Opisane w pierwszym artykule tego rozdziału, sposoby łączenia tabel w klauzuli FROM – dotyczyły łączenia zbiorów w sposób poziomy. Określane były typy złączeń (m.in. INNER, OUTER JOIN) oraz warunki dopasowania rekordów – wyszczególnione przed operatorem ON.
W wyniku otrzymywaliśmy zbiór elementów, opisywany za pomocą wszystkich kolumn (atrybutów) łączonych tabel. Dlatego nazywamy to połączenie jako poziome.
Drugą grupą operacji na zbiorach, są operacje pionowe, czyli :
- UNION – suma zbiorów
- EXCEPT – odejmowanie zbiorów
- INTERSECT – iloczyn (część wspólna)
Operują one zawsze, na wynikach całych kwerend (tabel wejściowych) i zwracają tabelę wynikową, będącą zbiorem identycznie określonym jak pierwsza tabela wejściowa (liczba i nazwy kolumn). Zawierają jednak elementy (wiersze), zgodne z arytmetyką zbiorów, określoną przez operator : UNION, UNION ALL, EXCEPT lub INTERSECT. W jednym zapytaniu możemy dokonywać wiele operacji na zbiorach np. łączyć (UNION) wyniki 5 kwerend (tabel wejściowych).
Ogólne zasady operacji na zbiorach obrazuje poniższy schemat :
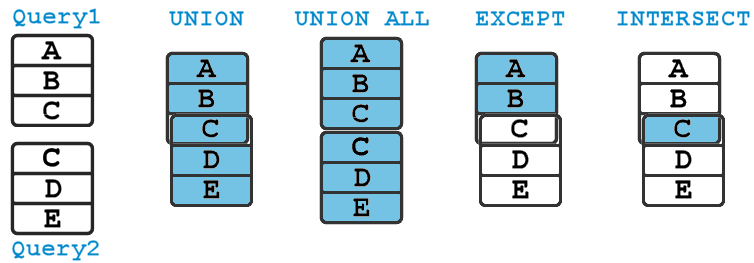
Warunki operacji na zbiorach
Jest kilka zasad, które muszą być spełnione. Warunkiem podstawowym, któregokolwiek ze sposobów operowania na zbiorach w sposób pionowy, jest podobna struktura tabel wejściowych.
Liczba kolumn w każdym zbiorze (kwerendzie), musi być identyczna oraz typy danych poszczególnych kolumn, muszą do siebie pasować. Nazwy kolumn, nie mają znaczenia. W zbiorze wynikowym, atrybuty będą nazwane tak jak w pierwszej z kwerend.
Możemy wykonywać wiele operacji na zbiorach, np. złączenie trzech wyników kwerend w jeden zbiór :
-- kwerenda pierwsza (zbiór elementów)
SELECT 'Pierwszy' as Opis, getdate() as Dt, 132 as liczba
UNION -- operator łączenia zbiorów
-- kwerenda druga (zbiór elementów)
SELECT 'Drugi' as ZupelnieInnyOpis, '2013-01-01' as DataZlecenia, 0.2
UNION -- łączenie zbiorów, połączy wynik pierwszego UNION z kwerendą trzecią
-- kwerenda trzecia (zbiór elementów)
SELECT 'Trzeci' as Opisik, '2012-11-21' as dt, 0
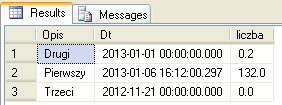
Jak widzimy w tym przykładzie, wszystkie trzy „kwerendy” zwracają po jednym elemencie opisanym 3 atrybutami. Niektóre z tych atrybutów są innego typu (np. 132 z pierwszego zbioru to typ integer, wartość 0.2 w drugim to decimal), ale są to typy kompatybilne (możliwa jest ich bezstratna niejawna konwersja).
Jeśli spróbowalibyśmy, połączyć zbiory o różnych typach w tych samych kolumnach, np. :
-- wartości w kolumnie 3 są typu integer
select 'Pierwszy' as Opis, getdate() as Data, 132 as liczba
UNION
-- z kolei tutaj w 3 kolumnie mamy tekst
select 'Drugi', '2013-01-01', 'sto dwa'
otrzymamy komunikat o błędzie :
Msg 245, Level 16, State 1, Line 2 Conversion failed when converting the varchar value 'sto dwa' to data type int.
