Zanim rozpoczniesz przygodę z językiem SQL, warto abyś poznał ogólną koncepcję środowiska bazodanowego dla którego język ten został opracowany.
Relacyjne bazy danych to tylko jeden z istniejących i komercyjnie obecnych modeli. Można spotkać bazy obiektowe, grafowe czy NoSQL. Jednak model relacyjny zdobył największą popularność.
Opracowany w latach 70-tych ubiegłego wieku, jest już dojrzałym 40-latkiem ! Warto go poznać, ponieważ z pewnością spotkasz jego wdrożenia praktycznie w każdej firmie. Opisywane tutaj podstawy, dotyczą wszystkich implementacji relacyjnych baz danych. W szczególności takich systemów jak MS SQL Server, Oracle, MySQL, PostgreSQL, DB2 czy Teradata.
Pełne zrozumienie całej teorii projektowania baz danych, nie jest niezbędne do opanowania techniki pisania zapytań SQL. Przydaje się jednak w unikaniu błędów logicznych i bardziej świadomym pisaniu kwerend, dlatego polecam zapoznie się z podstawami jako dobry wstęp do kursu SQL.
W artykule tym przedstawię tylko fundamentalne, podstawowe pojęcia, związane z relacyjnymi bazami danych. Niektóre z nich stosować będę wymiennie w dalszej części kursu (np. kolumna / atrybut).
Postaram się ograniczyć zakres teorii do minimum. Z drugiej strony, nie jestem pewien czy tak skondensowana forma wiedzy będzie zrozumiała (jeśli nie – koniecznie dajcie mi znać). Tak czy siak, uważam że jest ona niezbędna do zbudowania odpowiedniego obrazu przestrzeni w której będziemy się poruszać w trakcie tego kursu.
Jeśli chodzi o zagadnienia bezpośrednio związane z pisaniem zapytań – największą uwagę skup proszę na matematycznej teorii zbiorów, którą przywołuję tutaj kilkukrotnie. Jest ona podstawą modelu relacyjnego.
Teoria relacyjna, Model ER oraz relacyjny
Fundamentem relacyjnych baz danych jest teoria relacyjna, przedstawiona przez Franka Edgara Codda w 1970 roku.
Projekt każdej relacyjnej bazy danych, rozpoczyna etap konceptualny (abstrakcyjny), opierając się o model E-R (Entity-Relationship Model), którego autorem jest dr. Peter Chen.
Jest to opis czysto teoretyczny, wymagający przełożenia na język praktyki. Ma on na celu, opisanie fragmentu rzeczywistości za pomocą związków encji. W tym modelu używamy definicji, które mają swoje odzwierciedlenie na późniejszym etapie – wdrożenia projektu w życie.
W terminologii dotyczącej relacyjnych baz danych, pojawia się często wiele pojęć z różnych płaszczyzn, modeli i będę starał się w tym artykule je przybliżyć i usystematyzować. Taki jest w zasadzie główny cel tej publikacji.
Krótki rzut oka na nomenklaturę podstawowych obiektów bazodanowe w różnych terminologiach. Od czystej teorii – do wdrożenia.
| Teoria relacyjna | Model ER | Relacyjne bazy | Aplikacje |
| Relacja | Encja | Tabela | Klasa |
| Krotka | Instancja | Wiersz | Instancja klasy (obiekt) |
| Atrybut | Atrybut | Kolumna | Właściwość, atrybut |
| Dziedzina | Dziedzina/Typ | Typ danych | Typ danych |
W dalszej części, będę przedstawiał pojęcia w uporządkowanym kierunku – zawsze od postaci konceptualnej (model E-R) do praktycznej (model relacyjny), spotykanej w konkretnej implementacji środowiska relacyjnego np. MS SQL Server.
RELACYJNA BAZA DANYCH
Zgodnie z modelem E-R, to zbiór schematów RELACJI i ZWIĄZKÓW między nimi. Czyli struktur służących do przechowywania danych w ściśle zorganizowany sposób.
W praktyce będzie to zawsze zbiór tabel, w których przechowywane są dane. Ponadto tabele, posiadać będą określone powiązania (relacje) między sobą.
RELACJA
W modelu E-R, to po prostu TABELA czyli struktura, przechowująca informacje o obiektach określonego typu. Używając języka programistów – KLASA obiektów określonego typu.
KLASA ENCJI, RELACJA (Model ER) = TABELA (RDBMS) = KLASA (języki obiektowe)
Tabela (inaczej encja, klasa obiektów, relacja) – to podstawowa struktura modelowania niezależnych, odrębnych obiektów, o których informacje chcemy przechowywać w bazie.
Każda tabela powinna przechowywać informacje jedynie o ściśle określonych obiektach konkretnego typu. Na przykład informacje dotyczące pracowników (tabela Pracownicy), albo tylko samochodów, zamówień, produktów itp. – każda typ = nowa tabela . Informacje w ramach tabeli, powinny być więc jednorodne ze względu na typ obiektu którego dotyczą.
