W SQL Server mamy wiele sposobów i narzędzi, za pomocą których możemy obserwować liczniki związane z wydajnością – DMV, statystyki sesji, Extended Events czy Profiler. Analizując szczegółowo pewien przypadek skanowania indeksu, natrafiłem na kolejny wyjątek przekłamywania informacji o dokładnej liczbie fizycznych odczytów przez zmienną sesji STATSTISTICS IO.
Statystyki odczytów – SET STATISTICS IO
Powszechnie znanym problemem związanym ze statystykami widocznymi poprzez STATISTICS IO, jest pomijanie liczby odczytów generowanych przez funkcje skalarne użytkownika. Brak informacji w planie wykonania, jak również w statystykach odczytu jest mylące i może prowadzić do błędnej interpretacji wyników np. w porównywaniu wydajności zapytań. Jak się okazuje nie jest to jedyny przypadek pomijania niektórych odczytów z wykorzystaniem STATISTICS IO.
Na zjawisko większej liczby stron wczytanej do pamięci niż by się można tego było spodziewać, natrafiłem testując skanowanie indeksu klastrowego. Warto podkreślić, że wbrew powszechnie utartym opiniom (powielanym zresztą w wielu publikacjach), skanowanie indeksu to nie tylko czytanie stron na poziomie liści (leaf level skan).
W trakcie skanu, wczytywana jest cała jego struktura, włącznie ze wszystkimi stronami poziomów pośrednich + strony IAM, co może wydawać się nieco zaskakujące. Wynika to prawdopodobnie z faktu, że zazwyczaj sama struktura indeksu (korzeń + poziomy pośrednie) jest relatywnie niewielka w stosunku do poziomu liści. Skanując więc tabelę, warto przy okazji przeczytać pozostałe strony, aby mieć w pamięci cały obiekt. Poza tym strony te, i tak głównie znajdują się w ekstentach zalokowanych na potrzeby danej tabeli, więc zysk z wykorzystanie odczytów wyprzedzających (read-ahead reads) jest znacznie większy niż odsiewanie stron indeksu (<> DATA_PAGES). Taka jest moja interpretacja tego faktu.
Krótki przykład. Skanowanie indeksu klastrowego tabeli dbo.Orders i liczba odczytów widocznych poprzez SET STATISTICS IO :
USE NORTHWIND
GO
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
CHECKPOINT
GO
SET STATISTICS IO ON
GO
SELECT * FROM dbo.Orders
(830 row(s) affected) Table 'Orders'. Scan count 1, logical reads 22, physical reads 1, read-ahead reads 21, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
W tym przypadku, pierwsze wykonanie zapytania (z wyczyszczonym buforem) skutkowało w sumie 22 odczytami fizycznymi (physical + read-ahead reads) ładującymi strukturę do pamięci RAM. Następnie, wszystkie 22 strony zostały odczytane (logical reads) w celu realizacji zapytania.
Zatem każde kolejne wykonanie tego zapytania będzie wiązało się już tylko z logicznymi odczytami owych 22 stron z bufora.
Dlaczego wartością oczekiwaną są 22 strony ? Zerknijmy na strukturę tego indeksu i całkowitą liczbę stron dla obiektu PK_Orders.
SELECT i.index_id, i.NAME
,index_type_desc
,index_level
,page_count
,record_count, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(N'dbo.Orders'),1,NULL,'DETAILED') x
INNER JOIN sys.indexes i ON x.index_id = i.index_id
AND x.object_id = i.object_id
order by i.index_id, x.index_level desc

Jak widać indeks jest dwu-poziomowy, 1 strona korzenia + 20 stron liści = 21. Brakującą stroną jest IAM, która również jest czytana. Pełna struktura, wszystkie strony dla obiektu PK_Orders to :
SELECT page_type_desc, count(*) as PageCnt
FROM
(select name, index_id from sys.indexes where object_id = object_id('dbo.Orders') and name = 'PK_Orders' ) i
cross apply sys.dm_db_database_page_allocations (db_id(), object_id('dbo.Orders'), index_id, NULL, 'DETAILED') a
where page_type_desc is not null
group by page_type_desc
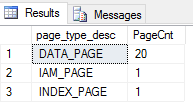
Skanowanie indeksu to wczytanie wszystkich stron związanych z jego strukturą do pamięci. Oczywiście są pewne wyjątki, chociażby częściowe skanowanie indeksu (np. SELECT TOP 10 * FROM tabela), ale w przypadku pełnych skanów… to poprostu pełne skany.