Podobnie jeśli liczba kolumn nie będzie równa :
select 'Pierwszy' as Opis, getdate() as Data, 132 as liczba
union
select 'Drugi', '2013-01-01'
Tym razem dostaniemy info o różnej liczbie kolumn w zbiorach, które mają być łączone :
Msg 205, Level 16, State 1, Line 1 All queries combined using a UNION, INTERSECT or EXCEPT operator must have an equal number of expressions in their target lists.
Trzeba pamiętać o tej podstawowej zasadzie i zadbać o to, aby była ona zawsze spełniona.
Zazwyczaj nie jest to trudne, bo jeśli masz dwie kwerendy, które chcesz połączyć i zawierają one różne liczby kolumn, wystarczy sztucznie „uzupełnić” brakującą liczbę, np. wartościami NULL :
select kol1, kol2, kol3
From tabela1
union
select kol1, kol2, NULL
from tabela2
Podobnie jeśli typy danych nie są kompatybilne, zawsze można je zmienić (np. stosując funkcję CAST lub CONVERT), na typ bardziej ogólny – np. na varchar.
Podczas łączenia zbiorów, analizowana jest liczba i typ ich atrybutów (kolumn zwracanych w kwerendach), dlatego jest to kolejny powód dla którego nie powinniśmy stosować symbolu ‘*’ w SELECT w środowiskach produkcyjnych. Może to prowadzić do błędów – wystarczy, że jedna z tabel biorących udział w łączeniu zostanie zmodyfikowana (dodana lub usunięta kolumna).
Dodatkowy warunek, wynika z definicji zbiorów i operacji na nich. Elementy w ramach zbioru nie są uporządkowane. Operacje na zbiorach działają więc zawsze na nieposortowanych elementach.
Ponieważ sortowanie ma duży wpływ na wydajność a zgodnie z tym co przed chwilą powiedzieliśmy, nie ma znaczenia na wynik – dlatego nie można używać operatora ORDER BY w kwerendach biorących udział w operacjach łączenia/odejmowania czy wyznaczania części wspólnej zbiorów.
Możemy dopisać ORDER BY na samym końcu – będzie się ono odnosiło do tabeli wynikowej (ostatecznego rezultatu wszystkich określonych operacji na zbiorach).
Operator UNION – łączenie zbiorów
UNION oznacza sumę zbiorów. W wyniku otrzymamy elementy znajdujące się zarówno w zbiorze pierwszym jak i drugim, ale domyślnie jest to operacja UNION DISTINCT, czyli z usunięciem wszystkich duplikatów. W szczególności znajdujących się jako część wspólna zbiorów, a także duplikatów istniejących w ramach tabel wejściowych.
Use Northwind
GO
-- pierwsze zaoytanie zwraca 9 elementów (niektóre się powtarzają)
select Country from [dbo].[Employees]
where Country like 'U%'
UNION
-- drugie zapytanie zwraca 20 elementów (niektóre się powtarzają)
select Country from [dbo].[Customers]
where Country like 'U%'
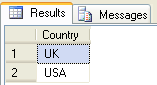
Każde z zapytań biorących udział w operacji łączenia zbiorów zwraca w wyniku zdublowane wartości elementów (nie usuwamy ich za pomocą DISTINCT), robi to domyślnie operator UNION – czyli dostajemy tylko unikalne wartości elementów zbioru (A + B) – USA i UK. Usunięte są one zarówno z kwerend wejściowych, jak i z części wspólnej zbioru A i B).
UNION ALL – łączenie bez usuwania duplikatów
Drugim sposobem na dodawanie zbiorów jest UNION ALL – czyli bez usuwania duplikatów. Tym razem z każdego zbioru, bierzemy tylko 5 pierwszych wierszy (załatawia to TOP 5) i pomimo, że elementy się powtarzają, w wyniku dostaniemy 10 wierszy.
-- pierwsze zapytanie zwraca 9 elementów (niektóre się powtarzają)
-- tym razem bierzemy tylko 5 pierwszych - TOP 5
select top 5 Country
from [dbo].[Employees]
where Country like 'U%'
UNION ALL
-- drugie zapytanie zwraca 20 elementów (niektóre się powtarzają)
-- tym razem bierzemy tylko 5 pierwszych - TOP 5
select top 5 Country
from [dbo].[Customers]
where Country like 'U%'
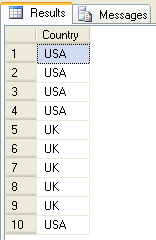
EXCEPT – odejmowanie zbiorów
Zasada działania jest prosta. Ze zbioru pierwszego (czyli po lewej stronie od operatora EXCEPT), odejmowane są wszystkie elementy wspólne ze zbiorem drugim (tabeli wynikowej, kwerendy po prawej stronie).
