Zastosowanie i możliwości funkcji OVER()
Funkcja okna OVER() stosowana jest zazwyczaj razem z funkcjami szeregującymi. Jest ich nierozłącznym elementem i służy do określania zakresu i sposobu w jaki będą nadawane numery wierszy. Opisuję jej zastosowanie w tym zakresie w artykule dotyczącym funkcji rankingowych.
W wersjach SQL Server 2005-2008 R2, możemy ją również używać razem z funkcjami agregującymi (SUM, AVG, MAX etc). Oferuje, więc połączenie możliwości działania na grupach (bo na nich operują agregaty) i na części nie grupowanej – czyli dowolnych kolumnach, w jednym zapytaniu. Stosowanie funkcji agregujących jak widać, nie jest ograniczone tylko i wyłącznie do kwerend grupujących z jawnie określoną klauzulą GROUP BY.
USE Northwind;
--Tradycyjne używanie funkcji agregujących z GROUP BY
select OrderID , SUM(UnitPrice*Quantity) as TotWartosc
from dbo.[Order Details]
Group by OrderID;
--używanie funkcji agregującej razem z OVER() – nie musimy stosować GROUP BY,
--zatem mamy dostęp do wszystkich kolumn, nie tylko do atrybutów grupujących
select OrderID, ProductID ,
SUM(UnitPrice*Quantity) OVER(Partition by OrderID ) as TotWartosc
from dbo.[Order Details];
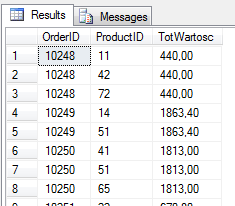
Podsumowując, w SQL Server 2005-2008 R2 funkcja okna OVER(), jest używana tylko razem z funkcjami szeregującymi lub agregujacymi. Wydziela przedział (podzbiór) z tabeli wynikowej i pozwala wykonywać na nim odpowiednie kalkulacje.
Rozszerzone możliwości OVER() w SQL Server 2012
SQL Server 2012 wprowadza szereg nowych możliwości, również w już istniejących, dobrze znanych funkcjach. Funkcja OVER(), oferuje teraz znacznie więcej w stosunku do poprzednich implementacji.
Podzbiór z podzbioru czyli frames (ramki)
Jedną z nowinek, jest możliwość działania na podzbiorach „ramkach” (widow frames) w kontekście zdefiniowanego okna dla funkcji agregujących. Ramki to kolejny poziom abstrakcji podzbiorów – w ramach definicji okna – partycji. W prostych słowach, możemy wydzielić podzbiór (ramkę) z podzbioru (okna).
Dzięki temu możemy wyznaczać sumy narastające lub inne agregacje dotychczas realizowane za pomocą podzapytań lub zapytań skorelowanych. W praktyce znacznie uprasza nam to kod SQL.
Wyznaczanie ramki za pomocą ORDER BY
Załóżmy, że chcemy pokazać zamówienia, wraz z ich detalami oraz informacją o wartości pozycji w ramach danego zamówienia jako sumy narastającej.
W tej sytuacji potrzebujemy określić za pomocą funkcji okna przedziały, obejmujące wszystkie elementy każdego zamówienia. Następnie, właśnie za pomocą ramek, możemy dla każdego elementu zamówienia (wiersza) w ramach podzbioru, wykonać dodatkowe kalkulacje.
