Klauzula SELECT, musi znaleźć się w każdym zapytaniu. Bez niej, nie wykonamy żadnej kwerendy, bo to właśnie tutaj, określamy w jaki sposób chcemy oglądać wynik zapytania.
Pomimo że występuje zawsze jako pierwsza, jej treść jest przetwarzana jako jedna z ostatnich (jeśli nie korzystamy z sortowania zbioru wynikowego ORDER BY, będzie to faktycznie ostatni krok).
(5) SELECT
(1) FROM
(2) WHERE
(3) GROUP BY
(4) HAVING
(6) ORDER BY
Ważne jest, aby zrozumieć, że język SQL pomimo swojej ustrukturyzowanej formy, jest elastyczny. Strukturyzowany, czyli ściśle określony pod względem szyku, słów kluczowych, konstrukcji, ale dający nam swobodę w ramach tej struktury.
W tym artykule, zaprezentuję pełen zakres możliwości jakie mamy do dyspozycji w SELECT, czyli wszystko co możemy użyć pomiędzy słowami kluczowymi SELECT … FROM do kształtowania wyniku kwerendy.
Pierwszy SELECT
Każda kwerenda, jako rezultat zwraca tabelę – wirtualną (Virtual Table, VT). Zgodnie z teorią zbiorów, omawianą w rozdziale pierwszym, tabela to zbiór elementów (wierszy) opisanych przez atrybuty (kolumny).
Wiemy już, że każde zapytanie musi zawierać SELECT. Czy potrzeba czegoś więcej? Zazwyczaj odwołujemy się w kwerendach do tabel, ale nie jest to koniczne (co prawda mało sensowne na pierwszy rzut oka, ale dobrze obrazuje sedno, które chcę Ci pokazać)
select 'Hello World !' as Kolumna1
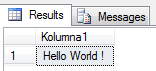
Jak widać, najprostsze z możliwych zapytań (nie odwołuje się nawet do żadnej tabeli) – zwraca nam zbiór jednoelementowy, opisany jednym atrybutem (jedna kolumna) o nazwie Kolumna1. Tego typu zbiór to nic innego jak wartość skalarna. Wartością skalarną tutaj jest zarówno wartość atrybutu (kolumny) jak i cały zbiór wynikowy. Skomplikujmy zatem zapytanie :
select 'pierwsza' as Kol1, 'druga' as Kol2, 'trzecia'
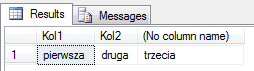
Tym razem znów otrzymaliśmy zbiór jednoelementowy, ale opisany trzema atrybutami (jeden bez nazwy). Warto zauważyć, że tu również każdy atrybut elementu opisany jest przez wartość skalarną (‘pierwsza’, ‘druga’ i ‘trzecia’).
Wyciąganie danych z tabeli
Zróbmy jednak coś bardziej użytecznego – czyli pierwszy krok do pisania sensownych zapytań – wyciągnijmy w końcu jakieś dane z tabeli.
Załóżmy na początek, że chcemy pobrać wszystko z tabeli, aby w ogóle zobaczyć co tam jest przechowywane :
USE Northwind
GO
select * from dbo.Employees
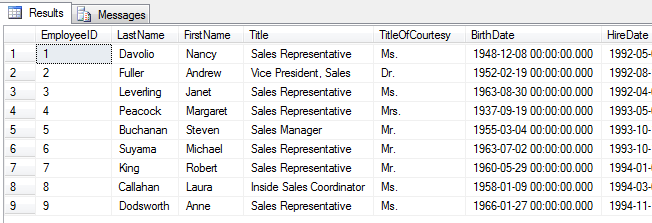
Za pomocą tej najprostszej z możliwych kwerend, otrzymamy tabelę wynikową o identycznej strukturze (te same nazwy kolumn, liczba wierszy, typy danych w kolumnach) jak tabela z której dane wyciągamy.
Na razie bez filtrowania, bez kombinacji – wyciągamy wszystko jak leci.
Tu konieczna uwaga – jeśli będziesz w ten sposób chciał odpytać tabelę, która zawierającą dużo rekordów – lepiej użyć dodatkowej klauzuli ograniczającej liczbę zwracanych wierszy czyli TOP, opisanej na końcu tego artykułu. W naszym przypadku nie ma to znaczenia, ale w systemach rzeczywistych ma i warto o tym pamiętać. Nigdy nie wyciągajmy czegoś, czego nie potrzebujemy (obciążenie serwera). Więcej na ten temat dowiesz się w rozdziale ostatnim czyli w praktycznych aspektach pisania zapytań.
