Funkcje skalarne, zwracają zawsze pojedynczą wartość określonego typu. Z tego względu, można je stosować w różnych miejscach np.:
- w SELECT tworząc wyrażenia, czy pojedyncze kolumny wynikowe.
- budując warunki filtracji w WHERE, HAVING lub złączeń we FROM.
- w definicjach tabel – określając wartości domyślne kolumn lub ograniczeniach sprawdzających (CHECK CONSTRAINT)
- w innych obiektach programistycznych.
W artykule tym przedstawiam sposób tworzenia i zastosowanie skalarnych funkcji użytkownika w pisaniu zapytań SQL.
Stosowanie skalarnych funkcji użytkownika
Najlepiej wyjaśnić sens funkcji na praktycznym przykładzie.
Stwórzmy funkcję, która będzie zwracała liczbę dni roboczych pomiędzy dwoma datami.
W pracy zawodowej szczególnie raportując np. efektywność procesów musiałem po takie informacje sięgać.
Na początek wersja okrojona, aby nie komplikować zbytnio tematu i skupić się na czystej konstrukcji oraz sposobie użycia. W naszym uproszczeniu, zakładam że liczba dni roboczych pomiędzy datami, to różnica w dniach pomiędzy datą START i END, minus liczba sobót i niedziel występujących w tym przedziale czasu.
Za pomocą T-SQL możemy zapisać ten wzór w następujący sposób (dla przykładu liczba dni roboczych w marcu 2014):
SELECT (DATEDIFF(dd, '2014-03-01', '2014-03-31') + 1)
-(DATEDIFF(wk, '2014-03-01', '2014-03-31') * 2)
-(CASE WHEN DATENAME(dw, '2014-03-01') = DATENAME(dw,6) THEN 1 ELSE 0 END)
-(CASE WHEN DATENAME(dw, '2014-03-31') = DATENAME(dw,5) THEN 1 ELSE 0 END)
as WorkingDays
WorkingDays ----------- 21 (1 row(s) affected)
Jak widać, wzór ten nie uwzględnia żadnych innych dni wolnych (świąt) poza sobotami i niedzielami. W pełni funkcjonalną wersję, uwzględniającą dodatkowe dni wolne oraz szczegółowe wyjaśnienie powyższego wzoru znajdziesz tutaj.
Skoro już wiemy jak obliczyć liczbę dni roboczych, zastosujmy tą wiedzę w praktyce.
Napiszmy kwerendę, która zwróci z bazy Northwind informacje o zleceniach, które były realizowane dłużej niż 20 dni roboczych. Pokażemy informacje o tych zleceniach oraz o czasie ich realizacji dniach roboczych.
USE Northwind
GO
SELECT OrderId, OrderDate, ShippedDate, (DATEDIFF(dd, OrderDate, ShippedDate) + 1)
-(DATEDIFF(wk, OrderDate, ShippedDate) * 2)
-(CASE WHEN DATENAME(dw, OrderDate) = DATENAME(dw,6) THEN 1 ELSE 0 END)
-(CASE WHEN DATENAME(dw, ShippedDate) = DATENAME(dw,5) THEN 1 ELSE 0 END) as WorkingDays
FROM dbo.Orders
WHERE (DATEDIFF(dd, OrderDate, ShippedDate) + 1)
-(DATEDIFF(wk, OrderDate, ShippedDate) * 2)
-(CASE WHEN DATENAME(dw, OrderDate) = DATENAME(dw,6) THEN 1 ELSE 0 END)
-(CASE WHEN DATENAME(dw, ShippedDate) = DATENAME(dw,5) THEN 1 ELSE 0 END) > 20
ORDER BY WorkingDays DESC
OrderId OrderDate ShippedDate WorkingDays ----------- ---------- ----------- ----------- 10660 1997-09-08 1997-10-15 28 10777 1997-12-15 1998-01-21 28 10924 1998-03-04 1998-04-08 26 … 10788 1997-12-22 1998-01-19 21 10840 1998-01-19 1998-02-16 21 10978 1998-03-26 1998-04-23 21 (35 row(s) affected)
Przyznasz, że samo zapytanie jest długaśne i mało czytelne. Biorąc pod uwagę fakt, że informacja o liczbie dni roboczych pomiędzy datami, może się przydać wielokrotnie, warto utworzyć z tego wzoru funkcję użytkownika. Zresztą tylko w tym przykładzie, powtarzam obliczenia według tego długaśnego wzoru dwukrotnie – w WHERE oraz w SELECT.