Odejmowanie zbiorów za pomocą EXCEPT zostało zaimplementowane w SQL Server tylko jako EXCEPT DISTINCT, czyli w zbiorze wynikowym, zawsze usuwane są wszystkie duplikaty rekordów. Przykład :
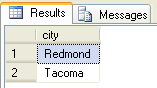
-- pierwsze zapytanie zwraca 4 miasta - Seattle, Tacoma, Kirkland i Redmond
select city from [dbo].[Employees]
where Country = 'USA'
EXCEPT -- operator odejmowania zbiorów
-- drugie zapytanie zwraca znacznie więcej miast,
-- wśród nich są Seattle i Kirkland
select city from [dbo].[Customers]
where Country = 'USA'
Jeśli jednak potrzebujemy zrobić EXCEPT ALL, bez usuwania duplikatów – możemy to zrealizować za pomocą ROW_NUMBER, funkcji szeregującej, która nada nam unikalność rekordów, w ramach duplikatów.
Przykładowe działanie EXCEPT ALL, można przedstawić w takim scenariuszu :
Jeśli zdarzyłoby się, że w zbiorze A, pojawi się element X 3 razy, a w zbiorze B element X wystąpi 2 razy, to w zbiorze wynikowym, element X powinien pojawić się raz.
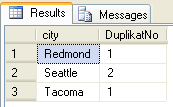
W tym przykładzie, każdy duplikat w ramach zbioru jest ponumerowany :
-- Q1 pierwsze zapytanie zwraca 4 miasta - Seattle (dwa razy), Tacoma, Kirkland i Redmond
select city, ROW_NUMBER() OVER(partition by city order by city) as DuplikatNo
from [dbo].[Employees]
where Country = 'USA'
EXCEPT
-- Q2 drugie zapytanie zwraca znacznie więcej,
-- wśród nich są również Seattle (tylko raz) i Kirkland
select city, ROW_NUMBER() OVER(partition by city order by city) as DuplikatNo
from [dbo].[Customers]
where Country = 'USA'
Jeśli sprawdzasz działanie powyższego zapytania – sugeruję, uruchomić najpierw każde z nich osobno, aby zaobserowować dokładnie jakie elementy są zwracane. Następnie całość.
Wynik działania obrazuje poniższy schemat :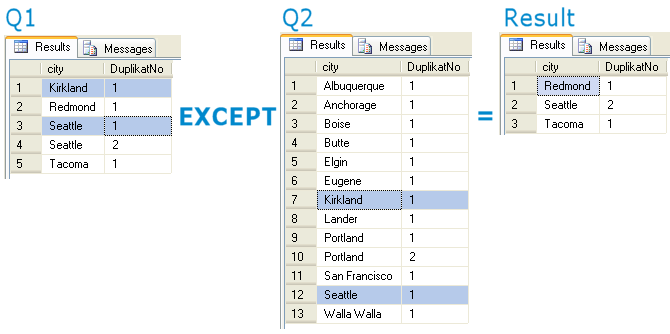
INTERSECT – część wspólna zbiorów
Do wyznaczenia części wspólnej zbiorów, używamy operatora INTERSECT. Podobnie jak EXCEPT, zaimplementowany w SQL Server, został również tylko jako INTERSECT DISTINCT, czyli części wspólna dwóch zbiorów z usunięciem duplikatów.
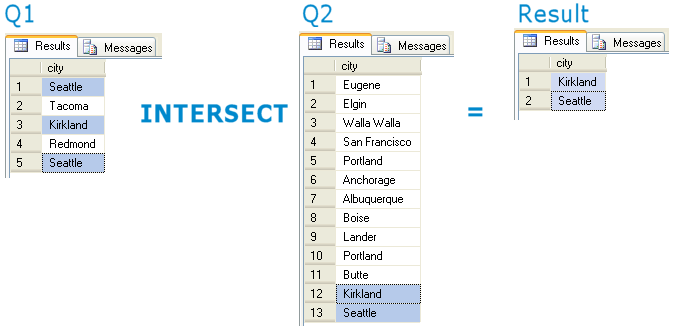
-- Q1 pierwsze zapytanie zwraca 4 miasta - Seattle (dwa razy), Tacoma, Kirkland i Redmond
select city
from [dbo].[Employees]
where Country = 'USA'
INTERSECT
-- Q2 drugie zapytanie zwraca znacznie więcej,
-- ale wśród nich są też Seattle (tylko raz) i Kirkland
select city
from [dbo].[Customers]
where Country = 'USA'
Jeśli chcesz wyznaczyć część wspólną bez usuwania duplikatów, możesz użyć dokładnie tej samej sztuczki co poprzednio czyli numeracji rekordów. Wtedy jeśli w dwóch zbiorach będą po dwa duplikaty tego samego elementu – zostaną zwrócone dzięki unikalności elementów, jaką wprowadzi nam ROW_NUMBER.