USE AdventureWorks2008
GO
select SalesOrderId, ProductID, SalesOrderDetailId as DetailId, LineTotal ,
-- określamy okna – wszystkie elementy danego zamówienia – PARTITION BY
-- oraz ramkę. Dla każdego elementu będą to wiersze od początku przedziału
-- do current row, biorąc pod uwagę wartość sortowaną SalesOrderDetailId
SUM(LineTotal) OVER(partition by SalesOrderId order by SalesOrderDetailId) as RunningSUM,
COUNT(LineTotal) OVER(partition by SalesOrderId order by SalesOrderDetailId) as QtyFrameEl,
-- w SQL Server 2005-2008 R2 brak możliwości stosowania ORDER BY w OVER()
-- w przypadku uzycia z funkcjami agregującymi np. SUM, AVG, MAX, MIN etc
-- mogliśmy wyznaczyć agregat tylko w ramach całej partycji np. TotalValue
SUM(LineTotal) OVER(partition by SalesOrderId ) as TotalValue,
COUNT(LineTotal) OVER(partition by SalesOrderId ) as QtyWindowEl
from Sales.SalesOrderDetail
where SalesOrderId IN (43666,43664)

W tym przykładzie wyznaczmy RunningSUM czyli sumę narastającą w oparciu o dwa poziomy podzbiorów. Pierwszy – definiujemy za pomocą PARTITION BY – zakres zamówienia. W ramach niego, będziemy określali wycinek rekordów (ramkę) spełniających warunek sortowania ORDER BY. Ramka jest wyznaczana dla każdego wiersza osobno. W jej ramach, będą brane pod uwagę wszystkie rekordy dla których wartość sortująca – SalesOrderDetailId będzie mniejsza lub równa bieżącemu elementowi.
Zauważ, że sortuję po kolumnie unikalnej, zatem dla każdego n-tego wiersza, ramka będzie zawierała dokładnie n-elementów. Są to zawsze wszystkie wiersze w ramach okna, posiadające wartość atrybutu po którym sortujemy mniejszą lub równą. W powyższym przykładzie, kolumna QtyFrameElements obrazuje liczbę elementów branych pod uwagę w ramach ramki.
Pierwsza ramka zawiera tylko element SalesOrderDetailId = 53. Sumowanie dla tego podzbioru to oczywiście tylko wartość 2039.994000.
Druga ramka zawierać będzie wszystkie elementy poprzedzające (wartości <54) + element danego wiersza – czyli będą to pozycje numer 53 oraz 54.Funkcja agregująca, będzie zatem sumowała wartości tych dwóch elementów. Każda następna będzie działać dokładnie tak samo. Dla n-tego wiersza, agregacja odbywać będzie się w ramach n-tej ramki zawierającej n-elementów, mniejszych lub równych wartości SalesOrderId dla danego rekordu . Żeby dobrze zrozumieć działanie ramek, proponuję jeszcze jeden przykład z sortowaniem (określaniem ramek) po kolumnie nieunikalnej w ramach przedziału (partycji). Określmy więc podzbiór (ramkę) elementów według ilości danej pozycji w zamówieniu:
select SalesOrderId, ProductID, OrderQty,
SUM(OrderQty) OVER(partition by SalesOrderId order by OrderQty) as RunningQty,
COUNT(OrderQty) OVER(partition by SalesOrderId order by OrderQty) as QtyFrameElements
from Sales.SalesOrderDetail
where SalesOrderId IN (43666,43664)
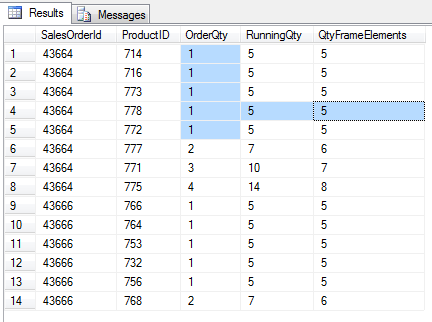
Tym razem pierwsza ramka (podobnie jak cztery kolejne) zawierać będzie 5 elementów – ponieważ zgodnie z jej definicją, jest 5 wierszy spełniających założenia ORDER BY. Dla wszystkich pierwszych 5 wierszy (czyli tych z ilością danych produktów =1), ramka będzie tak samo zdefiniowana. Dlatego wynik funkcji agregującej będzie dla nich identyczny. Różnica pojawi się dopiero w 6 wierszu – w ramce znajdą się wtedy wszystkie elementy <= 2. Określanie ramek za pomocą ORDER BY jest pierwszym i najprostszym sposobem w kontekście partycji elementów. Wyznaczany jest zawsze dla każdego wiersza tak samo. Funkcja agregująca, działająca w jej ramach, bierze pod uwagę wszystkie elementy podzbioru, które są mniejsze lub równe wartości wiersza po której sortujemy.
