W poprzednim rozdziale tego kursu, opisywałem koncepcję konstrukcji podzapytań niezależnych. Można je było uruchomić w całkowitym oderwaniu od kwerendy nadrzędnej. Drugim typem podzapytań są skorelowane, czyli bezpośrednio powiązane z zapytaniem nadrzędnym. Łącznikiem jest jeden lub więcej atrybutów, przekazywanych z zapytania nadrzędnego.
Z punktu widzenia wydajności, taka konstrukcja zazwyczaj (ale nie zawsze) pociąga za sobą konieczność wykonania takiego podzapytania wielokrotnie. Mogą być one dość kosztowne, ale nie jest to sztywną regułą. Podobnie jak inne narzędzia w sprawnych rękach potrafią być bardzo przydatne i wbrew utartym stereotypom – efektywne. W artykule tym, przedstawiam koncepcję i praktyczne zastosowania podzapytań skorelowanych.
Na wstępie pokażę prosty przykład z zastosowaniem tych konstrukcji w SELECT. Porównam ich wydajność z alternatywnymi sposobami realizującymi ten sam cel. W dalszej części zaprezentuję przypadki, których (bez sięgania do logiki programistycznej, kursorów, CLR) nie da się rozwiązać inaczej niż z zastosowaniem podzapytań skorelowanych. Na koniec przypadek łamiący stereotyp – większa wydajność przetwarzania dzięki podzapytaniom skorelowanym.
Podzapytania skorelowane w praktyce
Podzapytania skorelowane podobnie jak niezależne, mogą być użyte w dowolnym miejscu kwerendy.
Rozważmy zadanie, w którym chcemy wyświetlić informacje o wszystkich Klientach oraz liczbie zleceń każdego z nich.
Zapytanie takie możemy zapisać na wiele sposobów – mniej lub bardziej efektywnie. Wykorzystamy podzapytanie skorelowane aby „dokleić” dodatkową informację o liczbie zleceń i pokazać w praktyce ich sposób działania :
USE Northwind
GO
SELECT CustomerID, CompanyName,
( -- podzapytanie skorelowane
SELECT COUNT(OrderID)
FROM dbo.Orders as O
WHERE o.CustomerID = C.CustomerID -- faktyczna korelacja
) as LiczbaZlecen
FROM dbo.Customers as C
ORDER BY LiczbaZlecen desc
CustomerID CompanyName LiczbaZlecen ---------- ---------------------------------------- ------------ SAVEA Save-a-lot Markets 31 ERNSH Ernst Handel 30 QUICK QUICK-Stop 28 ... CENTC Centro comercial Moctezuma 1 FISSA FISSA Fabrica Inter. Salchichas S.A. 0 PARIS Paris spécialités 0 (91 row(s) affected)
Na powyższym przykładzie łatwo sobie wyobrazić, teoretyczny proces przetwarzania takiej kwerendy.
Dla każdego Klienta, czyli rekordu z tabeli dbo.Customers, obliczona zostanie wartość liczby zleceń. Korelacja odbywa się w warunku WHERE podzapytania umieszczonego w SELECT (podświetlona linia). Odwołuję się w tym miejscu do wartości atrybutu C.CustomerID, przekazywanej z zapytania nadrzędnego. Widać to po zastosowanym aliasie C tabeli dbo.Customers.
Zgodnie z regułami logicznego przetwarzania zapytań, dla każdego elementu wchodzącego do SELECT, zostanie przekazana wartość CustomerID do podzapytania, czyli po prostu obliczona wartość liczby zleceń. Podzapytanie w tym miejscu musi zwracać wartość skalarną – tak też się dzieje.
Dla pierwszego Klienta z listy (SAVEA), podzapytanie skorelowane będzie takiej postaci :
SELECT COUNT(OrderID)
FROM dbo.Orders as O
WHERE o.CustomerID = 'SAVEA' -- wartość SAVEA jest przekazana z zapytania nadrzędnego
Zerknijmy teraz na statystyki i plan wykonania takiego zapytania. Uruchom to zapytanie raz jeszcze z poleceniem SET STATISTICS IO ON oraz załączając plan wykonania ( Query > Include Actual Execution Plan) :
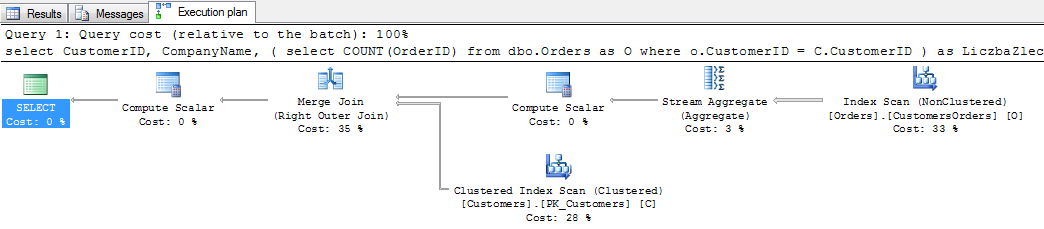
Tu niespodzianka. Podzapytanie skorelowane, obliczające liczbę zleceń zostało wykonane tylko raz. Widać to po liczbie skanów tabeli Orders (1) oraz występującym bloku łączenia tabel (MERGE JOIN). Zapytanie zostało więc zrealizowane w taki sam sposób, jak zwykłe złączenie dwóch tabel.