Tworzenie i modyfikacja funkcji skalarnych
Funkcje tworzymy, modyfikujemy lub usuwamy za pomocą klasycznych konstrukcji komend DDL (Data Definition Language). Służą do tego polecenia CREATE, ALTER lub DROP FUNCTION.
Tworząc nową funkcję, można skorzystać z szablonu, dostępnego w Management Studio (prawy strzał na podkatalogu z funkcjami skalarnymi > New Scalar-Valued Function).
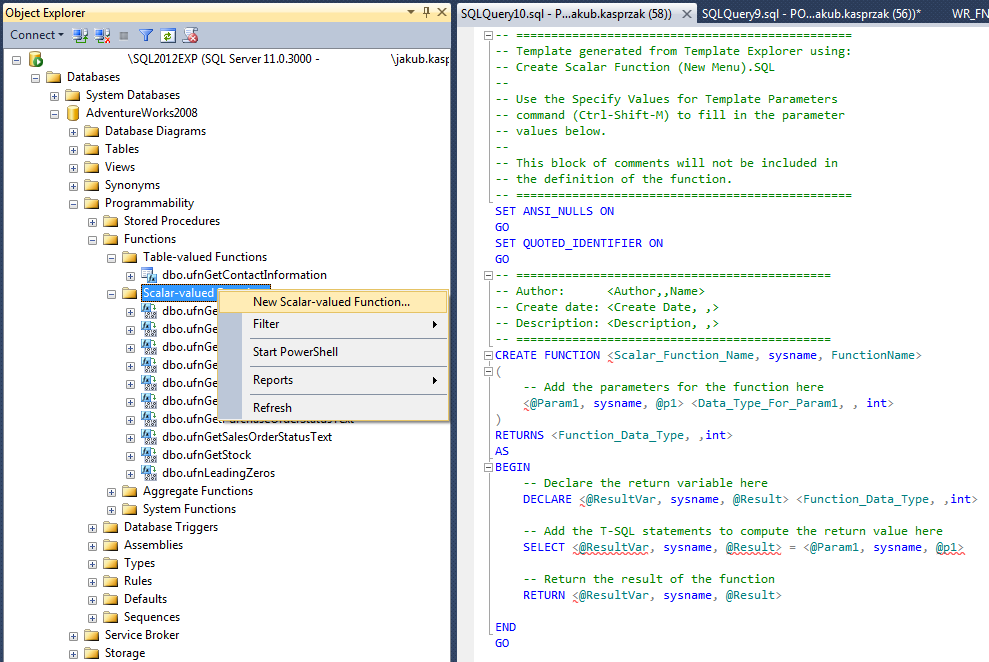
W jej definicji, po nazwie, mamy możliwość określenia parametrów wejściowych. Są opcjonalne i można ich zdefiniować całkiem sporo – max. 1024. Następnie po słowie kluczowym RETURNS, koniecznie musi znaleźć się deklaracja typu, zwracanej wartości np. całkowitej (RETURNS int).
Właściwe ciało funkcji, umieszczamy w bloku BEGIN …. END. Słowem kluczowy RETURN wywołujemy jej zakończenie – jawne zwrócenie podanej za nim wartości.
Definicję naszej nowej funkcji możemy zapisać w ten sposób :
CREATE FUNCTION dbo.LiczbaDniRoboczych
(
-- Funkcja nie uwzględnia świąt, innych dni wolnych poza sobotą i niedzielą
-- określenie parametrów wejściowych – są opcjonalne
-- u nas konieczne są dwa, określające zakres dat
@StartDate datetime,
@EndDate datetime
)
-- określenie typu zwracanej wartości (to obowiązkowo)
RETURNS int
AS
-- ciało funkcji
BEGIN
RETURN (DATEDIFF(dd, @StartDate, @EndDate) + 1)
-(DATEDIFF(wk, @StartDate, @EndDate) * 2)
-(CASE WHEN DATENAME(dw, @StartDate) = DATENAME(dw,6) THEN 1 ELSE 0 END)
-(CASE WHEN DATENAME(dw, @EndDate) = DATENAME(dw,5) THEN 1 ELSE 0 END)
END;
Nasza funkcja zawiera dwa parametry – początek i koniec zakresu dat. W wyniku jej działania, zwracana jest wartość liczbowa całkowita – typ integer.