Samo określenie RELACJA w nomenklaturze języka polskiego, może być trochę tutaj mylące. W końcu RELACJA i ZWIĄZEK to synonimy a jak widać dotyczą dwóch zupełnie różnych światów RELACJA=TABELA a ZWIĄZEK to tak naprawdę RELACJA :).
ATRYBUT
Każda RELACJA jest opisana za pomocą zbioru ATRYBUTÓW. Warto dodać że ten zbiór powinien być zawsze minimalny, niezbędny do realizacji celów biznesowych.
Każdy z ATRYBUTÓW należy do określonej DZIEDZINY, czyli może przyjmować określone wartości (np. liczbowe, tekstowe, daty etc.) oraz posiada unikalną w ramach RELACJI nazwę.
ATRYBUT w praktyce, to nic innego jako KOLUMNA. Zatem tłumacząc na model relacyjny, każda TABELA opisana jest za pomocą zbioru KOLUMN. Każda KOLUMNA jest ściśle określona TYPEM DANYCH, czyli przechowuje wartości jednorodne, z określonej DZIEDZINY (tego samego typu np. liczby, znaki, daty etc). Nazwa kolumny w ramach tabeli musi być unikalna, bo silnik musi jednoznacznie wiedzieć do którego atrybutu będziemy się odnosić.
ATRYBUTY danej RELACJI, tworzą zbiór nieuporządkowany. Ich kolejność w teorii nie ma żadnego znaczenia. Sami decydujemy które z nich są w danym momencie dla nas istotne i w jakiej kolejności chcemy je zobaczyć (SELECT). Teraz małe ćwiczenie – wytęż wzrok i znajdź różnice pomiędzy zbiorem 1 a 2 :
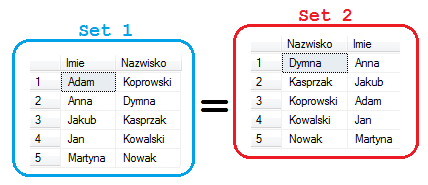
Zgodnie z teorią zbiorów, oba SETy są takie same ! Nie ma znaczenia ani kolejność atrybutów opisujących elementy, ani kolejność elementów (wierszy) w zbiorze.
Poza tymi własnościami, warto dodać, że wartość danego atrybutu powinna być zawsze atomowa, czyli niepodzielna. Jest to jedna z właściwości dobrze znormalizowanych baz. Temat ten opisuję w dedykowanym artykule na temat projektowania i normalizacji baz danych.
SCHEMAT RELACJI
To po prostu jej definicja. Czyli informacja o strukturze, ATRYBUTACH które opisują daną RELACJĘ.
W praktyce będzie to struktura tabeli – czyli informacja przez jakie kolumny, jakiego typu jest ona opisana. Mówimy więc o specjalnym typie informacji. Schematy relacji to tzw. metadane czyli informacje o strukturach w bazie danych. Więcej na temat metadanych w SQL Server znajdziesz np. w artykule na temat widoków systemowych.
KROTKA
To pojedynczy egzemplarz, czyli obiekt opisany wszystkimi ATRYBUTAMI danej RELACJI. KROTKA to nic innego jak WIERSZ czy REKORD. W języku programistów możemy mówić o EGZEMPLARZU danej KLASY.
Każda tabela to zbiór wierszy. Zgodnie z matematyczną teorią zbiorów, każdy z definicji jest nieuporządkowany. Stąd każda tabela to zbiór elementów (wierszy) w którym zakładamy, że kolejność nie jest ustalona. W praktyce może być wymuszona np. przez klucz podstawowy czy mechanizmy składowania danych, ale w rozważaniach i działaniach musimy zawsze patrzeć przez pryzmat teorii. Jeśli chcesz, żeby wiersze były uporządkowane – trzeba to w zapytaniu określić (np. sortowanie przez ORDER BY) lub świadomie stosować mniej lub bardziej jawne mechanizmy, które ją zapewnią (np. indeks klastrowy).
Teoria zbiorów, mówi o jeszcze jednej bardzo ważnej zasadzie. Braku duplikatów w zbiorze.
Wartość informacyjna każdego duplikatu w zbiorze jest równa zero. Co więcej wprowadza dużo zamieszania. Jak obsłużyć sytuację, kiedy chcielibyśmy zmodyfikować tylko jeden z nich? Jak mielibyśmy wskazać ten o który nam chodzi skoro są identyczne?
Oczywiście możemy przechowywać wiele takich samych obiektów, ale każdy z nich powinien być jednoznacznie identyfikowalny. Na przykład mamy 100 identycznych samochodów, tego samego rocznika z tym samym wyposażeniem, kolorem etc. ale identyfikowane jednoznacznie za pomocą numeru VIN. SQL Server dopuszcza możliwość tworzenia zduplikowanych rekordów, ale z punktu widzenia teorii jest to niezgodne z zasadami i rodzi same problemy.