To samo zadanie mogliśmy rozwiązać za pomocą takiej kwerendy :
SELECT c.CustomerID, c.CompanyName, COUNT(OrderID) as LiczbaZlecen
FROM dbo.Customers as C left join dbo.Orders as O
ON o.CustomerID = C.CustomerID
GROUP BY c.CustomerID, c.CompanyName
ORDER BY LiczbaZlecen DESC
Jeśli przerabiasz ten kurs od początku, to z pewnością nie jesteś zaskoczony tym faktem. W SQL pomiędzy teorią i praktyką przetwarzania zapytań, jest jeszcze optymalizator. Jego rola to automatyczny wybór efektywnej metody dostępu do danych i możliwie najtańszy koszt realizacji zadania.
Optymalizator zapytań, na etapie przetwarzania, potrafi niejawnie przekształcić kwerendę z podzapytaniem skorelowanym w zwykłą która stosuje proste złączenia.
Nie zwalnia nas to jednak z obowiązku świadomego pisania zapytań. Stosując podzapytania skorelowane, musimy przynajmniej w rachunku teoretycznym, zakładać mniej efektywny algorytm działania. Szczególnie w odniesieniu do prostszej metody łączenia tabel (o ile jest to możliwe).
Porównajmy jeszcze raz te dwie kwerendy :
SET STATISTICS TIME ON
-- zapytanie skorelowane
SELECT CustomerID, CompanyName,
(
SELECT COUNT(OrderID)
FROM dbo.Orders as O
WHERE o.CustomerID = C.CustomerID
) as LiczbaZlecen
FROM dbo.Customers as C
-- zwykle łączenie tabel z grupowaniem
SELECT c.CustomerID, c.CompanyName, COUNT(OrderID) as LiczbaZlecen
FROM dbo.Customers as C LEFT JOIN dbo.Orders as O
ON o.CustomerID = C.CustomerID
GROUP BY c.CustomerID, c.CompanyName
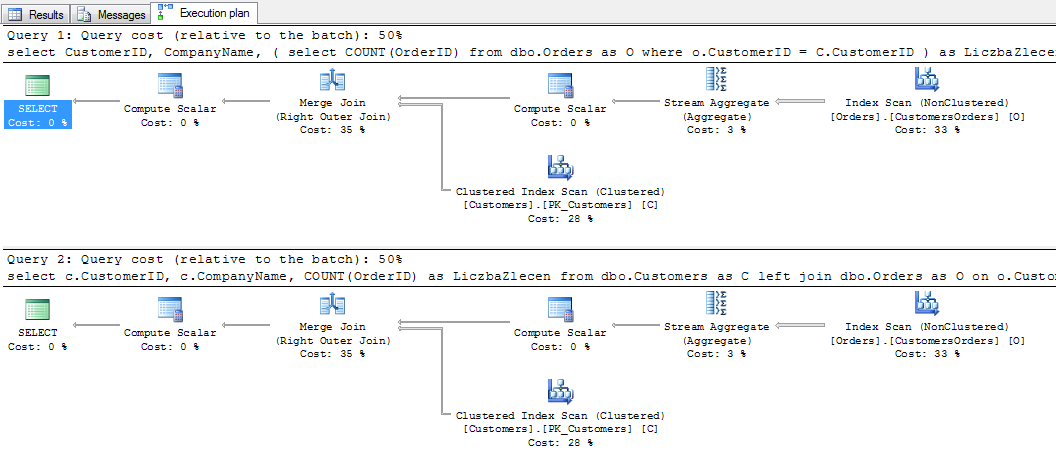
W obydwu przypadkach plany wykonania, koszty, statystyki odczytów są identyczne.
Skomplikujmy teraz odrobinę nasz scenariusz. Chciałbym pokazać, że podzapytania skorelowane na dłuższą metę, są jednak mniej efektywne niż zwykłe łączenie tabel.
Oprócz informacji o Klientach i całkowitej liczby zleceń, interesował nas będzie dodatkowo numer ostatniego zlecenia.
Zmodyfikujmy zatem oba te zapytania. W skorelowanym dodamy kolejne, obliczające MAX(OrderID) a w łączącym dwie tabele po prostu wyciągniemy ad hoc tą dodatkową informację, którą praktycznie mamy na tacy.
