Wydajność  zapytań SQL to problem, który prędzej czy później spotyka każdego użytkownika bazy danych, piszącego kwerendy. Nie ważne czy powodem jest źle napisane zapytanie wolno generujące raport, czy ogólne obciążenie serwera, często właśnie na wskutek nieoptymalnych kwerend.
zapytań SQL to problem, który prędzej czy później spotyka każdego użytkownika bazy danych, piszącego kwerendy. Nie ważne czy powodem jest źle napisane zapytanie wolno generujące raport, czy ogólne obciążenie serwera, często właśnie na wskutek nieoptymalnych kwerend.
Minimalizowanie wpływu wysyłanych zapytań na obciążenie serwera, to bez dwóch zdań – obowiązek a nie tylko cecha dobrego programisty.
W artykule tym, zaprezentuję przegląd metod pomiarowych wydajności zapytań SQL dostępnych w SQL Server. Pokażę także typowe błędy i niedoskonałości niektórych z narzędzi.
Pomiar i porównanie wydajności zapytań SQL
Podstawowe pytanie w kontekście badania wydajności zapytań to, co będziemy mierzyć i w jaki sposób porównywać dwie kwerendy.
Najbardziej oczywistym wyznacznikiem jakości jest czas, od wysłania zapytania do otrzymania wyników. Wynika on z czasu pracy procesora, liczby odczytów logicznych (pamięć RAM), fizycznych (operacje dyskowe IO) i przesłaniu wyniku do użytkownika.
Ponieważ zakładamy, że porównywane zapytania mają zwracać dokładnie te same zbiory wynikowe, nie będzie nas interesował ruch sieciowy. Skupimy się więc na obciążeniu procesora, całkowitym czasie przetwarzania i licznikach odczytów.
Drugą kwestią jest analiza czasu tworzenia planu wykonania – potrzebnego do „kompilacji” zapytania i jego wykorzystania w przyszłości. Jeśli w naszym środowisku istnieje prawdopodobieństwo, że kwerenda będzie często rekompilowana – trzeba ten czynnik także uwzględnić. Jeśli jednak możemy przyjąć, że raz utworzony plan, będzie raczej rezydował na stałe w buforze – można skupić się tylko na kwestiach odczytów i czasu przetwarzania.
W naszym scenariuszu testowym, będziemy chcieli przekonać się, które rozwiązanie będzie optymalne do rozwiązania klasycznego zadania.
Chcemy wyświetlić informacje o ostatnich zleceniach złożonych przez poszczególnych Klientów. Jest to typowy problem związany z grupowaniem rekordów (Klienci) i operacjach w ramach podgrup (dane o ostatnim zleceniu danego Klienta). Analogicznie moglibyśmy chcieć znaleźć informacje o najnowszych odczytach urządzeń, najlepiej sprzedawanych produktach w ramach grupy itd.
Chyba najbardziej intuicyjny z możliwych przykładów rozwiązania :
USE Northwind
GO
SELECT o.CustomerId, o.OrderId , o.ShipCountry, o.OrderDate
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID;
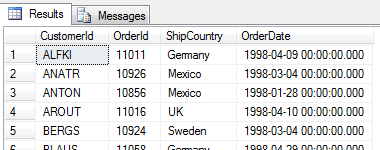
To samo zapytanie możemy zapisać na wiele innych sposobów np. z wykorzystaniem podzapytania skorelowanego czy funkcji użytkownika. Z definicji, zapytania zawierające funkcje skalarne czy podzapytania skorelowane, są znacznie gorsze niż zwykłe złączenia, ale po to właśnie powstał ten artykuł, aby przekonać się czy tak jest w rzeczywistości.
Metody pomiarowe wydajności zapytań SQL
Pierwsze starcie : SET STATISTICS IO, TIME ON
Na początek porównajmy wydajności zapytań z wykorzystaniem najprostszych (przy okazji najbardziej niedoskonałych) metod. Prezentuję je jako pierwsze, bo są one często stosowane z uwagi na prostotę (dla leniuchów) a prowadzić mogą do błędnych wniosków. Przyznam szczerze, że sam nieraz dałem się nabrać na cuda jakie pokazują.