KLUCZE
Klucze to zbiory atrybutów mających określoną właściwość. Dzięki nim, możemy jednoznacznie identyfikować każdy pojedynczy wiersz. Znajomość pojęć kluczy podstawowych i obcych jest niezbędna do tworzenia zapytań, odwołujących się do wielu tabel. Możesz się spotkać z następującymi pojęciami typów kluczy :
SUPERKLUCZ (NADKLUCZ)
Superkluczem nazywamy dowolny podzbiór atrybutów, identyfikujący jednoznacznie każdy wiersz. Każda RELACJA (tabela) może zawierać wiele takich kluczy. Szczególnym przypadkiem jest superklucz składający się ze wszystkich atrybutów (kolumn) danej tabeli.
KLUCZ KANDYDUJĄCY
To dowolny z SUPERKLUCZY, mogący zostać kluczem podstawowym. W implementacji bazy danych, w praktyce nie istnieje jako niezależny osobny (zmaterializowany byt) jako taki. Jest to tylko założenie teoretyczne.
KLUCZ PODSTAWOWY (PRIMARY KEY)
To wybrany (zazwyczaj najkrótszy), jednoznacznie identyfikujący każdy, pojedynczy wiersz, zbiór atrybutów (kolumn) danej relacji (tabeli). Jest to pierwszy z wymienionych do tej pory kluczy, któy ma faktyczne, fizyczne odwzorowania w implementacji bazy danych. Każda tabela może mieć tylko jeden taki klucz.
W odniesieniu do klucza podstawowego, możesz spotkać określenie KLUCZ NATURALNY i SZTUCZNY. Kluczem naturalnym, będzie kolumna (lub zbiór kolumn) opisująca daną klasę obiektów – np. NIP. Jest to atrybut, który z punktu widzenia systemu postrzegany jest tak samo naturalnie jak Nazwa firmy czy jej REGON. W rzeczywistości jednak jest to nadany identyfikator sztuczny, ale jest on na tyle powszechny, że możemy traktować go jako klucz naturalny. Innym przykładem klucza naturalnego może być adres email użytkownika systemu. Przeważnie zakładamy, że dwóch użytkowników nie może mieć takiego samego adresu.
Klucz sztuczny to zazwyczaj dodatkowa kolumna stworzona przez projektanta bazy danych w celu identyfikacji rekordów, możliwie krótkim kluczem. Zazwyczaj będzie to wartość liczbowa typu całkowitego (INT, SMALLINT, BIGINT). Jest to związane z wydajnością, lub innymi aspektami które zasługują na osobny artykuł.
Najważniejsze jest to, żeby klucz podstawowy unikalnie identyfikował rekordy i był możliwie krótki.
KLUCZ OBCY
To atrybut lub zbiór atrybutów, wskazujący na KLUCZ GŁÓWNY w innej RELACJI (tabeli). Klucz obcy to nic innego jak związek, relacja między dwoma tabelami.
Cecha dobrego klucza głównego (możliwie krótki) tutaj staje się klarowna. W tabeli powiązanej kluczem obcym, trzeba powielić tą strukturę (zbiór atrybutów) aby móc jednoznacznie wiązać rekordy z dwóch tabel.
Definicja klucza obcego, pilnuje aby w tabeli powiązanej, w określonych atrybutach, znaleźć się mogły tylko takie wartości które istnieją w tabeli docelowej jako klucz główny. Klucz obcy może dotyczyć również tej samej tabeli.
Powiązania pomiędzy tabelami (związki pomiędzy relacjami)
Omawiane do tej pory zagadnienia, są związane bezpośrednio z samą strukturą przechowywania danych w oderwaniu narazie od innych tabel (RELACJI). W praktyce spotkać możemy trzy fundamentralne związki między tabelami. Dzięki nim, możemy zapewnić integralność referencyjną danych i zamodelować odpowiednią logikę naszej struktury. Abstrahując od szczegółowej analizy wszystkich rodzajów związków jakie są możliwe w modelu E-R (opcjonalne, obowiązkowe, tetralne), skupimy się tylko na binarnych – czyli dwuargumentowych.
Wiedzę o ich istnieniu i sposobie modelowania wykorzystamy chociażby w pisaniu zapytań do wielu tabel.
ZWIĄZEK 1:1 (jeden do jeden)
Każdy wiersz z tabeli A może mieć tylko jednego odpowiednika w tabeli B (i na odwrót)
Ten rodzaj relacji może być postrzegany jako podzielenie tabeli na dwie (bo relacja jest jeden do jeden). Stosowany np. wtedy, gdy zbiór dodatkowych atrybutów jest określony tylko dla wąskiego podzbioru wierszy w tabeli podstawowej.