Symbol ‘*’ zastępuje nazwy wszystkich kolumn z tabeli (lub tabel) do których odwołujemy się w klauzuli FROM. Stosowanie symbolu ‘*’ również nie jest dobrą praktyką – wyjaśniam to szerzej w rozdziale dotyczącym wydajności i dobrych praktyk. Na razie uznamy jednak, że do celów testowych, naukowych 🙂 będziemy go czasem używać.
Widzimy zatem, że podstawową cechą klauzuli SELECT jest określenie atrybutów elementów, zwracanych w zbiorze wynikowym kwerendy.
Każda kwerenda w wyniku zwraca zbiór elementów (tabelę VT). Czasem jest to zbiór pusty (gdy zapytanie nic nie zwraca), czasem jednoelementowy (może być opisany przez jeden lub wiele atrybutów), ale zazwyczaj zawiera szereg wierszy (elementów) i kolumn (opisanych przez wiele atrybutów). Kształt tabeli wynikowej jest określany za pomocą SELECT. To tutaj określamy w jaki sposób chcemy definiować elementy zbioru wynikowego (jakimi atrybutami czyli nazwami kolumn, będą opisane). Czy wiersze (elementy) będą opisane przez wszystkie kolumny z tabel źródłowych (symbol *) czy też tylko przez ich podzbiór.
Przeplatam tutaj świadomie definicje z teorii zbiorów (elementy, atrybuty) z nazwami obiektów stosowanych w bazach (kolumny, tabele) ponieważ zależy mi, abyś spojrzał na wynik kwerendy jak na zbiór elementów. Jeśli to dostrzeżesz, tworzenie trudniejszych zapytań będzie dla Ciebie intuicyjne.
Zatem, jeśli chcemy otrzymać zbiór elementów z tabeli źródłowej, opisany tylko poprzez kilka atrybutów (kolumn) – wymieniamy je w SELECT w postaci listy.
select LastName, FirstName from dbo.Employees
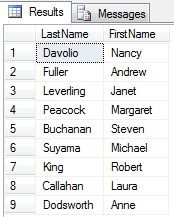
Widzimy po raz kolejny zbiór wynikowy = tabela wirtualna, tym razem dwukolumnowa czyli każdy jej element opisany jest przez dwa atrybuty.
Co możemy umieścić w SELECT
Zasada generalna
W SELECT, możemy umieścić wszystko co jest (lub będzie) wartością skalarną, jako atrybut opisujący element zbioru wynikowego (VT).
Nazwy kolumn
Przede wszystkim i najczęściej będą to nazwy kolumn, zbiorów (tabel lub widoków) z których pobieramy dane. Nawiązując znów do teorii, kolumny to atrybuty zawierające wartości skalarne, opisujące elementy zbioru – czyli jak najbardziej się nadają !
Kolejność kolumn nie ma specjalnego znaczenia – jest to jedynie właściwość odczuwalna przez użytkowników w warstwie prezentacji. Podobnie jak nazwy kolumn, które są zazwyczaj nadawane zgodnie z przyjętym standardem i niekoniecznie muszą być intuicyjne. Dlatego tutaj, w SELECT, możesz nadać im bardziej zrozumiałe nazwy czyli aliasy. Użyłem ich w pierwszym przykładzie tego artykułu, więc trochę już je znasz. Do ich tworzenia, zazwyczaj stosujemy słowo kluczowe AS ale nie jest ono obowiązkowe. Jeśli nazwa zawiera spacje, musi być ona ujęta w [] lub „” ewentualnie w apostrofy ”. Trzy najpopularniejsze sposoby tworzenia aliasów :
select LastName AS Nazwisko, FirstName Imie, LastName [Pierwsze Imię]
from dbo.Employees
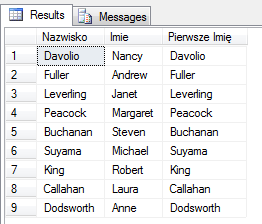
Co istotne – zgodnie z kolejnością logicznego przetwarzania zapytań – użyty alias, będzie „widoczny” we wszystkich kolejnych krokach przetwarzania zapytania, następujących po SELECT, czyli tylko w ORDER BY. Istnieje jeszcze jeden sposób na tworzenie aliasów z operatorem porównania, ale uważam że nie jest on intuicyjny i bardzo rzadko się go spotyka :
-- alias Nazwisko, utworzony dla atrybutu (kolumny) LastName z =
select Nazwisko = LastName from dbo.Employees
Wszystkie kolumny z widoku, tabeli, wyrażenia tablicowego
Wspominany już symbol * zastępuje wszystkie kolumny ze wszystkich tabel do których się odwołujemy we FROM. Jeśli jednak zależy nam na wszystkich kolumnach tylko z konkretnej tabeli, możemy działanie ograniczyć tylko do kolumn wskazanej tableli, w tym przypadku – wszystkie kolumny tabeli dbo.Products :
-- aliasy możemy stosować również do nazw tabel - więcej na ten temat,
-- przy okazji omawiania FROM
select p.*
from dbo.Products as p
inner join dbo.Categories as c on p.CategoryID = c.CategoryID
Wartości stałe
SELECT określa atrybuty elementów, które mogą być zarówno nazwami kolumn, jak i samodzielnymi zbiorami (ważne aby były wartościami skalarnymi czyli zbiorami jednoelementowymi). Możemy tu zadeklarować wartość dodatkowego atrybutu np.