Być może powyższy przykład jest mało przekonujący z uwagi na rozmiar indeksu, ale możesz ten fakt potwierdzić, samodzielnie odpytując strukturę bardziej rozdmuchanego indeksu :
SET STATISTICS IO OFF
GO
IF object_id('dbo.CLX_TEST') is not null
DROP TABLE dbo.CLX_TEST
GO
CREATE TABLE dbo.CLX_TEST
(
id bigint IDENTITY(1,1),
id2 char(200) default NEWID(),
payload char(100),
)
GO
insert into dbo.CLX_TEST with (tablockx) (payload)
select top 10000 left(text,100) from sys.messages
GO
-- Kompozytowy żeby trochę rozdmuchać indeks
CREATE CLUSTERED INDEX CLX_ID_ID2_CLX_TEST on dbo.CLX_TEST(id,id2)
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
CHECKPOINT
GO
SET STATISTICS IO ON
GO
SELECT * FROM dbo.CLX_TEST
SELECT page_type_desc, page_level, COUNT(*) as PageCnt
FROM sys.dm_db_database_page_allocations
(db_id(), object_id('dbo.CLX_TEST'), 1, NULL, 'DETAILED') a
WHERE page_type_desc is not null
GROUP BY page_type_desc, page_level
Fizyczne odczyty
Wróćmy do odczytów fizycznych, czy na pewno było ich 22 ? Zerknijmy raz jeszcze na statystyki i liczbę stron danych bazy Northwind, które pojawią się w buforze (widok sys.dm_os_buffer_descriptors, strony z innych baz, odczyty systemowe etc. pomijam) :
IF object_id('tempdb..#t1') is not null
DROP TABLE #t1
IF object_id('tempdb..#t2') is not null
DROP TABLE #t2
GO
dbcc freeproccache
dbcc dropcleanbuffers
checkpoint
GO
select * into #t1 from sys.dm_os_buffer_descriptors where database_id = db_id()
select * from dbo.Orders
select * into #t2 from sys.dm_os_buffer_descriptors where database_id = db_id()
-- ile nowych stron ?
select count(*) as NowychStron
from (
select * from #t2
except
select * from #t1
) x
![]()
Tym razem widzimy wynik 29. Zobaczmy więc co to są za strony :
;with cte as (
select * from #t2
except
select * from #t1
)
select d.page_id, d.page_level, d.page_type, d.row_count, x.extent_page_id, x.is_mixed_page_allocation, OBJECT_NAME(p.object_id) as TableName , i.name
from cte d
inner join sys.dm_db_database_page_allocations (db_id(), null , null , NULL, 'DETAILED') x on d.page_id = x.allocated_page_page_id
left join sys.allocation_units a on d.allocation_unit_id = a.allocation_unit_id
left join sys.partitions p on a.container_id = p.partition_id
left join sys.indexes i on p.object_id = i.object_id and p.index_id = i.index_id
group by d.page_id, d.page_level, d.page_type, d.row_count, x.extent_page_id, x.is_mixed_page_allocation, p.object_id , i.name
order by page_id
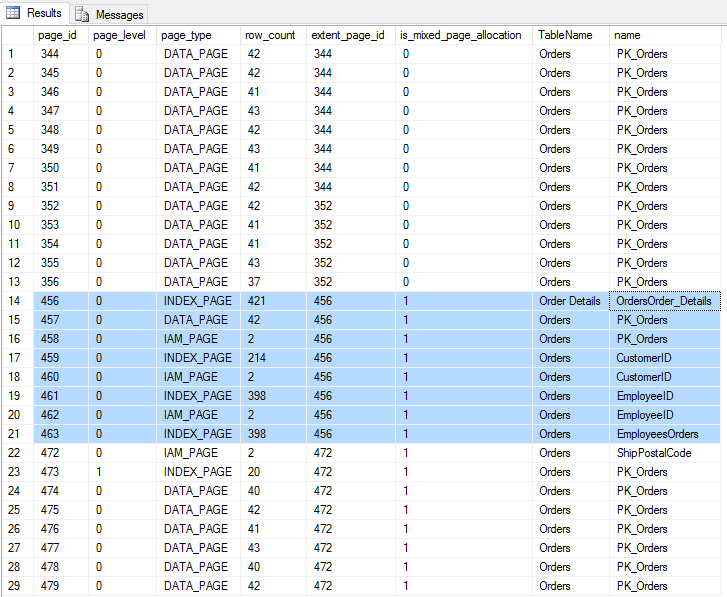
No i tu niespodzianka. Pomimo, że skanujemy indeks klastrowy PK_Orders to przeczytaliśmy przy okazji 1 stronę zupełnie z innej tabeli (Order Details) plus 6 stron indeksów które nie biorą udziału w realizacji tego zapytania. Jak łatwo się domyślić jest to efekt uboczy mechanizmu read-ahead reads. Te dodatkowe (i niepotrzebne do realizacji zapytania) 7 stron, znajduje się w ekstentach mieszanych (tutaj są to ekstenty numer 456 i 472). Trafiły do buffer cache w wyniku read-ahead reads, co oczywiście nie jest wielkim narzutem ale rozbieżność w liczbie odczytów widocznych w STATISTICS IO pozostaje faktem.