Polecenia wyświetlania statystyk odczytów IO oraz czasu, włączamy bezpośrednio w sesji połączenia.
-- włączenie statystyk czasu i odczytów
SET STATISTICS IO, TIME ON
-- czyścimy cache (działamy na środowisku testowym ;))
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
GO
-- Q1 - prosty join
SELECT /* Q1 Simple Join */ o.CustomerId, o.OrderId, o.ShipCountry
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID;
-- jeszcze raz dla drugiego zapytania
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
GO
-- Q2 - podzapytanie skorelowane
SELECT /* Q2 Correlated SubQ */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
)
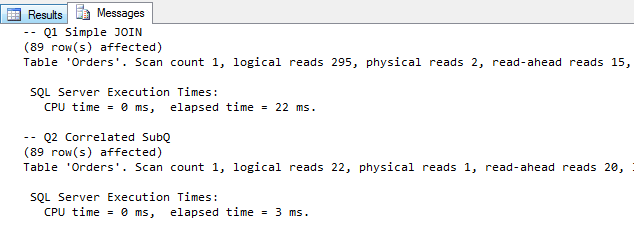
Z powyższych wyników, można wywnioskować że drugie zapytanie (skorelowane) jest znacznie bardziej efektywne zarówno pod względem liczby odczytów jak i czasu wykonania.
Pamiętajmy jednak, że testujemy pierwsze uruchomienie zapytania z czystymi buforami, które nie do końca musi być miarodajne w odniesieniu do rzeczywistej pracy systemu. Samo utworzenia planu wykonania i odczytania danych z dysku, może przekroczyć późniejszy czas potrzebny na ponowną realizację zapytania.
Wykonajmy jeszcze raz obydwie kwerendy, bazując już na istniejących planach (bez czyszczenia pamięci) :
SELECT /* Simple Join */ o.CustomerId, o.OrderId , o.ShipCountry
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID;
-- Q2 - podzapytanie skorelowane
SELECT /* Correlated SubQ */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
)
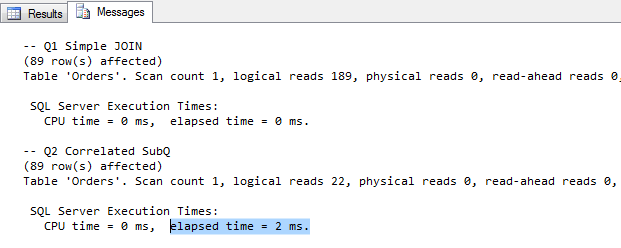
Tym razem prosty JOIN okazuje się szybszy od podzapytania skorelowanego. Zerknijmy jeszcze na analizę porównawczą, kosztów planów wykonania (w Management Studio : Include Actual Execution Plan – CTRL+M) :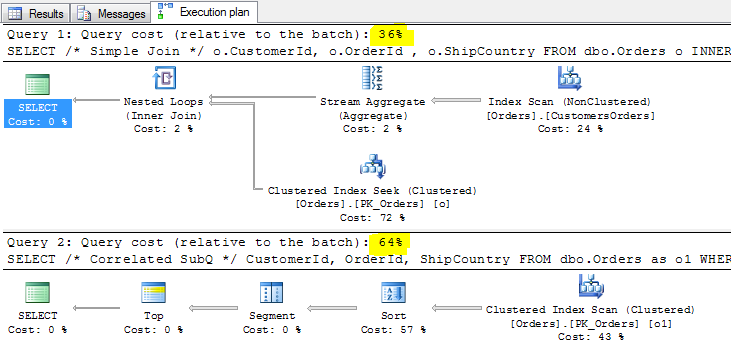
Według powyższych informacji, stosunek kosztów zapytania skorelowanego do zwykłego JOINa jest niemal jak 2:1 (64%: 36%). Czyli zapytanie skorelowane jest znacznie gorsze od JOINA w każdym kolejnym wywołaniu, pomimo słabości przy pierwszym wywołaniu.