select LastName, FirstName, 'Oddział 1' as Division
from dbo.Employees
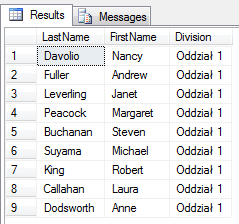
Wtedy każdy element VT dostanie ekstra atrybut o nazwie Division, o wartość 'Oddział 1′. Szczególnie przydatne, przy łączeniach zbiorów (kwerend) lub do innych przekształceń.
Funkcje skalarne
Funkcje skalarne podobnie jak w innych językach programowania, na podstawie podanych argumentów zwracają jakąś wartość skalarną. W SQL Server możemy tworzyć własne funkcje skalarne, jak również mamy do dyspozycji, szereg wbudowanych funkcji, za pomocą których możemy dokonywać różnych przekształceń na danych. Są funkcje związane z datą i czasem, funkcje tekstowe, matematyczne czy systemowe, ale zawsze jeśli mówimy o funkcjach skalarnych, mamy na myśli takie, które zwracają pojedynczy element opisany jedną wartością. Najbardziej praktyczne, wbudowane funkcje skalarne SQL opisałem w dalszej części tego kursu.
Nie ważne czy będzie to wartość tekstowa, liczbowa, binarna, XML. Skalar = jedna wartość i takie funkcje możemy użyć w SELECT. Np. użycie funkcji związanej z datą :
-- przykład zastosowania funkcji daty i czasu
-- YEAR zwraca rok z danej daty, DATEDIFF różnicę dwóch dat np. w latach
select LastName, FirstName, BirthDate,
YEAR(BirthDate) as BirthYear,
DATEDIFF(yy, BirthDate, getdate()) as Years
from dbo.Employees
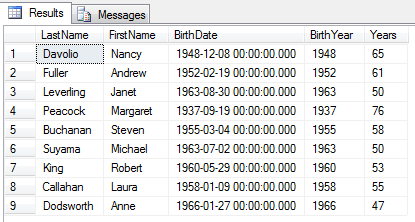
W tym przykładzie użyłem także funkcji getdate(), która wyświetla informacje o dacie i czasie systemowym.
Wyrażenia arytmetyczne, tekstowe
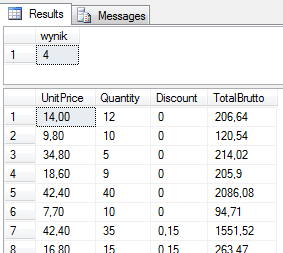
Możemy wykonywać dowolne (sensowne) operacje na danych np. skomplikowane 🙂 operacje arytmetyczne :
-- można kalkulować bez tabeli ;)
Select 2+2 as wynik
-- Przydatniejsze są obliczenia na wartościach z kolumn
-- funkcja ROUND zaokrągla wynik do n miejsc po przecinku
select UnitPrice, Quantity, Discount,
Round((UnitPrice*Quantity*(1-Discount))*1.23 , 2) as TotalBrutto
from dbo.[Order Details]
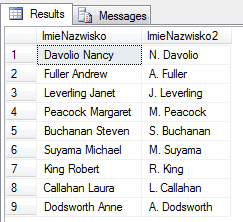
Wyrażenia tekstowe np. konkatenancja stringów czyli po ludzku – złączenie tekstów
select LastName + ' ' + FirstName as ImieNazwisko,
LEFT(FirstName,1) + '. ' + LastName as ImieNazwisko2
from dbo.Employees
Dlaczego podkreślam, że można tu wykonywać dowolne SENSOWNE operacje na danych. Otóż, wszystko co chcemy zrobić, musi mieć jednoznaczny i przewidywalny rezultat.