Wywoływanie funkcji skalarnych
Korzystanie ze skalarnych funkcji użytkownika jest bardzo proste, ale trzeba pamiętać o kilku zasadach. Przede wszystkim wywołujemy je zawsze za pomocą nazwy przynajmniej dwuczłonowej, zawierającej schemat (u nas jest to dbo) w którym została utworzona.
Dzięki zastosowaniu funkcji, nasza długaśna kwerenda zostanie zgrabnie odchudzona do takiej postaci :
SELECT OrderId, OrderDate, ShippedDate,
dbo.LiczbaDniRoboczych(OrderDate, ShippedDate) as WorkingDays
FROM dbo.Orders
WHERE dbo.LiczbaDniRoboczych(OrderDate, ShippedDate) > 20
ORDER BY WorkingDays DESC
Zauważ, że funkcja ta jest deterministyczna i z uwagi na swoją prostotę (nie sięga do żadnych innych zbiorów), jej wydajność przetwarzania będzie identyczna jak w przypadku umieszczenia całej logiki w zapytaniu. Nie ponosimy, więc żadnych dodatkowych kosztów a znacznie łatwiej zarządzać takim kodem.
Wartości domyślne
Funkcje skalarne mogą mieć określone wartości domyślne dla parametrów wejściowych. Używa się ich inaczej niż w przypadku procedur składowanych. Wywołując taką funkcję musimy jawnie deklarować chęć użycia wartości domyślnej za pomocą słowa DEFAULT.
W kolejnym przykładzie, utworzymy funkcję, której zadaniem będzie konwersja liczby dziesiętnej na postać liczbową o innej podstawie.
Domyślnie będzie konwertowała zadaną liczbę na postać binarną (podstawa 2). Można też będzie podać jawnie inną podstawę (parametr @Podstawa) w zakresie 2-10.
CREATE FUNCTION dbo.KonwersjaDziesietnej
(
@LiczbaDoKonwersji bigint,
@Podstawa int = 2 -- domyślnie na binarną
)
RETURNS varchar(1000)
AS
BEGIN
-- funkcja działa poprawnie tylko dla podstawy <2-10>
IF NOT (@Podstawa between 2 and 10) RETURN -1
DECLARE @Wynik varchar(1000) = ''
WHILE @LiczbaDoKonwersji > 0 BEGIN
SET @Wynik = @Wynik + CAST((@LiczbaDoKonwersji % @Podstawa) AS varchar)
SET @LiczbaDoKonwersji = @LiczbaDoKonwersji / @Podstawa
END
RETURN REVERSE(@Wynik)
END
-- domyślnie czyli z DEFAULT konwersja liczby dziesiętnej na binarną
SELECT dbo.KonwersjaDziesietnej (54,DEFAULT) as Bitowo
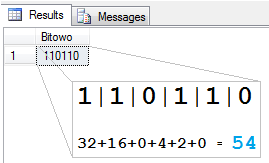
Zwróć uwagę, że tym razem pokazałem ciut większą złożoność programistyczną, którą możemy się posługiwać w definicjach funkcji. Poprzednio całość była zawarta w jednym poleceniu zwracającym wartość – RETURN(). W tym przykładzie wykonuję szereg „skomplikowanych” obliczeń 🙂 dla zwracanej przez tą funkcję wartości.
Zaprezentowane powyżej funkcje, wykonywały stosunkowo proste przekształcenia, nie sięgając właściwie do żadnych zbiorów (tabel). Oczywiście możemy wykonywać za ich pomocą znacznie bardziej złożone operacje.
Porównanie wydajności funkcji użytkownika z innymi metodami
Napiszemy teraz funkcję, która dla danego Klienta będzie zwracała wartość średnią jego zleceń. Porównamy wydajność jej działania z zapytaniem skorelowanym oraz zwykłym łączeniem tabel.
Chcemy wyświetlić zlecenia naszych Klientów, których wartość jest większa niż średnia liczona dla każdego z nich osobno.