-- Q1 pierwsze zapytanie zwraca 2 kraje, ponumerowane za pomocą ROW_NUMBER
-- 4 duplikaty UK oraz 5 duplikatów USA
select country, ROW_NUMBER() OVER(partition by country order by country) as rn
from [dbo].[Employees]
where Country like 'U%'
INTERSECT
-- Q2 drugie zapytanie zwraca znacznie więcej, ale wśród nich są również
-- przynajmniej 4 UK i min. 5 USA
select country, ROW_NUMBER() OVER(partition by country order by country) as rn
from [dbo].[Customers]
where Country like 'U%'

Kolejność wykonywania operacji
Możemy operować na wielu zbiorach w ramach jednej kwerendy i stosować różne operacje. Obowiązuje tutaj kolejność wykonywania działań – dokładnie tak jak w matematyce.
Select kol1, kol2, kol3 from tabela1
UNION
Select kol1, kol2, kol3 from tabela2
EXCEPT
Select kol1, kol2, kol3 from tabela3
INTERSECT
(
Select kol1, kol2, kol3 from tabela4
UNION
Select kol1, kol2, kol3 from tabela5
)
Najpierw zostaną wykonane działania w nawiasach, czyli UNION ostatnich dwóch kwerend (wyciągających dane z tabeli 4 i 5). Następnie mnożenie zbiorów, czyli INTERSECT – część współna pomiędzy wynikiem wyznaczonym w kroku pierwszym a kwerendą wyciągającą dane z tabeli3.
W końcu, jeśli nie ma już żadnych nawiasów i iloczynów, zostaną wykonane wszystkie pozostałe kroki od lewej do prawej, czyli w tym przypadku najpierw, pierwszy UNION i w końcu EXCEPT.
Poprzez stosowanie nawiasów, mamy pełną kontrolę nad logiczną kolejnością wykonywanania działań.
Fajny artykuł!
A może jeszcze przykład jak wynik np. UNION ALL wstawić do innej tabeli (w tej samej bazie).
Świetny artykuł, gratuluję!
Jedyne co bym dodał to tylko to, że jeżeli twórca zapytania jest pewny co do unikalności wartości, to lepiej stosować UNION ALL, żeby pozbyć się operatora sortowania służącego do eliminacji duplikatów 🙂 Pozdrawiam serdecznie!
Tak ! cenna uwaga 🙂
czy jest możliwe wykonanie takiego zapytania używając samych operacji na zbiorach cytuję:
wyświetlić wszystkich pracowników i klientów(ich imiona i nazwiska), noszących takie samo nazwisko?
select imie,nazwisko
from
(
select imie,nazwisko from klienci
union all
select imie,nazwisko from pracownicy
)a
bo wiem że muszę wykorzystać intersect ale nie wiem jak go tutaj wstawić
Hej,
artykuł świetny ,ale
mógłbyś mi wyjaśnić dlaczego
SELECT SUM(a.a)
FROM
(
select a FROM (
(
select 1 as a
union all
select 1 as a
)
intersect
select 1 as a
*union all
*select 1 as a
)a
)a
Daje wynik 2 a nie 1 skoro intersect wycina duplikaty ? i dlaczego po zakomentowaniu lini oznaczonych * jest wynik 1 ? Pozdrawiam
Odpowiedź jest dość prosta – kolejność wykonywania działań (zwróć uwagę na nawiasy). Intersect działa na pierwszym zbiorze dwuelementowym oraz na drugim, jednoelementowym. W Twoim przykładzie na koniec (do wyniku) dodajesz ostatnim UNION ALL jeszcze jeden element stąd wynik 2. Trochę sformatuje query żeby bylo czytelniej 🙂
Faktycznie, moje niedopatrzenie 🙂 Dzięki wielkie 🙂