Precyzyjne wyznaczanie wielkości ramki za pomocą RANGE i ROWS
Ramkę możemy wyznaczyć bardziej precyzyjnie niż tylko poprzez elementy poprzedzające plus bieżący wiersz jak ma to miejsce w sytuacji stosowania samego ORDER BY. W SQL Server 2012 pojawiły się rozszerzenia klauzuli OVER() – RANGE oraz ROWS, za pomocą których definiujemy rozmiar ramki. Może być on przedstawiony zawsze w formie przedziału, ze ściśle określonymi granicami. Składnia jest prosta i w ogólności bazuje na schemacie :
{ROWS | RANGE} BETWEEN <początek przedziału ramki> AND <koniec przedziału ramki>
ROWS
Pozwala na określenie rozmiaru ramki z dokładnością do pojedynczego wiersza. Początek i koniec przedziału, definiowane mogą być za pomocą :
- UNBOUNDED PRECEDING – wszystkie rekordy od początku ramki (poprzedzające wiersz, dla którego ramka jest wyznaczana)
- <unsigned integer> PRECEDING – konkretna liczba wierszy poprzedzających
- CURRENT ROW – reprezentuje konkretny, bieżący wiersz dla którego wyznaczana jest ramka
- <unsigned integer> FOLLOWING – konkretna liczba wierszy następujących po danym elemencie.
- UNBOUNDED FOLLOWING – wszystkie wiersze do końca podzbioru okna.
Przykład – zwróć uwagę na rozmiar ramki – kolumna QtyFrEle
select SalesOrderId, ProductID, UnitPrice, OrderQty,
SUM(OrderQty) OVER(partition by SalesOrderId order by SalesOrderDetailId
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) as RunningQty,
-- liczba elementów w ramce, dla każdego wiersza
COUNT(OrderQty) OVER(partition by SalesOrderId order by SalesOrderDetailId
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
) as QtyFrEle
from Sales.SalesOrderDetail
where SalesOrderId IN (43666,43664)
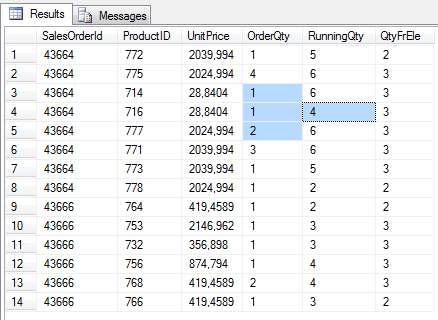
Przy określaniu rozmiaru za pomocą konkretnej liczby wierszy poprzedzających / następujących, trzeba zwrócić uwagę na potencjalnie różną liczbę elementów ramek (początkowych i końcowych).
Ramka, może być też określona, w uproszczony sposób, bez jawnego przedziału (BETWEEN … AND …). Możemy określić tylko liczbę wierszy poprzedzających, które mają być brane pod uwagę. Jest to skrócona, wygodna forma zapisu określający przedział ramki do bieżącego rekordu.