-- zapytanie zawierające podzapytania skorelowane
SELECT CustomerID, CompanyName,
(
SELECT COUNT(OrderID)
FROM dbo.Orders as O
WHERE o.CustomerID = C.CustomerID
) as LiczbaZlecen
,
(
SELECT MAX(OrderID)
FROM dbo.Orders as O
WHERE o.CustomerID = C.CustomerID
) as OstatnieZlecenie
FROM dbo.Customers as C
-- zwykle łączenie tabel z grupowaniem
SELECT c.CustomerID, c.CompanyName, COUNT(OrderID) as LiczbaZlecen,
MAX(OrderID) as OstatnieZlecenie
FROM dbo.Customers as C LEFT JOIN dbo.Orders as O
ON o.CustomerID = C.CustomerID
GROUP BY c.CustomerID, c.CompanyName
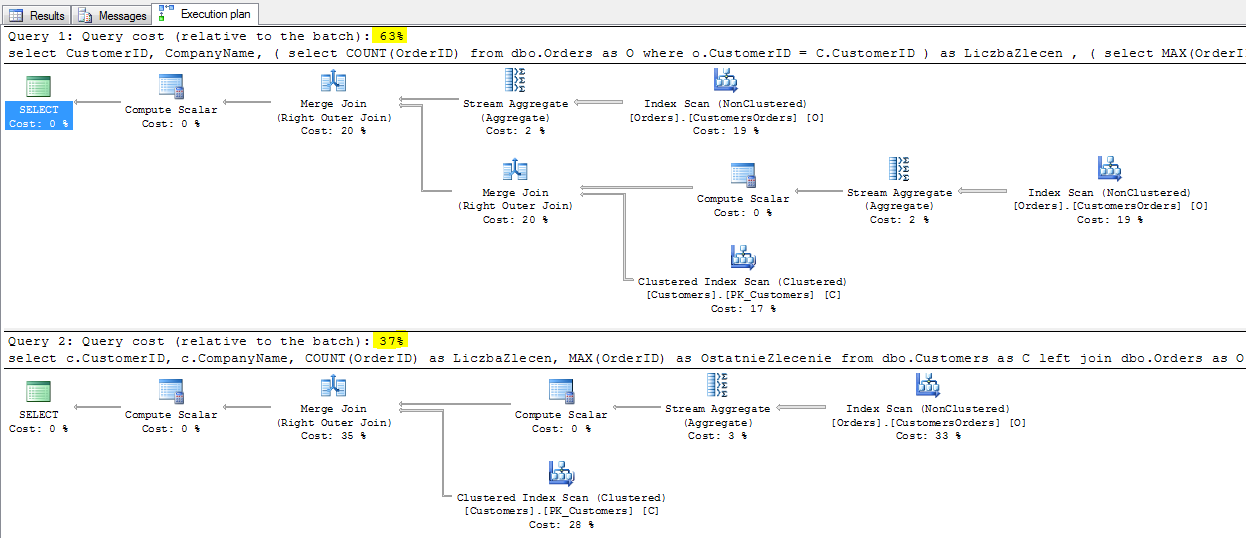
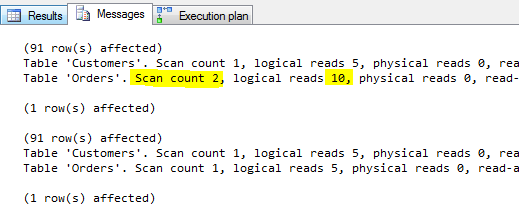
Tym razem różnica jest już zauważalna. W przetwarzaniu zapytania skorelowanego, dodane zostało kolejne złączenie i zwiększyło to liczbę odczytów (dodatkowy skan tabeli Orders). W zwykłym łączeniu tabel wszystko po staremu. Widać więc w takim podejściu słabość tych konstrukcji, choć jeszcze pełnego potencjału tragedii nie pokazałem.
Numerowanie rekordów za pomocą podzapytań skorelowanych
Innym przykładem zastosowań podzapytań skorelowanych, które wypadają bardzo słabo w porównaniu z alternatywnymi metodami, jest automatyczna numeracja wierszy.
We wcześniejszych wersjach serwera niż SQL Server 2005, nie było dostępnej funkcji ROW_NUMBER(). Jednym ze sposobów nadania kolejnych numerów rekordom, było użycie podzapytania skorelowanego. Ten przykład w praktyce nie ma już raczej zastosowania. Czasem jeszcze można spotkać SQL Server 2000 na produkcji i tam tego typu przypadki się pojawiają.
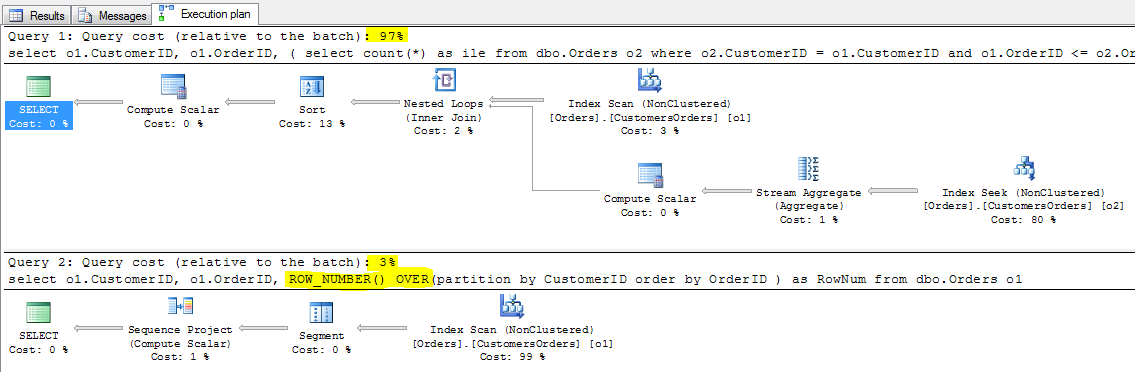
Obrazuje to ten najgorszy scenariusz, narzut podzapytań skorelowanych. Rzeczywiste, iteracyjne wykonanie się kwerendy podrzędnej, dla każdego wiersza osobno w praktyce.