Jeśli wykonujemy operacje arytmetyczne, to powinny to być operacje na liczbach. Jeśli dodajesz teksty, powinny to być teksty itp. Itd. Jest to związane z silnym typizowaniem danych w SQL co pozwala zapewnić danym spójność.
Wyrażenia warunkowe
Język SQL, nie tylko służy do pisania kwerend, ale także za jego pomocą możemy tworzyć pewną logikę programistyczną. Czasem całkiem skomplikowaną. T-SQL oferuje szereg komend sterujących przepływem wykonywania skryptów, polecenia warunkowe, obsługi błędów, pętle.
Jedyną w zasadzie komendą z tej grupy, którą możemy stosować w kwerendach to konstrukcja warunkowa – CASE WHEN, pozwalająca definiowanie wartości atrybutu w oparciu o warunek (lub warunki) i na tej podstawie wyświetlanie odpowiedniej wartości.
Ogólna struktura CASE WHEN
CASE WHEN <warunek1> THEN <jeśli spełniony to wartość 1>
<opcjonalnie kolejne warunki> WHEN <warunekN> THEN <jeśli spełniony to wartość n>
<opcjonalnie else> ELSE <jeśli żaden z warunków nie spełniony to wartość else> END
W tej konstrukcji obowiązkowe jest zdefiniowanie przynajmniej jednego warunku. Jeśli nie określimy wyrażenia ELSE, wszystko co nie spełni postawionego warunku (lub warunków) dostanie wartość nieokreśloną czyli NULL. Najlepiej zobrazować to na przykładzie :
Use AdventureWorks2008
GO
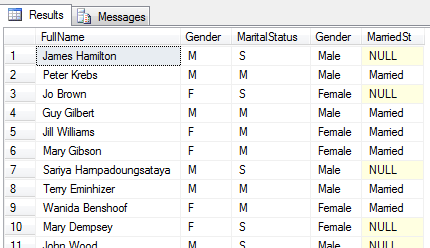
select p.FirstName + ' ' + p.LastName as FullName, e.Gender, e.MaritalStatus,
CASE WHEN Gender = 'F' THEN 'Female'
ELSE 'Male' END as Gender,
CASE WHEN MaritalStatus = 'M' THEN 'Married' END as MarriedSt
from HumanResources.Employee e
inner join Person.Person p on e.BusinessEntityID = p.BusinessEntityID
Podzapytania zwracające pojedynczy, skalarny element
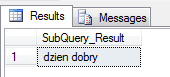
Jak już doskonale pamiętasz, możemy w SELECT umieścić wszystko co jest skalarem, czyli także wynik podzapytania zwracający jednoelementowy zbiór, opisany jednym atrybutem. Wróćmy znów do podstaw – najprostsza kwerenda zwracała nam taki właśnie zbiór, użyjmy jej jako podzapytania.
select ( select 'dzien dobry' ) as SubQuery_Result
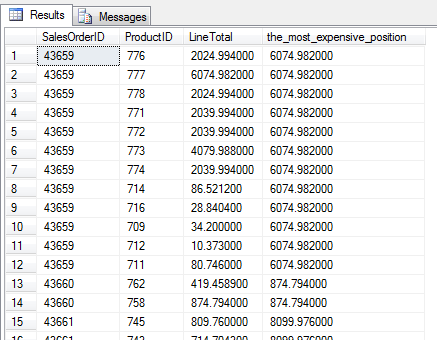
Zróbmy coś ciekawszego. Tym razem będzie to zapytanie skorelowane, ale nie koncentruj się na nim (więcej o tego typu podzapytaniach znajdziesz tutaj) – tutaj ważna jest sama idea SELECT – możliwość umieszczania skalarnego wyniku podzapytania jako jednego z atrybutów opisujących element zbioru wynikowego.