Przykładem mogą być RELACJE pochodne. W bazie AdventureWorks2008 znajdziemy następujący przykład :
Tabela Person.Person jest relacją główną, przechowującą informacje o osobach. Tabela Employee jest relacją pochodną, w której dla części z osób, o których mamy wiedzę w tabeli Person.Person są określone dodatkowe atrybuty. Każdy pracownik jest przecież osobą w naszym modelu, ale tylko część z osób jest pracownikami. Jeden pracownik nie może być jednocześnie dwoma osobami, a jedna osoba dwoma pracownikami (w tym modelu rzeczywistości).
Innym zastosowaniem związku 1:1, jest wydzielenie pewnej grupy atrybutów które są rzadko odpytywane. Mogą być, więc umiejscowione w tabeli przechowywanej na osobnym wolniejszym, nośniku danych.
Kolejny scenariusz to dodatkowa ochrona części atrybutów określonego typu (np. informacji wrażliwych takich jak wynagrodzenie, preferencje etc.). Wydzielając je do osobnej tabeli, możemy zapewnić dodatkowy poziom zabezpieczeń (dostęp, szyfrowanie), inną politykę backupową etc..
ZWIĄZEK 1:N (jeden do wiele)
Jest to najczęściej spotykana relacja. Określamy w niej że każdy element ze zbioru A (wiersz tabeli A), może być powiązany z wieloma elementami zbioru B. Przykład z bazy Northwind – Produkty i Kategorie. W tym modelu wiele produktów może należeć do jednej kategorii.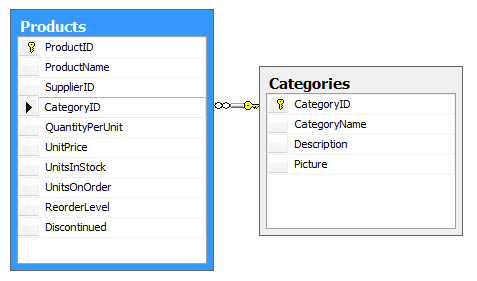
Można sobie wyobrazić inny scenariusz. Chcielibyśmy aby jeden produkt był w wielu kategoriach. Wtedy konieczne byłoby zastosowanie ostatniego z możliwych rodzajów związków – wiele do wiele.
ZWIĄZEK N:M (wiele do wiele)
Realizowana jest zawsze jako dwie relacje 1:N. Zatem jeśli chcemy między dwoma tabelami zamodelować związek N:M potrzebujemy trzecią tabelę – łącznikową. Przykładem niech będzie fragment każdego systemu zamówień, np. taki jak w bazie NorthWind. Mamy zamówienia i produkty. Każdy z produktów może być zamawiany wielokrotnie, w różnych zamówieniach. Każde z zamówień może zawierać wiele pozycji (produktów). Tabelą łączącą, realizującą relacje 1:N będzie tu tabela Order Details.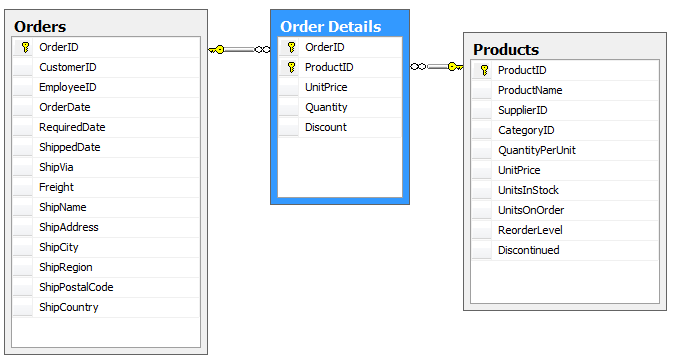
Podsumowanie
Teoria relacyjnych baz danych jest dobrym tematem na osobny kurs. Jej znajomość jest szczególnie konieczna dla projektantów struktur, architektury bazy danych. Ponieważ artykuł ten jest częścią kursu z pisania zapytań SQL, ograniczyłem się tylko do najważniejszych, fundamentalnych zagadnień.
” Ma on na celu, opisanie fragmentu rzeczywistości za pomocą związków encji. ”
Probujesz wytlumaczyc cos, uzywajac terminu „encja”, ale co to jest encja?
Dziękuję za wysiłek włożony w stworzenie tego artykułu. To budyjące, że są osoby, które potrafią pisać o trudnych rzeczach w sposób prosty:). Przecież żeby napisać SMSa nie trzeba znać teorii nazw jak sądzą niektórzy z moich przedmówców :). Nie dajmy się zwariować. Nie zawsze jest potrzebna armata na wróble. Dziękuję raz jeszcze i oby więcej takich przystępnych telstów.
Super artykuł 🙂 Szczególnie podoba mi się przedstawienie tabeli jako klasy. Wcześniej nie patrzyłem raczej na bazy danych przez pryzmat klas i obiektów. Teraz wszystko stało się bardziej jasne i łatwiejsze do skojarzenia.