Prawdziwą wadę tej metody pomiarowej zobaczymy (wręcz cuda), porównując kolejną wersję kwerendy. Trzecim rozwiązaniem naszego zadania, może być zapytanie wykorzystujące skalarną funkcję użytkownika. Na początek utwórzmy ją :
USE NORTHWIND
GO
CREATE FUNCTION dbo.GetMax
(
@CustId char(5)
)
RETURNS INT
AS
BEGIN
RETURN (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = @CustId )
END
Teraz porównanie trzech zapytań zwracających ten sam wynik. Nieco uproszczę pomiar – czytamy wszystko z pamięci (bez czyszczenia buforów i cache) :
-- włączenie statystyk czasu i odczytów
SET STATISTICS IO ON
-- Q1 - prosty join
SELECT /* Simple Join */ o.CustomerId, o.OrderId , o.ShipCountry
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID;
-- Q2 - podzapytanie skorelowane
SELECT /* Correlated SubQ */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
)
-- Q3 - podzapytanie z funkcją skalarną
SELECT /* UDF */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = dbo.GetMax(CustomerId);
Plany wykonania :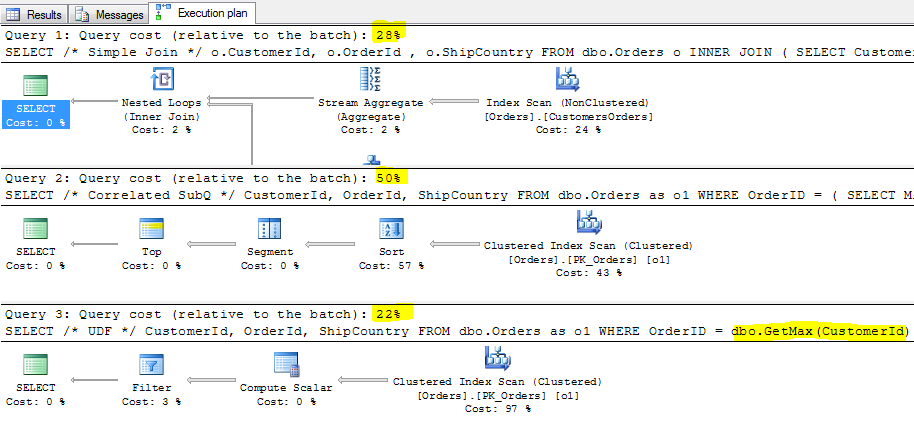
I jeszcze statystki odczytów :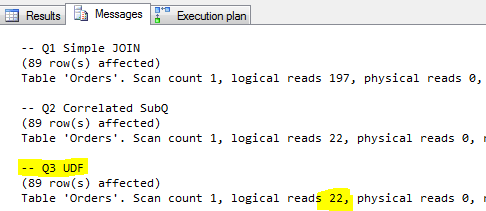
Z powyższego wynika, że kwerenda, która wykonuje skalarną funkcję użytkownika, jest najlepsza (co oczywiście jest błędem!). Zdecydowanie przekłamane są tutaj koszty w planach wykonania, jak i sama liczby odczytów zapytania z UDF. Dlatego powyższy sposób „analizy” nie można uznać za wiarygodny.