W wyniku poniższego podzapytania, zwracana jest wartość najdroższej pozycji w ramach zamówienia i atrybut ten (kolumnę) nazwiemy the_most_expensive_position.
select sod.SalesOrderID, ProductID, LineTotal,
( -- wartość atrybutu, określona przez podzapytanie
select MAX(LineTotal) from Sales.SalesOrderDetail
where SalesOrderID=sod.SalesOrderID
) as the_most_expensive_position
from Sales.SalesOrderDetail as sod
Zmienne
Kolejną grupą wartości skalarnych z którymi możesz się zetknąć i które możesz użyć w klauzuli SELECT są zmienne. Jak już wspominałem, język SQL to nie tylko zapytania, ale także język skryptowy, pozwalający na deklarowanie zmiennych i przechowywanie w nich wartości (zupełnie tak jak w innych językach np. C#). Jeśli zmienna jest skalarna – to oczywiście możemy ją również użyć w SELECT, do określenia wartości atrybutu jak również we wszelkich przekształceniach, kalkulacjach czy jako przekazywany argument do funkcji.
USE NORTHWIND
GO
declare @stawaVat decimal (2,2)
Set @stawaVat = 0.23
select @stawaVat as Stawka_VAT
select UnitPrice, Quantity, Discount,
(UnitPrice*Quantity*(1-Discount))*(@stawaVat+1) as TotalBrutto
from dbo.[Order Details]
-- przykład użycia zmiennych globalnych systemowych
Select @@Version as Wersja, @@Servername as NazwaSerwera
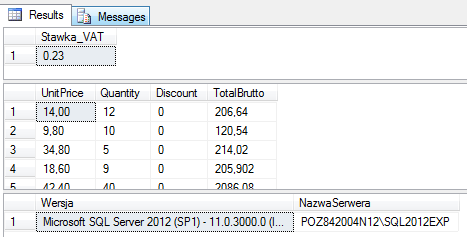
Jeśli chodzi o pozostałe typy obiektów, jakie mogą pojawiać się w SELECT to mam dla Ciebie dobrą wiadomość – nic więcej Cię nie zaskoczy! Zawsze to będzie obiekt skalarny który będzie definiował atrybut elementu wynikowego (wartość kolumny, wiersza w tabeli wynikowej).
Pozostałe funkcjonalności SELECT
Oprócz funkcji wbudowanych, których jest zbyt wiele, aby je tutaj opisywać, istnieje jeszcze kilka funkcjonalności, rozszerzających polecenie SELECT, które są stosowane tylko i wyłącznie w tej klauzuli.
Usuwanie duplikatów elementów DISTINCT
Zbiór wynikowy, może zawierać wiele elementów, również duplikaty wierszy. Jeśli chcesz otrzymać unikalny zbiór bez duplikatów – możesz to zrobić za pomocą DISTINCT.
-- DISTINCT usunie wszytkie duplikaty
select DISTINCT FirstName
from Person.Person
where FirstName = 'Ben'
TOP – ograniczenie wyniku zbioru do n elementów
Za pomocą słowa kluczowego TOP, możesz ograniczyć liczbę zwracanych wierszy do liczby bezwzględnej lub procentowej. Możliwości jakie daje TOP :
-- tylko 10 wierszy (teoretycznie losowych, bo nie ma sortowania)
select TOP 10 FirstName, LastName
from Person.Person
-- 10 Procent wierszy
select TOP 10 PERCENT FirstName, LastName
from Person.Person
Jest jeszcze jedna opcja związana z TOP, którą najlepiej obrazuje to przykład TOP 3 w zawodach sportowych.
Jeśli dwóch zawodników uzyska ten sam, rekordowy rezultat – dostają ten sam medal, więc teoretyczne, może być więcej niż 3 medalistów. To właśnie załatwia nam opcja WITH TIES.
Ogranicza ona liczbę zbioru wyniku rekordów do zadanej wartości liczbowej lub procentowej podobnie jak samo TOP.
Dodatkowo dołącza do zbioru elementy, które posiadają identyczną wartość, jak ostatni wiersz z danego zakresu, według reguły sortowania.
-- 10 wierszy ale również z "remisowymi" czyli z ogonkiem
-- WITH TIES tylko z ORDER BY
select TOP 10 WITH TIES FirstName, LastName
from Person.Person
order by LastName
Czyli w przypadku WITH TIES, konieczne jest jawne umieszczenie w kwerendzie klauzuli sortowania ORDER BY.