Zadanie takie realizować może na kilka sposobów, np. za pomocą podzapytania skorelowanego :
-- Query 1 – z podzapytaniem skorelowanym
SELECT o1.CustomerID, o1.OrderID , SUM(od1.UnitPrice * od1.Quantity) as OrdValue
FROM dbo.Orders o1 INNER JOIN dbo.[Order Details] od1 on o1.OrderID = od1.OrderID
GROUP BY o1.CustomerID, o1.OrderID
HAVING SUM(od1.UnitPrice * od1.Quantity) >
(
SELECT AVG( OrdValue ) -- obliczenie średniej
FROM
(
SELECT o2.CustomerID, o2.OrderID, SUM(od2.UnitPrice * od2.Quantity) as OrdValue
FROM dbo.Orders o2 INNER JOIN dbo.[Order Details] od2 on o2.OrderID = od2.OrderID
WHERE o2.CustomerID = o1.CustomerID -- dla zleceń danego Klienta
GROUP BY o2.CustomerID, o2.OrderID
) a
)
Jednym z kluczowych problemów tego zadania, jest obliczanie średniej wartości zleceń, dla każdego z Klientów osobno. Napiszmy więc funkcję obliczającą taką wartość, która będzie przyjmowała jako parametr identyfikator Klienta.
CREATE FUNCTION dbo.CustomerAvgOrderValue
(
@CustomerID nchar(5)
)
RETURNS decimal(10,2)
BEGIN
RETURN (
SELECT AVG( OrdValue ) -- obliczenie średniej
FROM
(
SELECT SUM(od2.UnitPrice * od2.Quantity) as OrdValue
FROM dbo.Orders o2 INNER JOIN dbo.[Order Details] od2
ON o2.OrderID = od2.OrderID
WHERE o2.CustomerID = @CustomerID -- dla zleceń danego Klienta
GROUP BY o2.OrderID
) a
)
END
Teraz możemy przepisać pierwszą kwerendę, na taką, która korzysta z nowo utworzonej funkcji. Będzie z pewnością bardziej czytelna, ale sprawdźmy co stanie się z wydajnością.
-- Query 2 – z użyciem funkcji skalarnej
SELECT o1.CustomerID, o1.OrderID , SUM(od1.UnitPrice * od1.Quantity) as OrdValue
FROM dbo.Orders o1 INNER JOIN dbo.[Order Details] od1 ON o1.OrderID = od1.OrderID
GROUP BY o1.CustomerID, o1.OrderID
HAVING SUM(od1.UnitPrice * od1.Quantity) > dbo.CustomerAvgOrderValue(o1.CustomerID)
go
Na pierwszy rzut oka, analizując plany wykonania i statystykę odczytów, włączone za pomocą polecenia
SET STATISTICS IO ON
wydaje się że poprawiliśmy dzięki niej wydajność (i to znacznie) :
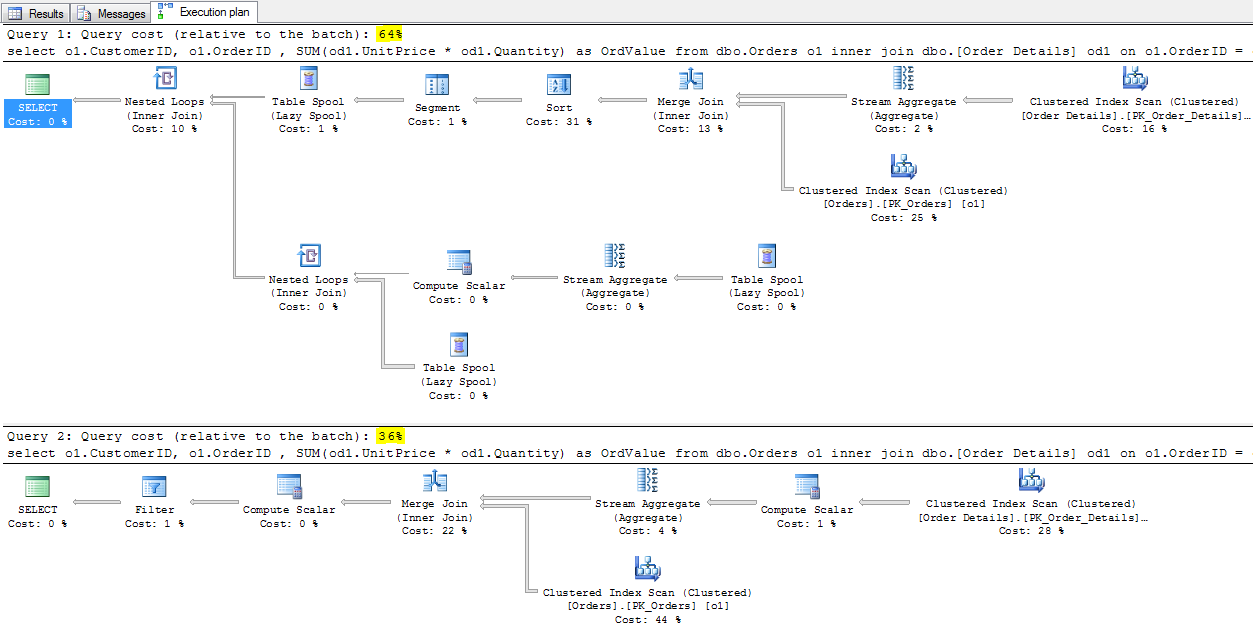
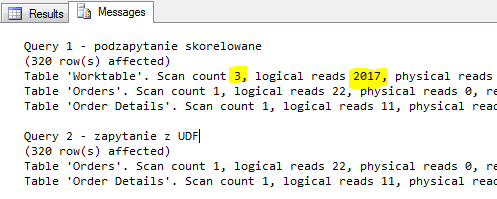
Jeśli przyjrzymy się czasowi wykonania kwerendy i analizie statystyk IO za pomocą np. Profilera lub Extended Events, wynik okaże się znacznie gorszy. Co więcej widać że zdarzają się sytuację w których nie można polegać na prezentowanym planie wykonania zapytania i tylko dogłębna analiza wydajności doprowadzi nas do prawdy o tym co jest grane. Więcej na ten temat znajdziesz w artykule dotyczącym pomiarów wydajności zapytań.
CREATE EVENT SESSION queryperf ON SERVER
ADD EVENT sqlserver.sql_statement_completed