Bardzo pomocny, przystępny artykuł. Dzięki! 🙂
1. Tak, klucz główny = podstawowy (PRIMARY KEY)
2. Tabela w której masz ID obiektu i ID obiektu nadrzędnego będącego obiektem tej samej klasy (np. tabela pracownicy z kolumnami IdPracownika oraz IdManagera (który to właśnie jest tym kluczem obcym FK>PK). Każdy Manager też jest przecież pracownikiem.
3. 1:1 tutaj klucz obcy = klucz podstawowy (np. BusinessEntityId z tabeli Employee jest kluczem głównym w tabeli Employee a zaraz kluczem obcym z tabeli Person i odwrotnie :-))
N:M tutaj – podobnie jak w relacjach 1:N tabela OrderDetails posiada dwa klucze obce – OrderId (będący kluczem podstawowym w tabeli Orders) oraz ProductId (będący kluczem podstawowym w tabeli Products)
Cześć Jakub. Chciałam podpytać się o relację 1:1, bo w tej chwili nie pamiętam, jak z punktu projektowego rozwiązuje się sprawę powiązania encji za pomocą kluczy podstawowych i obcych. W Accessie wiążemy ze sobą dwa klucze podstawowe i to z zasady działa. Przy relacyjnych bazach danych (ogólnie) często jest tak, że faktycznie wiąże się referencyjnie klucz obcy z kluczem podstawowym. Czy w relacji jeden do jednego też tak jest?
Jak z punktu widzenia kodu SQL to się wzorcowo robi? Kiedyś to robiłam, ale już nie pamiętam…
Jesteś w stanie odpowiedzieć na to pytanie?
Witam, mam dwa pytania.
1) Co to jest Klucz główny? Pisząc o kluczu obcym posłużyłeś się pojęciem „Klucz Główny”, ale nie podałeś definicji. Intuicja mi podpowiada, że Klucz Główny to synonim Klucza Podstawowego (Primary Key). Proszę o potwierdzenie/wyjaśnienie.
2) Cyt. „Klucz obcy może dotyczyć również tej samej tabeli.” Prosiłbym o podanie przykładu wyjaśniającego taką sytuację.
Proszę również podać, które atrybuty to klucze obce w relacjach pokazanych w prezentowanych przykładach:
a) związek 1:1
b) związek N:M, tabela „łącznikowa” Order Details.
Co do 2. to przykładem jest tabela pracowników, która zawiera odniesienie do przełożonego który jest również pracownikiem
Mógłbyś wyjaśnić po co konkretnie jest ta trzecia tabela pomocnicza w N:M? Nie widzę tego. Dlaczego wystąpić mogą tylko dwie relacje?
Tabele „Orders” i „Products” nie mają wspólnych kolumn, więc nie można ich powiązać ze sobą tak bezpośrednio. Do tego potrzebna jest pomocnicza tabela „Orders Details”, która zawiera w sobie kolumny „zapożyczone” z obu wspomnianych tabel. Czyli jest łącznikiem między nimi. Działa tak jak „wtyczka-przejściówka” pomiędzy niepasującymi do siebie kablami w elektronice.
Super, dzięki za komentarz. Pomogłeś mi zrozumieć co to jest tabela łącznikowa. Właśnie modeluje bazę dla apteki internetowej z częścią magazynową.
Oto chodziło 😉
Dobrze jest zajrzeć najpierw do linku projektowanie i normalizacja bazy danych.
Poza tym jakbyś chciał przedstawić, że masz zamówienie na co najmniej dwa produkty. Musiałbyś powielić tabelę Products. Doszłoby do rendundacji, nadmiarowości, co skutkowałoby większym zużyciem miejsca pamięci bazy, w związku z powieleniem tylu pól, lepiej zastosować oddzielną tabelę.
„W praktyce będzie to zawsze zbiór tabel, w których przechowywane są dane. Ponadto tabele, posiadać będą określone powiązania (relacje) między sobą.” Tutaj relacja jest związkiem. Wszędzie indziej relacja jest tablicą.
Ech, właśnie zaczęłam czytać artykuł dokładniej i błędów jest sporo:
– Cała pierwsza tabelka.
Model ER.. | Model relacyjny | implemetacja postrelacyjna | implementacja obiektowa
—————————————————————————————————————————————–
Encja ………. | Relacja……………… | Tabela……………………………………. | Klasa/ interfejs
Instancja…. | Krotka……………… | Wiersz…………………………………… | Obiekt
Deskryptor | Atrybut………………. | Kolumna…………………………………. | Pole
Dziedzina.. | Dziedzina…………. | Typ danych…………………………… | Typ danych
– „ATRYBUT w praktyce, to nic innego jako KOLUMNA. Zatem tłumacząc na model relacyjny, każda TABELA opisana jest za pomocą zbioru KOLUMN” Autor po drodze zmieszał model relacyjny z implementacją fizyczną. Kwestię wyjaśnia tabela powyżej.