Korzystając z DMV zobaczymy faktyczną liczbę stron wczytanych do bufora :
SELECT st.text, total_logical_reads,
total_physical_reads, execution_count, last_rows
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
WHERE st.text not like '%sys%'

Możemy potwierdzić to zachowanie przechwytując informacje o odczytach za pomocą zdarzeń XE : file_read_completed i physical_page_read. Zdefniujmy sesję XE w ten sposób :
dbcc dropcleanbuffers
checkpoint
GO
CREATE EVENT SESSION [reads] ON SERVER
ADD EVENT sqlserver.file_read_completed(SET collect_path=(1)
WHERE ([sqlserver].[session_id]=( 52 ))),
ADD EVENT sqlserver.physical_page_read(
WHERE ([sqlserver].[session_id]=( 52 )))
ADD TARGET package0.event_file(SET filename=N'C:\TEMP\file_read.xel')
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
GO
ALTER EVENT SESSION [reads] ON SERVER STATE = START;
GO
SELECT * FROM dbo.Orders
GO
DROP EVENT SESSION [reads] ON SERVER
GO
SELECT Event_type, SUM(size) as Size , COUNT(*) as Events_cnt
FROM (
SELECT Event_type =n.event_xml.value('(//@name)[1]','nvarchar(max)'),
size=e.event_data_XML.value('(//data[@name="size"]/value)[1]','int'),
page_id=e.event_data_XML.value('(//data[@name="page_id"]/value)[1]','int')
FROM (
SELECT CAST(event_data AS XML) AS event_data_XML
FROM sys.fn_xe_file_target_read_file(N'C:\temp\file_read*.xel', NULL, NULL, NULL)
)e CROSS APPLY event_data_XML.nodes('//event') n (event_xml)
)q
GROUP BY Event_type
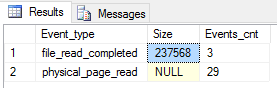
Po wykonaniu zapytania z czystym buforem, dostaniemy informacje o następującej liczbie zdarzeń (file_read_completed zawiera parametr size wyrażony w bajtach co po prostym przeliczeniu 237568 / 1024 / 8 daje dokładnie 29 stron) :
No i na koniec jeszcze jeden sposób, ostatecznie potwierdzający że 29 stron to było dokładnie tyle, ile zostało wczytanych z pliku z danymi bazy Northwind. Korzystam tutaj z fajnego narzędzia MS do monitorowania aktywności – procmon dostępnego tutaj. Kilka filtrów (proces, plik bazodanowy) i prosta matematyka daje potwierdzenie poprzedniego rezultatu (3 faktyczne operacje IO, w sumie 29 stron).

Podsumowanie i wnioski
Informacje na temat statystyk odczytu widocznych w parametrach sesji STATISTICS IO powinny być traktowane jako przybliżone. Wartości odczytów dotyczą, obiektów które są widoczne w planie wykonania (+ wyjątki dla tabel tymczasowych pośrednich i funkcji skalarnych) – lepiej więc stosować DMV jeśli chcemy widzieć dokładne wyniki. Rozbieżność nie jest duża, nie ma negatywnego wpływu na wydajność i jest logicznie wytłumaczalna.
Skanowanie indeksów klastrowych to czytanie wszystkich stron związanych z ich strukturą (leaf pages, intermediate, root, IAM’s).