SELECT o1.CustomerID, o1.OrderID,
(
SELECT count(*) as ile
FROM dbo.Orders o2
WHERE o2.CustomerID = o1.CustomerID and o1.OrderID <= o2.OrderID
) as RowNum
FROM dbo.Orders o1
ORDER BY o1.CustomerID, RowNum
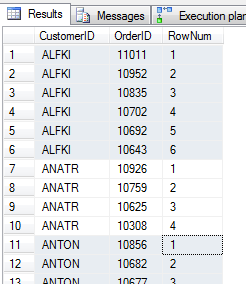
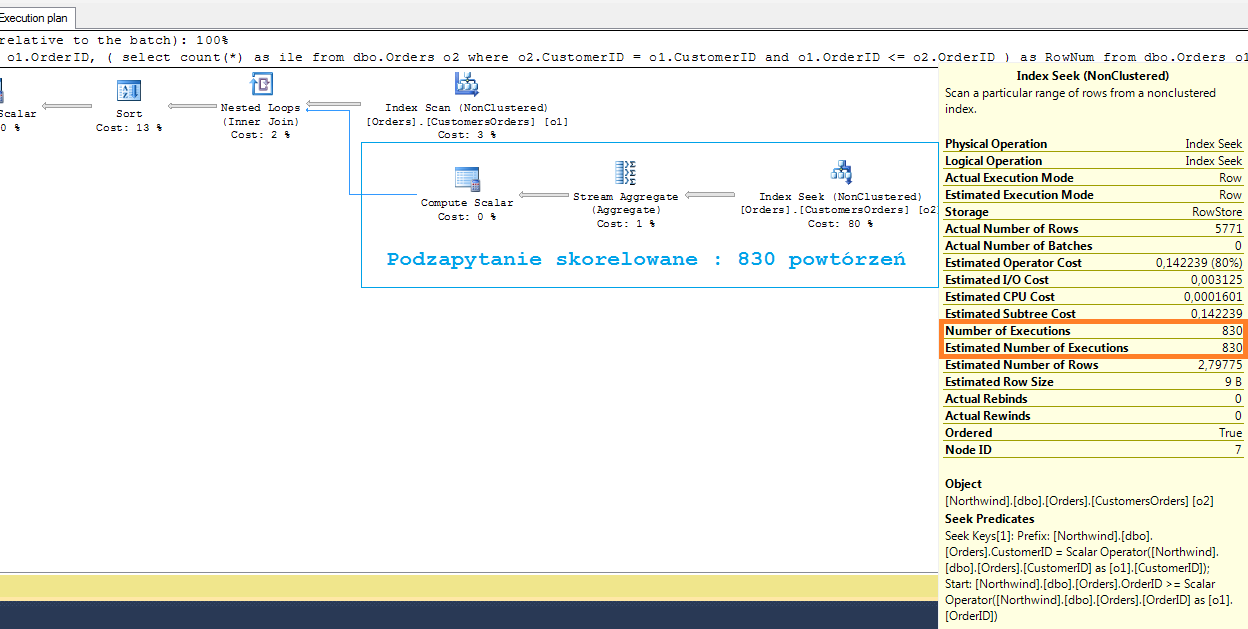
Teraz plan i koszty wykonania. Zwróć uwagę na liczbę skanów i logicznych odczytów tabeli dbo.Orders. Dla każdego zlecenia, podzapytanie skorelowane zostanie uruchomione niezależnie.
Ponieważ mamy 830 zleceń, ta podkwerenda również zostanie uruchomiona 830 razy.
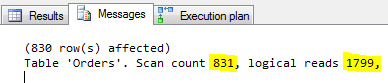
Dla porównania, kwerenda wykonująca to samo zadanie, czyli numerująca kolejne rekordy z zastosowaniem funkcji ROW_NUMBER() (dostępna od SQL Server 2005).
Porównajmy obydwie kwerendy aby zaobserwować procentowy stosunek ciężaru ich realizacji.
-- podzapytanie skorelowane
SELECT o1.CustomerID, o1.OrderID,
(
SELECT COUNT(*) as ile
FROM dbo.Orders o2
WHERE o2.CustomerID = o1.CustomerID AND o1.OrderID <= o2.OrderID
) as RowNum
FROM dbo.Orders o1
ORDER BY o1.CustomerID, RowNum
-- numerowanie z wykorzystaniem ROW_NUMBER()
SELECT o1.CustomerID, o1.OrderID,
ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY OrderID ) as RowNum
FROM dbo.Orders o1
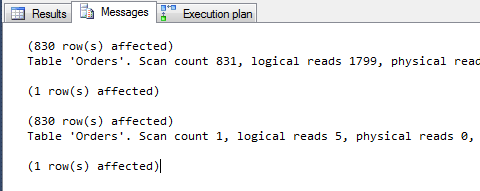
Te wyniki pewnie obrzydzą Ci dość mocno stosowanie podzapytań skorelowanych. Tym bardziej że już sam ich zapis, debuggowanie jest mniej czytelne niż podzapytań niezależnych. Są to charakterystyczne cechy tych konstrukcji i główny powód dla którego unika się stosowania zapytań skorelowanych w praktyce.
Podkreślam to celowo bo w większości zastosowań, kwerendy można zapisać efektywniej, bez konieczności korelacji w podzapytaniu. Są jednak sytuacje ratujące honor podzapytań skorelowanych.
Agregacja wartości znakowych w grupowaniu
Istnieją scenariusze, w których wręcz nie możemy się obyć bez podzapytań skorelowanych. Często zależy nam na tym, aby rozwiązaniem była pojedyncza kwerendy realizująca określony cel. W sytuacjach gdy nie chcemy, lub nie możemy sięgać po techniki programistyczne, podzapytania skorelowane, bywają jedynym rozwiązaniem.
Bardzo praktycznym przykładem, jest zastosowanie podzapytań skorelowanych do agregacji wartości znakowych (stringów) w grupowaniu.
W T-SQL brakuje wbudowanej funkcji agregacyjnej znaków, podobnej do znanych z Oracle LISTAGG() czy WM_CONCAT(). W SQL Server można takie działania wykonywać w logice programistycznej za pomocą funkcji CLR, kursorów T-SQL czy też w warstwie pośredniej LINQ. Nie zawsze jednak są to akceptowalne i optymalne rozwiązania.