ADD TARGET package0.event_file(SET filename=N'D:\PerfTest\PerfTest.xel',
max_file_size=(2),max_rollover_files=(100))
WITH ( MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_MULTIPLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=120 SECONDS,MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON);
ALTER EVENT SESSION [queryperf] ON SERVER STATE = START;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
SELECT /* Query1 */ o1.CustomerID, o1.OrderID , SUM(od1.UnitPrice * od1.Quantity) as OrdValue
FROM dbo.Orders o1 INNER JOIN dbo.[Order Details] od1 on o1.OrderID = od1.OrderID
GROUP BY o1.CustomerID, o1.OrderID
HAVING SUM(od1.UnitPrice * od1.Quantity) >
(
SELECT AVG( OrdValue ) -- obliczenie średniej
FROM
(
SELECT o2.CustomerID, o2.OrderID, SUM(od2.UnitPrice * od2.Quantity) as OrdValue
FROM dbo.Orders o2 INNER JOIN dbo.[Order Details] od2 on o2.OrderID = od2.OrderID
WHERE o2.CustomerID = o1.CustomerID -- dla zleceń danego Klienta
GROUP BY o2.CustomerID, o2.OrderID
) a
)
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
SELECT /* Query2 */ o1.CustomerID, o1.OrderID , SUM(od1.UnitPrice * od1.Quantity) as OrdValue
FROM dbo.Orders o1 INNER JOIN dbo.[Order Details] od1 ON o1.OrderID = od1.OrderID
GROUP BY o1.CustomerID, o1.OrderID
HAVING SUM(od1.UnitPrice * od1.Quantity) > dbo.CustomerAvgOrderValue(o1.CustomerID)
DROP EVENT SESSION queryperf ON SERVER;
SELECT *
FROM (
SELECT duration=e.event_data_XML.value('(//data[@name="duration"]/value)[1]','int')
, cpu_time=e.event_data_XML.value('(//data[@name="cpu_time"]/value)[1]','int')
, physical_reads=e.event_data_XML.value('(//data[@name="physical_reads"]/value)[1]','int')
, logical_reads=e.event_data_XML.value('(//data[@name="logical_reads"]/value)[1]','int')
, writes=e.event_data_XML.value('(//data[@name="writes"]/value)[1]','int')
, statement=e.event_data_XML.value('(//data[@name="statement"]/value)[1]','nvarchar(max)')
, TIMESTAMP=e.event_data_XML.value('(//@timestamp)[1]','datetime2(7)')
, *
FROM (
SELECT CAST(event_data AS XML) AS event_data_XML
FROM sys.fn_xe_file_target_read_file(N'D:\PerfTest\PerfTest*.xel', NULL, NULL, NULL)
)e
)q
WHERE q.[statement] LIKE '%Query%'
ORDER BY q.[timestamp] ASC

Podsumowanie
Funkcje skalarne przede wszystkim poprawiają czytelność i wygodę pisania zapytań. Korzystać z nich należy z rozwagą, bo zazwyczaj wykonywane będą dla każdego rekordu niezależnie. Czasem analiza wydajności i wykorzystania ich, wymaga dokładnego sprawdzenia w jaki sposób silnik wykonuje naszą kwerendę. Pochopne wnioski (dziękuję @GRUM za erratę :)) mogą prowadzić do błędnych wniosków i w konsekwencji poważnych problemów wydajnościowych.