– Definicje kluczy są nieścisłe – i mogą generować niezrozumienie problemu, co znacyz najkrótszy, co znaczy identyfikujący jednoznacznie. Po matematycznemu: Klucz to zbiór atrybutów o własnościach: unikatowe, niepuste i niepodzielne. Czyli wartości w poszczegołnych krotkach, dla całej kombinacji atrybutów są niepowtarzalne, nie mogą przyjąć wartości pustej i nie możemy wyłonić podzbioru z tych atrybutów, który nadal byłby unikatowy.
– Co oznacza w definicji „KLUCZ OBCY To atrybut lub zbiór atrybutów, wskazujący na KLUCZ GŁÓWNY w innej RELACJI (tabeli)” słowo wskazujący. Pisząc o informatyce jaka jest przedmiotem ścisłym należy się wyrażać ściśle. Klucz obcy to zbiór atrybutów jednej relacji, który posiada wartości w zbiorze atrybutów, będących kluczem głównym (a w teorii także kandydującym) drugiej lub tej samej relacji. Tak, tak, klucz obcy może odnosić się do tej samej relacji.
– Pokazana jest ograniczona wiedza o związkach. Brak informacji na temat związków unarnych, binarnych i tych będących zmorą każdego projektanta: ternarnych. Brak informacji o związkach obligatoryjnych i opcjonalnych.
Autor ma dużą wiedzę i na pewno sporą intuicję, ale też bałagan wiedzy, którą sprzedaje innym…
Na koniec smaczek „Pełne zrozumienie całej teorii projektowania baz danych, nie jest niezbędne do opanowania techniki pisania zapytań SQL. ”
Dodam: nie jest niezbędne do opanowania pisania byle jakich zapytań, które nie zawsze będą działać, a w określonych sytuacjach będą dawać przypadkowe wyniki…
Bardzo Ci dziękuję za tak wnikliwą recenzję. Niewiele osób zwraca taką uwagę na detale jak Ty – jestem pod wrażeniem ale jednocześnie też jestem zaskoczony, że potraktowałaś ten artykuł jak pracę naukową 🙂
Dobrze wiesz, że w dwóch czy trzech paragrafach nie da się ująć całej teorii, fundamentów projektowania systemów baz danych. Artykuł ten miał na celu wprowadzenie kilku niezbędnych elementów toerii (mocno zresztą uproszczonych – co na wstępie zaznaczałem), aby móc odnaleźć się w rzeczywistości świata baz danych. Z pewnością nie jest to kurs adresowany do studentów przygotowujących się do egazminu z przedmiotu „Teoria baz danych”. Kwestią dyskusyjną jest pytanie czy można tak upraszczać i „sprzedawać” wiedzę w okrojonym zakresie. Chyba zgodzisz się jednak, że inaczej prowadzi się kursy dla studentów, informatyków a inaczej dla osób pracujących w księgowości czy manager’ów.
Nasuwa mi się pewien cytat, który był wyryty w sali do matematyki w szkole do której chodziłem „Matematyka to królowa wszystkich nauk, jej ulubieńcem jest prawda, a prostość i oczywistość jej strojem”. Fajne prawda ? Bardzo mi się podabał – jest taki prawdziwy ! Niestety nie dla wszystkich.
Język matematyki bywa dużym wyzwaniem dla wielu ludzi a narzędzia, jak właśnie język SQL, zostały stworzone też dla osób które nie muszą być ani informatykami, ani matematykami aby móc z nich korzystać. Nie zgodzę się z Tobą, że bez całej tej teorii, wyniki ich zapytań będą nieprzewidywalne 🙂 W większości firm, pracują ludzie którzy muszą umieć korzystać z tego typu narzędzi. Wykładanie teorii relacyjnej w pełnym zakresie, czy opisywanie wszelkich możliwych związków, używania wzorów aby wyrazić zależności funkcyjne… wybacz, ale z doświadczenia wiem że mija się to z celem („Pokaż mi ostatnie zlecenia dla klienta X”) czy nam się to podoba czy nie.
Kurs, którego częścią jest ten artykuł, ma na celu przekazać podstawową wiedzę w naprawdę prosty sposób. Czytałaś może artykuł o normalizacji ? Ani jednego wzoru ! To było dopiero wyzwanie i cel tego kursu.
Dziękuję raz jeszcze za komentarz i serdecznie pozdrawiam !
W różnych opracowaniach internetowych oraz w książkach poświęconych zagadnieniu baz danych, w odmienny sposób tłumaczy się znaczenie przymiotnika „relacyjna” (baza danych). Niektórzy autorzy twierdzą, że oznacza on bazę opartą na tabelach (relacja = tabela), czyli
relacyjna baza danych = tabelaryczna baza danych,
a inni uważają że oznacza on zależności (relacja = zależność) pomiędzy tabelami w bazie, czyli
relacyjna baza danych = „zależnościowa” baza danych.