To co chcemy osiągnąć, to w pojedynczym zapytaniu grupującym np. po kolumnie Country, zagregować wartości znakowe kolumny City.
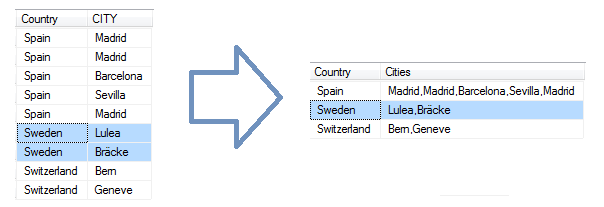
Do tego celu możemy użyć podzapytań skorelowanych oraz możliwości jakie daje funkcja FOR XML (dość nieszablonowy sposób jej zastosowania).
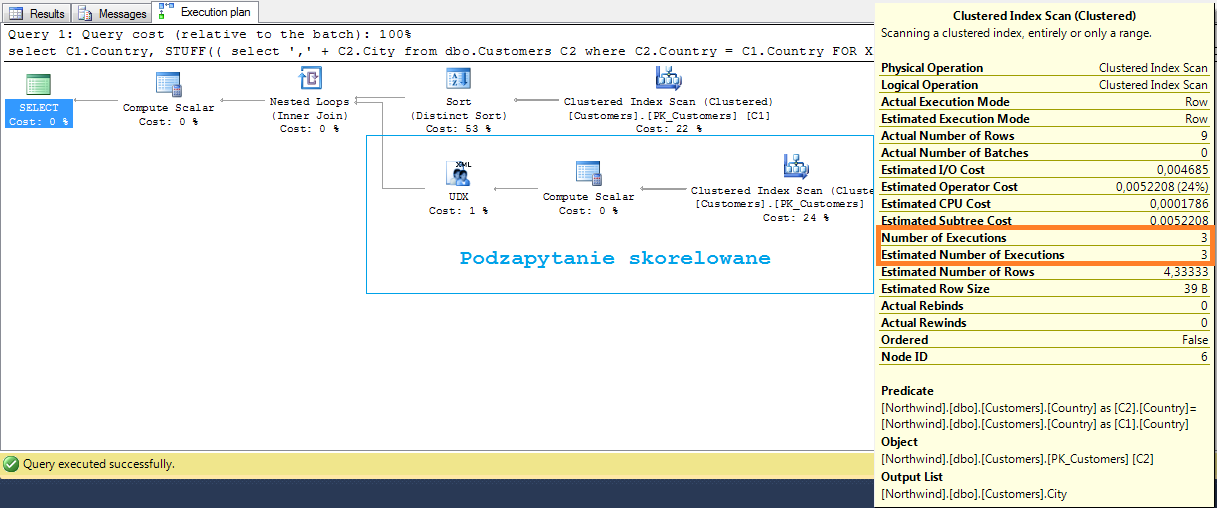
SELECT C1.Country,
STUFF((
SELECT ',' + C2.City
FROM dbo.Customers C2
WHERE C2.Country = C1.Country
FOR XML PATH('')
),1,1,'') as Cities
FROM dbo.Customers C1
WHERE Country LIKE 'S%'
GROUP BY C1.Country
Korelacja odbywa się w SELECT. Wbudowana funkcja STUFF (string, 1, 1, ‘’) obcina pierwszy znak zadanego stringu (usunięcie niepotrzebnego, pierwszego przecinka). A całość agregacji załatwia nam sprytnie FOR XML PATH.
Jest to stosunkowo dobra metoda agregowania wartości znakowych, bo w łatwy sposób za pomocą wbudowanych funkcji języka T-SQL, w jednej kwerendzie możemy osiągnąć cel. Jeśli byśmy chcieli agregować wartości bez duplikatów, w podzapytaniu wystarczy dodać DISTINCT.
Przetwarzanie tego zapytania, wiąże się ze wspominanym wcześniej narzutem charakterystycznym dla podzapytań skorelowanych. Jest to cena jaką płacimy za upakowanie całej logiki w jednym zapytaniu. Dla każdego rekordu osobno, będzie faktycznie uruchamiane podzapytanie. W naszym przypadku trzy rekordy = trzy razy.
Wydajność zapytań skorelowanych
Z reguły podzapytania skorelowane dają gorsze rezultaty (wydajnościowo) niż zwykłe podzapytania lub inne techniki (funkcja okna OVER). Zdarzają się jednak sytuacje, gdy możemy uzyskać poprawienie wydajności dzięki zapytaniom skorelowanym. Może to być na przykład kwerenda w której chcemy pokazać informacje o ostatnim zamówieniu (najnowszym) dla każdego Klienta.
Do dalszej analizy wymagana jest podstawowa znajomość struktur indeksów klastrowych i nieklastrowych.
Zapytanie skorelowane możemy zapisać np. tak :
SELECT CustomerId, OrderId
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
)
CustomerId OrderId ---------- ----------- WOLZA 11044 WILMK 11005 WHITC 11066 … ANTON 10856 ANATR 10926 ALFKI 11011 (89 row(s) affected)
W tym zapytaniu filtrujemy rekordy zleceń, ograniczając się tylko do najświeższych (najwyższy numer) dla każdego z Klientów (CustomerID). To co jest najciekawsze – to plan wykonania tego zapytania – można powiedzieć idealny.