niezla pracka
W stworzonej funkcji mam kilka parametrów, które zawsze będą odwoływać się do tych samych kolumn. Chciałbym za wszelką cenę nie wprowadzać za każdym razem wszystkich parametrów od nowa i zastawiam się czy można ustawić kolumnę (jej wartości) jako wartość domyślna parametru przykładowo:
create function …
(…
@data1 datetime = … (baza.tabela.kolumna?)
)
LUB czy można to wprowadzić w dalszej treści funkcji poprzez:
SET @data1 datetime = …
Niestety w Internetach nie znalazłem rozwiązania, a nie wiem jaka może być składnia i czy jest w ogóle dozwolone. Będę wdzięczny za podpowiedź.
Swoją drogą gratuluję wykonania kursu – prościej i logiczniej nie da się tego zrobić. Jestem tu stałym bywalcem 🙂
Można ale tu musiałbyś użyć funkcji typu multistatement w której możesz ująć niemal dowolną logikę czyli np. zapytania które będą Ci ustawiały wartości parametrów 🙂
Świetna strona i wykład. Bardzo klarowne i logiczne przykłady.
Proszę tylko zwrócić uwagę (co oczywiście nie ma związku z kursem ale może ktoś chciałby to wykorzystać), że funkcja dbo.LiczbaDniRoboczych w swojej konstrukcji nie sprawdza się dla niektórych okresów (np. pierwszy i ostatni dzień stycznia 2015). Lepiej byłoby chyba sprawdzać niepełne weekendy (czy pierwszy dzień to niedziela lub ostatni to sobota) i odpowiednio korygować zakres.
Pozdr.
Dzięki takim komentarzom, ten kurs jest coraz lepszy 🙂 uprościłem nieco tą funkcję i poprawiłem przy okazji błąd. Pozdrawiam !
Z planami wykonania jeśli używasz funkcję to nie jest tak kolorowo. Niestety prawda jest taka, że w tym przypadku plan kłamie w żywe oczy. Że kłamie to byłoby widać jakbyś użył statystyk czasowych
przed porównywaniem zapytań – dodaj SET STATISTICS TIME ON przed porównaniem.
U mnie jest to różnica
a) bez funkcji
SQL Server Execution Times:
CPU time = 218 ms, elapsed time = 250 ms.
b) z funkcją
SQL Server Execution Times:
CPU time = 1420 ms, elapsed time = 1465 ms.
Jak widać można zrobić sobie dużą krzywdę i zabić niejeden serwer używając takich funkcji.
Elegancko wyjaśnione na: http://sqlinthewild.co.za/index.php/2009/04/29/functions-io-statistics-and-the-execution-plan/
Masz rację, z przekłamanymi planami można spotkać się często podobnie jak statystykami IO (!). Profiler czy Trace w kwestii mierzenia wydajności i prawdy o IO jest chyba najlepszym rozwiązaniem. Dzięki za komentarz i pozdr !
A teraz w drugą stronę
Obydwa podejścia są bardzo fajne i sprytnie wykorzystujesz rekurencję CTE w konwersji na BIN.
To drugie można by było jeszcze ciut zmodyfikować o pełen zakres liczb (w obecnej formie działa świetnie dla liczb jednobajtowych).
Prawda. Zamiast wykorzystywać pole high można tak.
Konwersja dziesiętnej – ciekawostka dla kombinatorów 😉
with cte as ( select 54 as x, cast('' as varchar) as wynik union all select x = x/2, wynik = cast(wynik + CAST((x % 2) AS varchar) as varchar) from cte where x > 0 ) select REVERSE(wynik) as Bitowo from cte where x = 0