W dokumentacji BOL, znajdziesz jeszcze jedną opcję, której jednak nigdy nie spotkałem w zastosowaniu – SELECT ALL (przeciwieństwo DISTINCT), która to jest zawsze domyślnie stosowana. Określa ona zbiór wynikowy łącznie z duplikatami co jest tak naturalne, że nikt tego jawnie nie używa (bo i po co).
SELECT INTO
Pozostała jeszcze ostatnie polecenie w ramach SELECT z którym możesz się spotkać.
Nie służy ono do formowania wyniku i nie jest używane w kwerendach do wyciągania i pokazywania danych dlatego nie będę się tutaj na jego temat zbytnio rozpisywał. Jednak, aby być kompletnym i z uwagi na to, że jest to bardzo przyjemna funkcjonalność parę słów się należy.
Konstrukcja SELECT INTO przekierowuje wynik zwracany przez zapytanie w proces materializowania tabeli wynikowej czyli tworzy tabelę wynikową (wcześniej VT) z całą zawartością jaka jest zwracana przez kwerendę.
SELECT INTO to łatwy, szybki i bardzo wygodny sposób na przechowanie wyniku zapytania np. w tabeli tymczasowej. Wszystkie typy danych i nazwy kolumn będą również skopiowane z tabel źródłowych do których się odwołujemy w zapytaniu.
Hej
zastanawiam się czy ten przyklad z TOP 3 jest wlasciwy do WITH TIES:
„Jest jeszcze jedna opcja związana z TOP, którą najlepiej obrazuje to przykład TOP 3 w zawodach sportowych.
Jeśli dwóch zawodników uzyska ten sam, rekordowy rezultat – dostają ten sam medal, więc teoretyczne, może być więcej niż 3 medalistów. To właśnie załatwia nam opcja WITH TIES. ”
Bo czy jeśli bedą dwa pierwsze miejsca (albo dwa drugie miejsca a jedno pierwsze), a my chcemy wyciągnąć TOP 3 w zawodach sportowych, to w tym przypadku, tak naprawde dostaniemy tylko pierwsze i drugie miejsce? TOP 3 sprawdzi się tylko, gdy bedzie wiecej niż jedna osoba, ktora zajmie trzecie miejsce
Masz rację, lepiej byłoby tu urzyć funkcji okna RANK() OVER() – w przypadku faktycznych 3 miejsc, żeby nie pominąć brązowych medalistów (1 złoto, 4 srebra ;))
W jaki sposób mogę wyświetlić dane z jednej tabeli, gdy jedna z kolumn zawiera dwa rodzaje danych, a ja chcę mieć dwie wartości, będące sumami tych dwóch rodzajów ?
W bazach relacyjnych jest to błąd projektowy. Atrybuty powinny mieć tylko jeden typ danych. Jeśli naprawdę już musisz, to pozostaje tylko rzutowanie typóœ (np. funkcje CAST / CONVERT)
Witam,
…a gdzie znajdę ten rozdział x o zapytaniach skorelowanych? 🙂
dobre…. dodałem linka 😉
Mam tabele z pracownika i kilkoma jeszcze informacjami. Chciałbym uzyskać unikalne cale rekordy, dla stanowisk i departamentów. Czyli distinct ale na całe rekordy. Prosty przykład poniżej.
stanowisko departament
sprzedawca 10
manager 15
sprzedawca 10
sprzedawca 20
stanowisko departament
sprzedawca 10
manager 15
sprzedawca 20
DISTINCT tutaj tak właśnie zadziała …
Mam jedno pytanie.
Mam tabelę „Spis” z kolumnami m.in. „kraj” i „owoc”.
Chciałabym wybrać te rezultaty z kolumny „kraj”, które są unikalne – żeby zobaczyć, które z krajów są głównymi producentami tylko jednego owocu.
Czyli np jeśli kolumna zawierałaby Polska Anglia Polska Włochy Niemcy Włochy, chciałabym uzyskać zbiór o treści „Anglia Niemcy”.
Czy jest to możliwe?
Dziękuję za pomoc!
Oczywiście, ale musiałabyś pobawić się w grupowanie i filtrowanie grup
..
GROUP BY Kraj
HAVING COUNT(Kraj) = 1
BTW. to pytanie typowe na forum (przy takich wątpliwościach najlepiej pisz na wss.pl tam jest b. fajne forum dot. SQL)