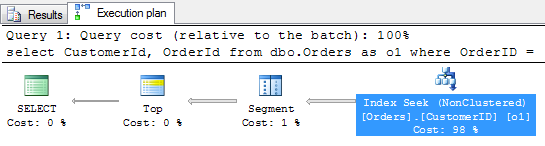
W procesie przetwarzania jest tylko jedno przeszukanie (SEEK) indeksu nieklastrowego [CustomerID] z tabeli dbo.Orders, które załatwia dostęp do wszystkich potrzebnych danych. Zwracane są z tego indeksu rekordy, z maksymalnym OrderID dla danego Klienta. Dzieje się tak, ponieważ na tabeli dbo.Orders jest utworzony indeks klastrowy składający się właśnie z kolumny OrderID i wartości te, są dostępne na poziomie liści przeszukiwanego indeksu.
Nie trzeba nigdzie więcej szukać danych. Wszystko już mamy. Potrzebowaliśmy tylko CustomerID (to jest wartość klucza nieklastrowego) oraz wartość OrderID, która to z kolei jest kluczem indeksu klastrowego. Takie podejście jest najbardziej efektywne.
Przeanalizujemy inne próby rozwiązania tego zadania, np. z wykorzystaniem funkcji ROW_NUMBER, grupowania i łączenia tabel oraz z zastosowaniem funkcji okna :
-- Query 2 - poprawne ale tylko dla informacji o numerze zlecenia per Klient
-- w ten sposób nie dotrzemy do wszystkich atrybutów tego najnowszego zlecenia.
SELECT CustomerId, MAX(OrderID)
FROM dbo.Orders
GROUP BY CustomerId
-- Query 3
SELECT CustomerId, OrderId
FROM (
SELECT OrderId, CustomerID,
ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY OrderID DESC) AS MaxOrder
FROM dbo.Orders ) AS a
WHERE MaxOrder = 1
-- Query 4
SELECT o.CustomerId, o.OrderId
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID
-- Query 5 - najgorsze z możliwych
SELECT DISTINCT CustomerID,
MAX(OrderID) OVER(PARTITION BY CustomerID ORDER BY OrderID DESC) as MaxOrder
FROM dbo.Orders
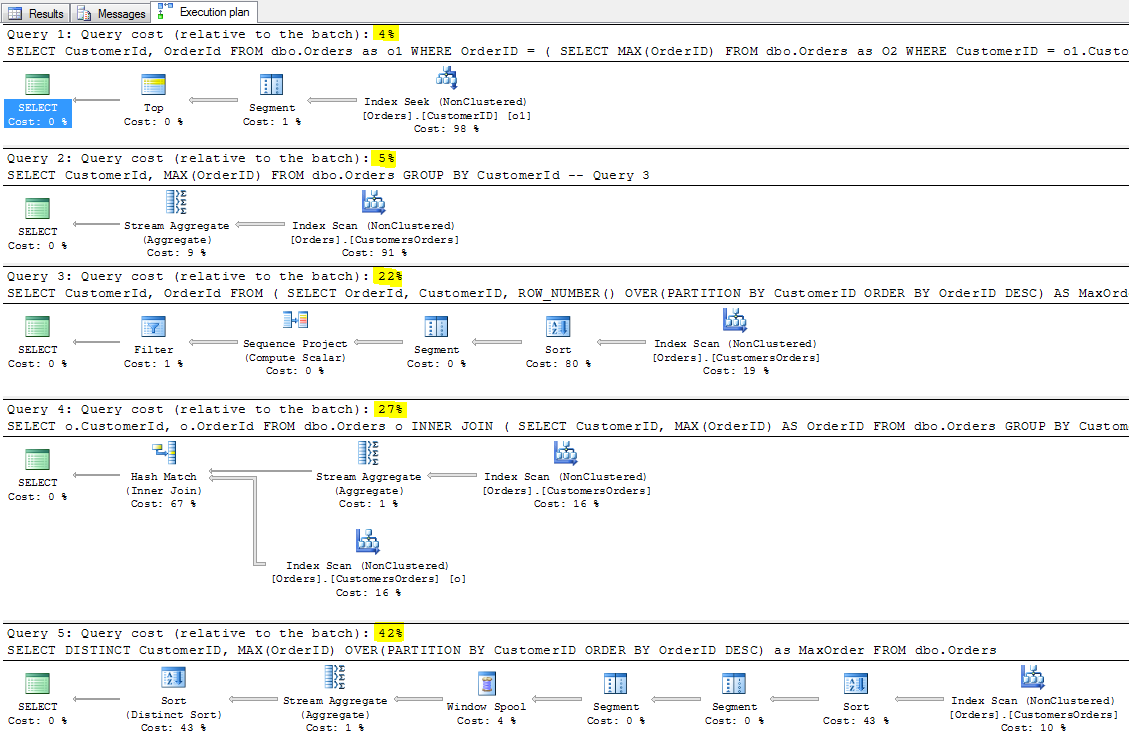
W żadnym z tych przypadków nie osiągniemy takiej efektywności, jakie daje prezentowane jako pierwsze – rozwiązanie z podzapytaniem skorelowanym. Zapytanie numer 2 i 3, pod względem ilości odczytów jest na równi z podzapytaniem skorelowanym.