Czyli chyba nie jest to do końca jednoznaczne, skoro każdy twierdzi co innego i inaczej interpretuje nazwę „relacyjna baza danych”? Czy któraś ze stron ma bezwzględną rację w tym sporze, czy prawda leży pośrodku?
„Relacyjność” jest interpretowana jednoznacznie: relacja = tabela. Relacyjne bazy danych zostały oparte na matematycznym pojęciu relacji. Relacja n-argumentowa to podzbiór iloczynu kartezjańskiego n zbiorów. A zatem np. relacja PRACOWNICY o atrybutach (imię, nazwisko, PESEL, pensja) jest podzbiorem iloczynu kartezjańskiego zbiorów będących dziedzinami atrybutów: imię, nazwisko, PESEL, pensja. W ten sposób w relacji ze sobą są np. elementy („Piotr”, „Kowalski”, „123244354”, 2500) (tzn. on jest naszym pracownikiem), ale w relacji nie będzie jakaś inna kombinacja danych osobowych kogoś, kto nie jest naszym pracownikiem. Zauważmy, że w taki tabelaryczny sposób można by teoretycznie przedstawić także relacje znane z matematyki, np. relację mniejszości „<". Wówczas w tabeli dwukolumnowej zebralibyśmy wszystkie pary liczb, które są ze sobą w takiej relacji (tabela musiałaby mieć baaardzo dużo wierszy…).
Problem wynika z faktu, że autor wpisu do SQLpedii miesza modele i nazwy w nim występujące. Nie winię go za to, ponieważ cały internet pełen jest sieczki, przez którą ciężko się przebić. Żeby poznać bazy od fundamentów i w pełni je zrozumieć należy sięgnąć do dobrych źródeł:
E. F. Codd. A Relational Model of Data for Large Shared Data Banks. „Comun. ACM”. 13/6. s. 377-387.
Pomocna również będzie seria WNT „Klasyka informatyki” autorów Date’a „Wprowadzenie do systemów baz danych” czy Ullmana „Podstawowy wykład z systemów baz danych”. Można również poszukać wykładów Ullmana na Stanford.
Jeżeli brak motywacji do zglębiania tych podstaw (a powiem, że warto), postaram się streścić problem.
W wypadku projektowania baz danych mamy do czynienia z kilkoma etapami modelowania, które poprzez narzędzia Case często są ściągane do dwóch etapów. Ta kumulacja powoduje zmieszanie modeli i ich nazewnictwa. Powoduje jeszcze jeden problem: już na poziomie konceptualnym zakłada się istnienie relacji, co jest według mojej skromnej opini poważnym ograniczeniem, jeżeli nie błędem.
Zatem gdybyśmy mieli tylko kartki i długopisy zaczęlibyśmy od modelowania koceptualnego (inaczej pojęciowego) gdzie wyłonilibyśmy z świata rzeczywistego najważniejsze obiekty, których dane warto przechowywać – w tym modelu nazywamy je encjami. Encje mają swoje cechy – deskryptory, mają też identyfikatory, które odróżnią jedną instancję encji od drugiej. Np encja student posiada deskryptory numer indeksu, imię, nazwisko itd. Instancja to: 12345 Jan Kowalski.
Encje nie muszą być płaskie i dwuwymiarowe jak tabele. Encje mogą mieć podtypy, (nadtyp: pracownik, podtyp: pracownik naukowy, pracownik techniczny, pracownik dydaktyczny). Mogą mieć dane zagnieżdżone (adresy, a w nim kilka typów: korespondencyjny, zameldowania), czy deskryptory wyliczeniowe (wiek). Między encjami mogą występować różne związki (również bardzo złożone: wiele do wielu, zwrotne, czy wzajemnie wykluczające się).
Powstaje bogaty diagram związków encji jako efekt naszej pracy. Powinien być na tyle uniwersalny by przejść z niego do dowolnego innego modelu logicznego, nie powinien nas ograniczać. Na jego bazie powinniśmy móc tworzyć zarówno relacje, jak i obiekty czy struktury drzewiaste, lub grafy. Jeżeli ktoś użył do tego etapu narzędzia Case, poza UML’em, niestety od razu wrzóci go w model relacyjny, a tak nie powinno być.