select SalesOrderId, ProductID,UnitPrice,OrderQty,SalesOrderDetailId, LineTotal ,
SUM(LineTotal) OVER(partition by SalesOrderId order by SalesOrderDetailId
ROWS 1 PRECEDING
) as RunningQty,
-- liczba elementów w ramce, dla każdego wiersza
COUNT(OrderQty) OVER(partition by SalesOrderId order by SalesOrderDetailId
ROWS 1 PRECEDING
) as QtyFrEle
from Sales.SalesOrderDetail
where SalesOrderId IN (43666,43664)
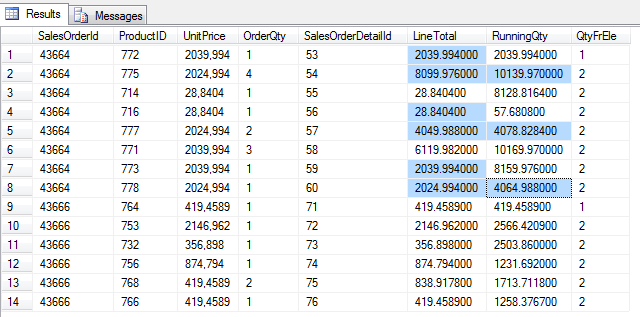
RANGE
Różnica pomiędzy ROWS a RANGE polega na innej interpretacji granic przedziałów. W szczególności dotyczy to bieżącego wiersza (current row). W ramce określanej przez ROWS, jest on dokładnie tym wierszem, dla którego wyznaczana jest ramka. Podobnie początek jak i koniec przedziału może być w ROWS określony do konkretnego numeru, fizycznego wiersza.
Z kolei CURRENT ROW w przypadku RANGE, oznacza zarówno bieżący wiersz, jak i wszystkie, których wartości sortowane w ORDER BY (wyznaczających, domyślnie ramkę) są równe. Dlatego też, nie możemy stosować w RANGE – konkretnej liczby wierszy poprzedzających jak i następujących, bo w zbiorze mogą pojawić się wartości równe i zapytanie nie byłoby jednoznacznie określone.
Range przyjmuje zatem tylko 3 konkretne granice przedziałów :
- RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW – wszystko od początku przedziału do danego zakresu określonego przez wartość elementu sortującego danego wiersza.
- RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING – analogicznie do poprzedniego tylko w drugą stronę.
- RANGE CURRENT ROW – wszystkie wiersze, dla których atrybut sortowany jest równy bieżącemu rekordowi w ramach okna.
Sposób działania RANGE, został już pokazany (niejawnie) w pierwszym przykładzie, najprostszego definiowania ramek czyli z ORDER BY. Samo ODRER BY określa ramkę na zasadzie – wszystkie mniejsze lub równe wiersze według wartości sortującej. Jest to zatem równoważnik RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
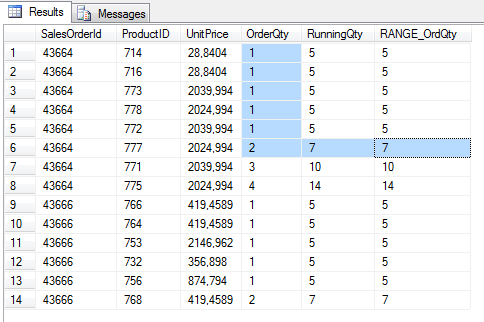
select SalesOrderId, ProductID,UnitPrice,OrderQty,
SUM(OrderQty) OVER(partition by SalesOrderId order by OrderQty) as RunningQty,
SUM(OrderQty) OVER(partition by SalesOrderId order by OrderQty
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as RANGE_OrdQty
from Sales.SalesOrderDetail
where SalesOrderId IN (43666,43664)
Ramki w funkcjach analitycznych
W SQL Server 2012, wprowadzono kilka nowych funkcji analitycznych. Koncepcja ramek w zakresie definiowanym funkcją okna OVER, jest również dostępna w niektórych z nich.
Sposób określania jest analogiczny do wyżej wymienionego z pewnymi ograniczeniami, wynikającymi już z charakteru samych funkcji. Można ją spotkać np. w FIRST_VALUE czy LAST_VALUE.
Dlaczego ta kwerenda zwraca mi 3 rekordy a nie 2?
3 a nie 2 bo nie grupujemy tutaj rekordów a operujemy tylko funkcją okna na danych które … już niemal są zwracane (która tutaj działa w przed ostatnim kroku przetwarzania – tuż przed order by).
Przeczytaj ten artykuł o logicznym przetwarzaniu zapytania. Szczególnie fragment o grupowaniu rekordów.