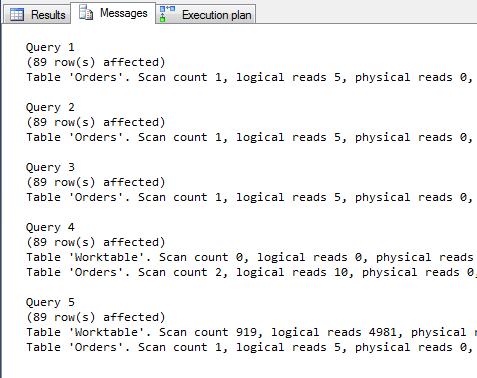
Występują tu jednak takie operacje jak dodatkowe sortowanie czy skan (przeglądanie wszystkich wartości) indeksu, które skutecznie obniżają jego wydajność. Dystans ten będzie się zwiększał wraz z liczebnością elementów w tabeli.
Przykład ten można jeszcze rozwinąć, aby dobitniej pokazać zysk jaki daje w takim scenariuszu podzapytanie skorelowane. Załóżmy że będziemy chcieli wyciągnąć więcej detali niż tylko numer ostatniego zamówienia. Ten dość prosto można było osiągnąć poprzez grupowanie i funkcję MAX(). Teraz interesuje nas jeszcze kraj dostawy ostatniego zamówienia danego Klienta.
Zmodyfikujemy teraz nasze kwerendy. Kwerendę numer 2 od razu musimy skreślić z dalszej analizy, bo bezpośrednio za jej pomocą nie osiągniemy celu. Porównajmy te cztery metody :
-- Query 1
SELECT CustomerId, OrderId, ShipCountry
FROM dbo.Orders as o1
WHERE OrderID = (
SELECT MAX(OrderID)
FROM dbo.Orders as O2
WHERE CustomerID = o1.CustomerID
)
-- Query 2
SELECT CustomerId, OrderId, ShipCountry
FROM (
SELECT OrderId, CustomerID, ShipCountry,
ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY OrderID DESC) AS MaxOrder
FROM dbo.Orders ) AS a
WHERE MaxOrder = 1
-- Query 3
SELECT o.CustomerId, o.OrderId , o.ShipCountry
FROM dbo.Orders o INNER JOIN
(
SELECT CustomerID, MAX(OrderID) AS OrderID
FROM dbo.Orders
GROUP BY CustomerID
) AS MaxOrd ON o.OrderID = MaxOrd.OrderID
-- Query 4 - najgorsze z możliwych
SELECT DISTINCT CustomerID,
MAX(OrderID) OVER(PARTITION BY CustomerID ORDER BY OrderID DESC) as MaxOrder,
ShipCountry
FROM dbo.Orders
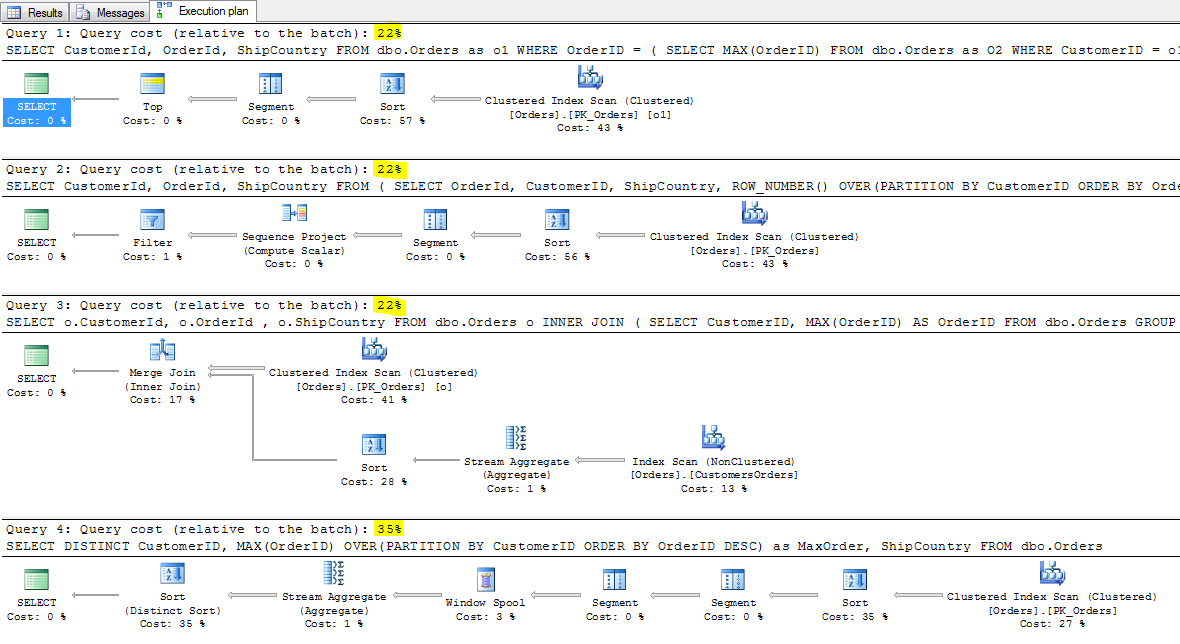

Tym razem, pierwsze trzy zapytania wypadają praktycznie identycznie (dwa pierwsze kosztują dokładnie tyle samo). Zauważ, że w pierwszym przypadku straciliśmy zysk jaki dawało przeszukiwanie indeksu nieklastrowego. Wszędzie są obecnie pełne skany – słabo.