Następny etap to modelowanie logiczne. Na tym etapie musimy już myśleć z jakiego oprogramowania będziemy korzystać, chociaż na tyle by zdecydować, czy będzie to model relacyjny, obiektowy, semistrukturalny, przeznaczony do funkcji analitycznych (kostki danych) itd. Muszę też uprzedzić, że te modele są ciągle matematyczne i do praktyki nam daleko, zatem możemy pozostać przy starożytnej kartce i długopisie 😉
Załóżmy, że zdecydowaliśmy się na model czysto relacyjny (w tych czasach to samobójstwo) nasze encje muszą zostać przetransformowane na relacje, deskryptory na atrybuty, deskryptory identyfikujące na klucze kandydujące. Uwaga na poziomie modelowania logicznego nie ma tabel, kolumn, wierszy – to bzdura mieszająca ludziom w głowach, choć niby ma uprościć pojmowanie. Przy przejściu na model czysto relacyjny z modelowania pojęciowego pojawią się liczne problemy. Co zrobić ze związkami wiele do wielu – wyłonić kolejną relację przejściową. Co zrobić z danymi złożonymi – rozbić na więcej atrybutów, lub utworzyć kolejną relację, powiązaną odpowiednimi kluczami obcymi. Co zrobić z deskryptorami wyliczeniowymi – usunąć. Co zrobić z podtypami – w zależności od problemu, scalić, lub wydzielić kolejne relacje. Całość należy jeszcze poddać złożonej analitycznie normalizacji, by uniknąć późniejszych błędów na spójności danych w momencie ich modyfikowania. Uffff, to mozolna praca, ale jeżeli jest zrobiona przez osobę świadomą, o dobrych fundamentach matematycznych, baza będzie działać sprawnie.
Zamiast modelu relacyjnego możemy wybrać model obiektowy, w którym znacznie łatwiej wyrazić skomplikowane zależności, czy model semistrukturalny, który wykorzystuje grafy i jest bardzo elastyczny w późniejszym stosowaniu. W ogóle mamy tyle modeli do wyboru, że czemu się wszyscy tak przyczepili do tych relacji….
OK, jesteśmy po etapie twórczego bazgrolenia po kartkach. Możemy zasiąść do klawiatury, a tu niespodzianka… Nie istnieje coś takiego jak model czysto relacyjny w fizycznych bazach danych. Już na etapie projektowania języka SQL w latach 70 ubiegłego wieku, o tym wiedziano. Mamy tabele, wiersze, kolumny, typy danych. Musimy coś fizycznie zapisać na dysku, stąd musi pojawić się porządek, którego w relacjach nie ma. Muszą pojawić się ograniczenia wynikające z fizycznej budowy dysku i sposobu działania SZBD. Takich różnic między matematyczną „wizją” a fizycznym zapisem możnaby mnożyć wiele. Następna kwestia: świat poszedł od lat 70-tych mocno do przodu, a dane przechowywane w bazach to nie tylko łatwe do tabelarycznego zapisu imiona i nazwiska, ale również mapy, zdjęcia, zapisy wideo, strumienie danych itp. Co nam pozostaje – model postrelacyjny, tak go można zgrabnie nazwać, który nie jest sprawą nową, bo istnieje mniej więcej od 92 roku, kiedy wprowadzono potężne zmiany w SQL-u. W tabelach możemy zagnieździć dane XML, obrazy, inne tabele, obiekty, referencje. Dane możemy poukładać w kostki, dane możemy replikować, dane możemy zapisać w pary klucz- wartość.
Mogłabym tak długo…
Zresztą prowadzę pięć przedmiotów „bazodanowe” każdy po 30 godzin i tak mi mało 😉
Reasumując:
modelowanie pojęciowe: encje, deskryptory, związki, hierarchie;
modelowanie logiczne: relacyjne (relacje, atrybuty, klucze), obiektowe, semistrukturalne i bogadztwo innych
implementacja fizyczna: tabele (kolumny, wiersze, klucze, typy danych), obiekty (pola, referencje, metody), XML (węzły, identyfikatory) lub tak zwany mix, który ciężko ogranąć.
Mieszanie pojęć wynika z braku fundamentów, a ten wynika z organicznego wstrętu do czytania książek i braku namiętności w stosunku do matematyki. Proszę się na mnie nie gniewać za te ostre słowa, ale cytując pewnego dziennikarza „mówię jak jest” 😉
Zachęcam do czytania i umiłowania matematyki, ona w tych czasach jest taka samotna…
wrzóci !
bogadztwo !
Czyli 90% źródeł i „popularnych” podręczników praktycznych z zakresu baz danych stosuje niepoprawną i/lub niespójną terminologię, a kompetentne są tu jedynie źródła matematyczne (dla wielu niezbyt strawne, szczególnie jeśli potrzebna jest wiedza praktyczna i przebijanie się przez setki czy tysiące stron podręczników akademickich nie wchodzi w rachubę)?
Niestety tak właśnie jest. Model relacyjny, to model matematyczny – tutaj pojęcie relacji jest zdefiniowane jednoznacznie. Problem z mieszaniem pojęcia relacja zamiast związek wynika prawdopodobnie z niechlujstwa językowego przy tłumaczeniu z angielskiego.
Znakomity i dojrzały wpis!!!
Rewelacyjna strona dla osób rozpoczynających przygodę z SQL
Takiego wytłumaczenia szukałem. Dzięki 🙂
bardzo dobre. zaczynam zabawe w SQL i od tej strony zaczynam.
Bardzo dobry artykuł. Jestem początkująca w nauce o bazach i ten post bardzo mi pomaga. Dzięki
Jej… Teraz chociaż wiem do czego matematyka dyskretna ze studiów mi się przyda. 😀