Podejście drugie – analiza wydajności za pomocą DMV / DMF
W SQL Server, mamy dostępnych szereg dynamicznych widoków i funkcji systemowych (DMV, DMF). Dzięki nim, możemy dotrzeć do statystyk, informacji o tym co się faktycznie dzieje w silniku bazy danych. Wykonajmy jeszcze raz analizę trzech zapytań w oparciu o te widoki :
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
go
-- żeby nie brać pod uwagę statystyk fizycznych odczytów
select * from dbo.Orders ;
GO
-- Q1 - prosty join
SELECT /* Simple Join */ o.CustomerId, o.OrderId , o.ShipCountry
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID;
-- Q2 - podzapytanie skorelowane
SELECT /* Correlated SubQ */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
)
-- Q3 - podzapytanie z funkcją skalarną
SELECT /* UDF */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = dbo.GetMax(CustomerId);
GO
-- GO 100
SELECT total_worker_time/execution_count AS AvgCPU
, total_worker_time AS TotalCPU
, total_elapsed_time/execution_count AS AvgDuration
, total_elapsed_time AS TotalDuration
, (total_logical_reads+total_physical_reads)/execution_count AS AvgReads
, (total_logical_reads+total_physical_reads) AS TotalReads
, execution_count , total_rows, last_rows
, SUBSTRING(st.TEXT, (qs.statement_start_offset/2)+1
, ((CASE qs.statement_end_offset WHEN -1 THEN datalength(st.TEXT)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS txt
FROM sys.dm_exec_query_stats AS qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) AS st
WHERE st.TEXT not like '%select * from dbo.Orders%' and st.text like '%SELECT%'
ORDER BY TotalDuration

Teraz wyniki wyglądają zupełnie inaczej i pokazują całą prawdę o wcześniejszych próbach oszacowania wydajności.
Olbrzymie przekłamanie poprzedniej metody, widoczne jest w przypadku kwerendy z UDF (pozycja 4). Funkcja skalarna (pozycja 3) została wykonana dla każdego rekordu tabeli dbo.Orders, czyli 830 razy! Koszt tego zapytania (odczyty o dwa rzędy większe niż skorelowanego, czas ok 50 razy gorszy) w porównaniu do dwóch pierwszych kwerend jest kompletnie nie do przyjęcia – a miało być tak pięknie…
Pomiar wydajności zapytania SQL, najlepiej wykonać na kilkudziesięciu / kilkuset powtórzeniach. Analizując takie przebiegi w Management Studio, warto zaznaczyć opcję wykonania zapytania bez zwracania wyników (Tools>Options) :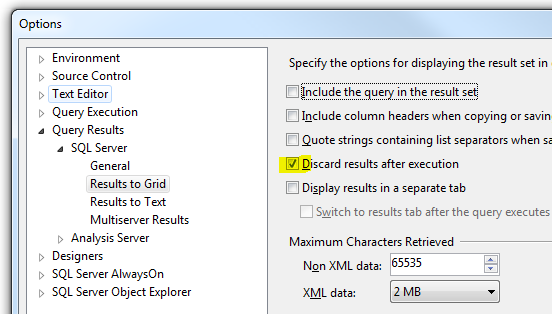
Poniżej wynik dla GO 100, naszej trójki konkurentów – zwycięzcą, pod względem czasu wykonania, jest Simple JOIN pomimo sporej liczby logicznych odczytów :
Extended Events
Pewnym minusem, korzystania z DMV/DMF, jest ulotność statystyk. Widoki te pokazują aktualny status obiektów przechowywanych w pamięci. Co zrobić gdybyśmy zechcieli testować 100 razy pełen cykl kompilacji i wykonania kwerendy ? Po każdym
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
w widokach nie mamy przecież czego szukać. Poza tym nie mamy w pełni kontroli nad tym co jest przechowywane w buforach a co nie. Rozwiązania są dwa – Extended Events (XE) – czyli najlepsze pod kątem wydajności mechanizmy śledzenia w SQL Server oraz Profiler.
Zbiór zdarzeń, które możemy przechwytywać za pomocą XE jest bardzo szeroki. W naszym scenariuszu będziemy analizować zdarzenia sqlserver.sql_statement_completed. Tworzenie sesji XE do przechwytywania potrzebnych statystyk wydajnościowych zapytań :
-- Tworzymy sesję XE
CREATE EVENT SESSION perftest ON SERVER
ADD EVENT sqlserver.sql_statement_completed
ADD TARGET package0.event_file(SET filename=N'D:\perftest\perftest.xel',
max_file_size=(2),max_rollover_files=(100))
WITH ( MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_MULTIPLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=120 SECONDS,MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON);
ALTER EVENT SESSION perftest ON SERVER STATE = START;
Żeby było ciekawiej, dorzućmy do zawodów jeszcze dwie inne wersje kwerendy, zwracających ten sam, poprawny rezultat.
