL będzie traktowany jak zwykła wartość czyli wynik warunku np. NULL = NULL będzie TRUE.
--Wylaczenie zgodnosci z ansi (domyslnie jest włączone)
SET ANSI_NULLS OFF
select FirstName, LastName, Region
from Employees
where Region = NULL
Dlaczego w pierwszym przykładzie dodany jest przedostatni wiersz? Wydaje mi się że WHEN NOT (@wartosc_a = @wartosc_b ) then 'NOT EQUAL’ jest tym samym co WHEN @wartosc_a != @wartosc_b then 'VARIOUS’ i nie za bardzo rozumiem w jakiej sytuacji jest możliwe by trzecia opcja z != mogła być wykorzystana skoro when = i when not = w poprzedzających wyczerpują wszystkie opcje.
Witam.
Mam taki problem że muszę przedstawić wynik pustej tablicy – znaczy się robie status faktur i jeżeli ma null to jest = TAK jeżeli jest „0” to zamówiona no i ostatni warunek jest że jeżeli nie istnieje tablica z wynikiem to nie ma …. jak to ugryść?
Warto jeszcze wspomnieć, że funkcja AVG() pomija NULLe (pól o wartości NULL nie uwzględnia podczas obliczania średniej).
Tak, zdecydowanie warto o tym wspomnieć, wszystkie funkcje agregujące pomijają NULL (np. COUNT, MIN czy MAX) !
Chyba „nieznanych”, a nie „nie znanych” 🙂
Nurtuje mnie trochę filozoficzne pytanie: czym różnią się dwie poniższe tabele? Jedna jest pusta, bo zawiera same NULL-e, a druga też jest pusta bo nic nie zawiera. Ale wartość NULL też jest pusta, a właściwie jest brakiem jakiejkolwiek wartości, a jednak funkcja COUNT zlicza wiersze z NULL-ami. W takim razie czym różni się pustość tabeli z NULL-ami od pustości tabeli bez wartości i bez NULL-i? Czy one są tożsame, czy ta z NULL-ami jednak zawiera „coś”?
USE tempdb;
GO
CREATE TABLE dbo.#jeden (
ID int,
);
INSERT dbo.#jeden (ID) VALUES (NULL), (NULL), (NULL);
SELECT ID FROM dbo.#jeden;
SELECT count(*) FROM dbo.#jeden;
CREATE TABLE dbo.#dwa (
ID int,
);
SELECT ID FROM dbo.#dwa;
SELECT count(*) FROM dbo.#dwa;
Pierwsza tabela wcale nie jest pusta. Zawiera bardzo konkretną zawartość – trzy obiekty, których wszystkie atrybuty są nieokreślone, stąd pierwszy count(*) from #jeden da wynik 3. Oczywiście to tylko „hipotetyczne” rozważania bo takie obiekty nie nieosą żadnej informacji i nawet nie spełniają podstawowych cech aby móc z nimi cokolwiek zrobić.
Teraz rozumiem. Dziękuję za wyjaśnienie.
Takie obiekty z wartoscia null sa przydatne. Wyobraz sobie sytuacje w, ktorej masz tabele na przyklad z placami. Dla niektorych pracownikow przysluguje premia od sprzedazy. Chesz miec mozliwosc sledzenia ile wynosi srednia premia. Bez sensu jest tworzenie rekordu ktory by trzymal informacje o tym czy premia przysluguje czy nie. Zamiast tego mozesz trzymac null dla pracownikow z prawem do premii, ktorzy jej nie otrzymali, zero dla pracownikow ktorzy nie maja prawa i kwote dla pracownikow ktorzy ja otrzymali. W ten sposob masz 3 dane w jednym rekordzie.
Dzięki za fajny przykład.