Możemy w prosty sposób poprawić tą sytuację, modyfikując nasz indeks nieklastrowy CustomerID, który poprzednio wykorzystywaliśmy w bardzo efektywny sposób (SEEK). Wystarczy dodać dodatkową kolumnę do definicji klucza (ShipCountry) lub zrobić to bardziej oszczędnie – przekształcając go w indeks pokrywający (INCLUDE) :
USE [Northwind]
GO
DROP INDEX [CustomerID] ON [dbo].[Orders]
GO
CREATE NONCLUSTERED INDEX [CustomerID] ON [dbo].[Orders]
(
[CustomerID] ASC
)
INCLUDE ( [ShipCountry] )
Teraz ponownie widać zysk jaki daje podzapytanie skorelowane. Znów jest wykonywane w nim (Query 1) jedynie przeszukiwanie indeksu nieklastrowego. Na poziomie liści znajdują się wszystkie informacje i nie trzeba nigdzie więcej sięgać.
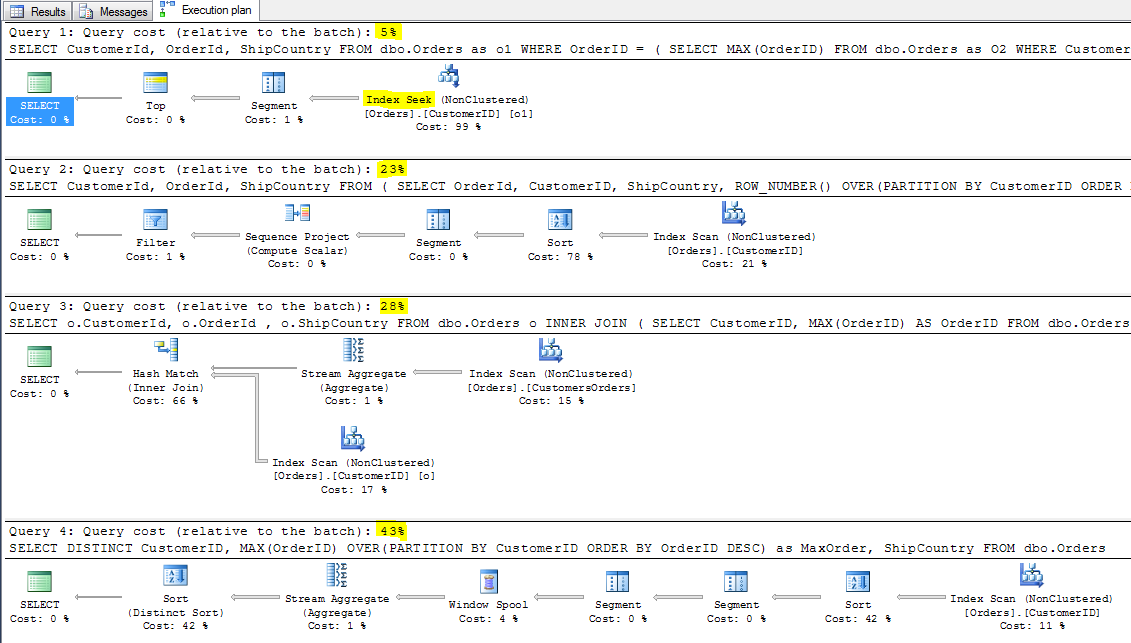
Oczywiście można dywagować, że to kwestia indeksów, sposobu ich posortowania (w kwerendzie z ROW_NUMBER to główny narzut). Tak czy siak, ten przypadek potwierdza postawioną tezę.
Podsumowanie
Istnieją scenariusze w których wydajność podzapytań skorelowanych może być lepsza, od innych – w teorii znacznie lżejszych rozwiązań. W większości przypadków staramy się unikać ich stosowania ze względu na wysoki koszt, gorszą czytelność i ogólnie większą złożonością kwerend.
Na pewno warto znać te konstrukcje, bo niektóre zadania, możemy rozwiązać właściwie tylko za ich pomocą. Szczególnie gdy jesteśmy ograniczeni do pojedynczego zapytania, bez możliwości sięgania po techniki programistyczne, tabele tymczasowe, kursory czy funkcje.
Mam pytanie. Czy możliwa była by wersja kwerendy nr2 w takim wydaniu:
SELECT o1.CustomerId, MAX(o1.OrderID) AS MaxOrderId,
(SELECT ShipCountry
FROM dbo.Orders o2
WHERE o2.OrderID = MAX(o1.OrderID)
) AS ShipCountry
FROM dbo.Orders o1
GROUP BY CustomerId
ORDER BY CustomerId
Spróbuj 😉 i porównaj wyniki…. pozdr
Witam, mam pytanie czemu zostało odrzucona kwerenda nr 2 (kraj dostawy ostatniego zamówienia danego klienta)? Może się mylę, ale za pomocą:
SELECT CustomerId, MAX(OrderId), ShipCountry
FROM dbo.Orders
GROUP BY CustomerID, ShipCountry
Też osiągniemy 89 wierszy z zamówieniami i krajem.
W tym bardzo szczególnym przypadku, pracując na danych które są aktualnie w tabeli dbo.Orders – masz rację, Twój wynik będzie poprawny.
Zauważ jednak, że z czasem mogłoby być tak, że dany Klient (CustomerID), składa zamówienia z różnymi ShipCountry. Wtedy Twoja propozycja zwróci kilka rekordów dla danego Klienta (grupujesz po CustId oraz ShipCountry) i będzie to błąd. Interesuje nas informacja o ostatnim zamówieniu dla danego Klienta, a nie ostatnim zamówieniu z określonego kraju 😉
Masz rację, zaraz po tym jak wysłałem komentarz też ten przypadek wpadł mi do głowy 🙂 Pozdrawiam serdecznie.