Słabość funkcji skalarnych, można pokonać, przepisując je na tabelaryczne (czasem ma to sens) i wywołując je poprzez CROSS JOIN (Q4). Wiele problemów rozwiązać można również za pomocą funkcji okna OVER() – będzie to ostatnie z testowanych rozwiązań kwerendy (Q5).
Wykonajmy więc wszystkie zapytania, które będą już przechwytywane przez aktywną sesję XE :
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
select * from dbo.Orders
GO
-- Q1 - prosty join
SELECT /* Simple Join */ o.CustomerId, o.OrderId , o.ShipCountry
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID;
-- Q2 - podzapytanie skorelowane
SELECT /* Correlated SubQ */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
);
-- Q3 - podzapytanie z funkcją skalarną
SELECT /* UDF */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = dbo.GetMax(CustomerId);
-- Q4 z CROSS APPLY (analogia TVF)
SELECT /* CROSS APPLY */ CustomerId, OrderId, ShipCountry
FROM dbo.Orders o Cross APPLY ( SELECT MAX(OrderID) as MaxOrderID
FROM dbo.Orders as O2
WHERE CustomerID = o.CustomerID ) t
where o.OrderID = MaxOrderID;
-- Q5 Funkcja okna z ROW_NUMBER()
SELECT /* OVER() */ CustomerId, OrderId, ShipCountry
FROM (
SELECT OrderId, CustomerID, ShipCountry,
ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY OrderID DESC) AS MaxOrder
FROM dbo.Orders ) AS a
WHERE MaxOrder = 1 ;
GO 100
DROP EVENT SESSION perftest ON SERVER;
Pozostaje nam zajrzeć do pliku ze zdarzeniami – w moim przykładzie zapisanym na D:\perftest\ :
SELECT statement, AVG(duration) as AVG_Duration ,
AVG(cpu_time) as AVG_CPU_time,
AVG(logical_reads) as AVG_LR,
AVG(physical_reads) as AVG_PR,
SUM(cpu_time) as SUM_CPU_TIME,
SUM(duration) as SUM_DURATION,
SUM(logical_reads) as SUM_LR,
SUM(physical_reads) as SUM_PR,
count(*) as ExecCnt
FROM (
SELECT duration=e.event_data_XML.value('(//data[@name="duration"]/value)[1]','int')
,cpu_time=e.event_data_XML.value('(//data[@name="cpu_time"]/value)[1]','int')
,physical_reads=e.event_data_XML.value('(//data[@name="physical_reads"]/value)[1]','int')
,logical_reads=e.event_data_XML.value('(//data[@name="logical_reads"]/value)[1]','int')
,writes=e.event_data_XML.value('(//data[@name="writes"]/value)[1]','int')
,statement=e.event_data_XML.value('(//data[@name="statement"]/value)[1]','nvarchar(max)')
,TIMESTAMP=e.event_data_XML.value('(//@timestamp)[1]','datetime2(7)')
FROM (
SELECT CAST(event_data AS XML) AS event_data_XML
FROM sys.fn_xe_file_target_read_file(N'D:\perftest\perftest*.xel', NULL, NULL, NULL)
)e
)q
WHERE q.[statement] LIKE '%SELECT /%'
GROUP BY statement
ORDER BY SUM_DURATION

W teście wykorzystującym istniejące plany wykonania (bez każdorazowego czyszczenia pamięci), zwyciężyła kwerenda oparta o prostego JOINa. Pozostałe rozwiązania, poza funkcją skalarną (totalna porażka), oferują porównywalną wydajność (total duration). Wśród nich, wyróżnia się zapytanie z funkcją okna, która najmniej obciąża badane zasoby serwera (CPU + reads).