To co robimy w select funkcją okna, to działanie na przedostatnim kroku. Jeśli chcemy agregować – trzeba zrobić group by, niby podobne ale różnica jest olbrzymia 😉
Napisałem zliczanie narastająco po dacie.
SUM(X) OVER (PARTITION BY ROK, Y ORDER BY DATA ROWS UNBOUNDED PRECEDING)
Jednak problem jest taki, że jeżeli w dla danej daty nie wystąpił żaden rekord dla Y to nie wyrzuca mi tego w zliczaniu. Jest to problem poniewaz bardzo potrzebuje pokazywać ten rekord Y przy każdej zmianie DATA nawet jeżeli wystapił tylko raz.
Cześć, czy na pewno jest prawdą, z poprawiłeś to napisał w komentarzu kolega:
„Lipiec 4, 2017 at 1:33 pm
Jest błąd w pierwszym przykładzie opisującym działanie ramek, tj. posługujesz się przy omawianiu działania ramek kolumną SalesOrderId, która wyznacza okno, natomiast ramki są wyznaczane przez SalesOrderDetailId, dwa razy są pomylone te nazwy, można poprawić ;)”
bo nie byłeś pewien.
Nie za bardzo też rozumiem, jak order by możesz w dawać wyrażenie, które jest aliasem innej kolumny.
Czy to działanie ramek jest inne jak w Oracle ? Przecież w Oracle to nie będzie tak, że jak napiszesz, gdy dasz:
SELECT EMPLOYEE_ID , SUM(SALARY) OVER(partition by EMPLOYEE_ID order by EMPLOYEE_ID ) as RunningSUM
FROM EMPLOYEE_
to dostaniesz RunningSUM.
Dzięki.
Nie używam tutaj aliasów kolumn – tego nie można – tylko oryginalnych nazw. Działanie jest takie samo jak w Oracle – gdzie widzisz alias ?
A jak podzielić na okna, ramki itp takie coś?
Tabela kolumny: data i wartość.
Chcę obliczyć ilość unikalnych wartości w przedziałach dat, według wzorca.
1. pierwszy przedział: data_początkowa_1, data_końcowa_1 = (data_początkowa_1 + 12 mscy – 1 dzień)
2. drugi przedział: data_początkowa_2 = data_początkowa_1 + 1 msc, data_końcowa_2 = data_końcowa_1+1 msc
itd
Czy da się to zrobić za pomocą over(partition by)???
Przykład działania FIRST_VALUE oraz LAST_VALUE dla AdventureWorks2008:
USE [AdventureWorks2008]
GO
SELECT [Name]
,[ListPrice]
,FIRST_VALUE( [Name] ) OVER ( ORDER BY [ListPrice] ASC ) AS [LeastExpensive]
,LAST_VALUE( [Name] ) OVER ( ORDER BY [ListPrice] ASC RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS [MostExpensive]
FROM [Production].[Product]
WHERE [ProductSubcategoryID] = 37
;
Intuicyjnie, myślę, że dla RANGE także z powodzeniem mogłoby funkcjonować określanie ramek przez podawanie konkretnej liczby poprzedzających grup, w ramach których wartość elementu sortującego byłaby równa, podobnie jak dla ROWS, liczone były by tylko zakresy (od range) zamiast wierszy (od rows). Nie wiem co stało na przeszkodzie, ale rozumiem, że takiej możliwości po prostu obecnie nie ma?
Jest błąd w pierwszym przykładzie opisującym działanie ramek, tj. posługujesz się przy omawianiu działania ramek kolumną SalesOrderId, która wyznacza okno, natomiast ramki są wyznaczane przez SalesOrderDetailId, dwa razy są pomylone te nazwy, można poprawić 😉
Tak dzięki za komentarz, zdaje się że poprawiłem 😉
Nie da się partycjonować albo group by dwóch kolumnach na raz wewnątrz OVER()?
Nic nie stoi na przeszkodzie 🙂 Można partycjonować po wielu kolumnach na raz (analogicznie do grupowania).