SQL Server Profiler
Ostatnim narzędziem do pomiaru wydajności zapytań, dostępnym bezpośrednio w SQL Server jest Profiler. Zostawiłem go na koniec, ponieważ jest to dość historyczny tool i nie jest zalecanym narzędziem do testowania obciążenia w środowisku komercyjnym. W odróżnieniu do Extended Events, które są uruchamiane „inside” silnika SQL Server, Profiler jest narzędziem „zewnętrznym”, którego działanie wprowadzać może spory narzut na wydajność monitorowanej instancji. Z pewnością jest to bardzo przyjemny w użyciu graficzny tool, za pomocą którego, możemy przechwytywać zdarzenia podobnie jak za pomocą XE i sprawdza się znakomicie w środowisku developerskim.
Na początek tworzymy nową sesję – plik śladu (można go potem odtwarzać lub np. korelować z perfmonem), definiując interesujące nas zdarzenia :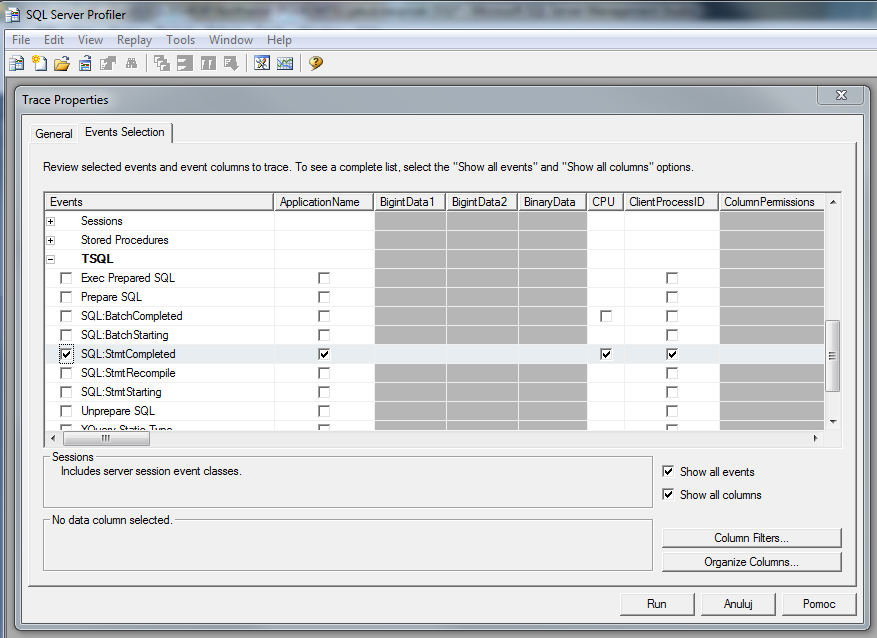
Uruchomię teraz naszą testową piątkę zapytań. Poniżej efekt ich przechwycenia (LIVE) :
Podsumowanie
Badanie wydajności zapytań SQL, możemy zrealizować na wiele sposobów. Każda z zaprezentowanych metod ma swoje zalety i wady. Warto poznać je wszystkie, aby wybrać odpowiednią do konkretnej sytuacji. Polecam w środowiskach komercyjnych widoki dynamiczne i XE z uwagi na wiarygodność i ich „lekkość”.
Temat optymalizacji i pomiarów wydajności zapytań jest znacznie szerszy. Nie zawsze kwerenda działająca świetnie dla tysięcy rekordów, jest również najlepsza w przypadku bardzo dużych tabel (złożoność obliczeniowa zapytań), ale o tym w następnym artykule.
Także, jakby co czekamy cały czas 😉
Kiedy doczekamy się kolejnych rozdziałów kursu:
– Stosowanie indeksów
– Optymalizacja zapytań
??? 🙂
Obiecuję że niedługo (być może po wakacjach) coś się pojawi 😉
ok, ale po których 😉
Świetny wpis, super się czyta 😉
rozpoczynam właśnie swoją przygodę z bazami danych MS, no i tak też trafiłem na tego bloga
Dziękuję za tą wiedzę.