Jest to jedna z najbardziej praktycznych i najczęściej stosowanych funkcji szeregujących. Zarys jej możliwości, pokazałem na przykładach, opisujących ogólną składnię funkcji rankingowych. Działają one w oparciu o funkcję okna OVER() i bez niej nie mogą się obyć.
Określa ona kolejny, unikalny numer wiersza w ramach partycji (lub całego zbioru wynikowego) zgodnie z zastosowanym sposobem sortowania.
Use AdventureWorks2008
Go
-- działanie ROW_NUMBER() na całym zbiorze
SELECT P.ProductID, P.Name Product, P.ListPrice,
ROW_NUMBER() OVER( ORDER BY P.ProductID ) AS Pozycja
FROM Production.Product P
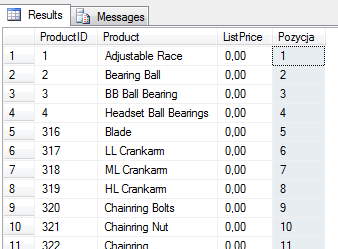
Funkcja ROW_NUMBER() – naturalna (ciągła) numeracja rekordów
ROW_NUMBER() – to funkcja niedeterministyczna. Oznacza to, że jeśli np. dwa rekordy w ramach partycji (podzbioru lub całego zbioru, w zależności czy określony jest element funkcji okna PARTITION BY), posiadają te same wartości w kolumnach po których sortujemy, wartość zwracana przez ROW_NUMBER() będzie dla nich niedeterministyczna czyli w zasadzie losowa. Funkcja deterministyczna, na podstawie tych samych argumentów zwraca zawsze ten sam wynik. W przypadku ROW_NUMBER tak nie jest.
Kolejność elementów w zbiorze np. dla tej samej ceny (przykład poniżej), może być różna – bo przecież nic jej nie wymusza, więc na jakiej podstawie, miała by być określona (zdeterminowana) …
SELECT P.Name Product, P.ListPrice, PSC.Name Category,
ROW_NUMBER() OVER(PARTITION BY PSC.Name ORDER BY P.ListPrice DESC) AS PriceRank
FROM Production.Product P JOIN Production.ProductSubCategory PSC
ON P.ProductSubCategoryID = PSC.ProductSubCategoryID
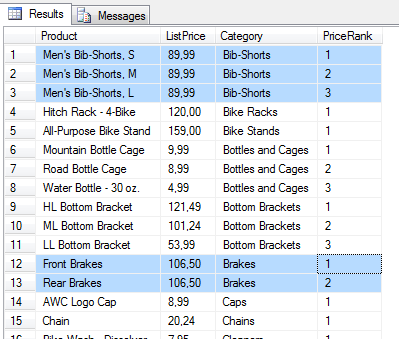
Dla pierwszej partycji rekordów, czyli produktów z podkategorii Bib-Shorts, wartość ListPrice jest równa i wynosi 89,99. To że akurat element „Men’s Bib-Shorts, S” otrzymał wartość funkcji ROW_NUMBER() = 1 a nie np. 2 – zgodnie z teorią zbiorów to czysty przypadek – bo nigdzie jawnie nie zostało określone jak traktować równe wartości elementów (tutaj patrzymy tylko na cenę) w kontekście zbioru. Kolejność przy kolejnych wywołaniach kwerendy, będzie prawdopodobnie taka sama. Warunkowana jest tylko fizycznym składowaniem danych w tabeli. Może się to jednak zmienić wskutek modyfikacji danych.
Co innego jeśli jawnie określimy sposób sortowania w ramach podzbioru, dodatkowo po nazwie :
SELECT P.Name Product, P.ListPrice, PSC.Name Category,
ROW_NUMBER() OVER(PARTITION BY PSC.Name ORDER BY P.ListPrice DESC , P.Name ) AS PriceRank
FROM Production.Product P JOIN Production.ProductSubCategory PSC
ON P.ProductSubCategoryID = PSC.ProductSubCategoryID
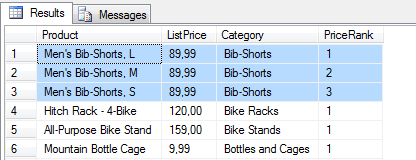
Teraz, kolejność jest wymuszona i zakładając, że wartości w kolumnie P.Name są unikalne w ramach podkategorii – funkcja będzie zachowywała się w sposób deterministyczny.
Trzeba być tego świadomym, bo brak znajomości mechanizmów działania funkcji – może prowadzić do błędów logicznych w aplikacji. Czasami takie błędy wychodzą dopiero wiele miesięcy po wdrożeniu (na testowych, lub fragmentarycznych danych wszystko działało ok.).
Stronnicowanie przy użyciu ROW_NUMBER()
Innym przykładem zastosowania tej funkcji jest realizacja stronnicowania rekordów. Sposobów na realizację tego zadania jest wiele. Poniżej sposób, bazujący na prostej kwerendzie z wykorzystaniem ROW_NUMBER(), która zwraca nam określoną liczbę rekordów (stronę). Przypominam, aby pamiętać o determinizmie, który może być wymagany w danym rozwiązaniu :
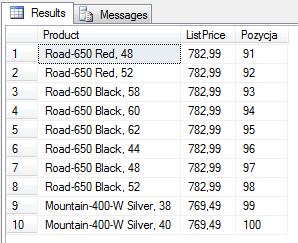
with paging as (
SELECT P.Name Product, P.ListPrice,
ROW_NUMBER() OVER( ORDER BY P.ListPrice DESC) AS Pozycja
FROM Production.Product P
)
-- np. 10 strona, wiersze od 91-100
select * from paging where Pozycja between 91 and 100
go
Porównanie wydajności do zapytań skorelowanych
Alternatywą do numerowanie wierszy za pomocą ROW_NUMBER(), jest stosowanie np. podzapytań skorelowanych (w SQL Server 2000 nie było dostępnych funkcji rankingowych). Jest to jednak sposób znacznie mniej wygodny i wydajny niż za pomocą wbudowanej funkcji rankingowej.
Aby się o tym przekonać możemy porównać statystyki wykonania dwóch kwerend (najlepiej uruchomić je razem, w jednym batchu, dodatkowo warto włączyć opcję „Include Actual Execution Plan” oraz statystyki IO.
SET STATISTICS IO ON
-- Query1 = old one SQL Server 2K
select ProductId, Name,
(
select count(*)
FROM Production.Product P2
where P2.ProductId <= P.ProductID
) as RowNum
FROM Production.Product P
-- Query2 = new one since SQL 2K5
select ProductId, Name, ROW_NUMBER() OVER( ORDER BY P.ProductID ) AS Pozycja
FROM Production.Product P
Obydwie kwerendy zwróciły to samo, ale zerknijmy na statystykę wykonania :
(504 row(s) affected) Table 'Product'. Scan count 505, logical reads 4235, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (504 row(s) affected) Table 'Product'. Scan count 1, logical reads 15, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
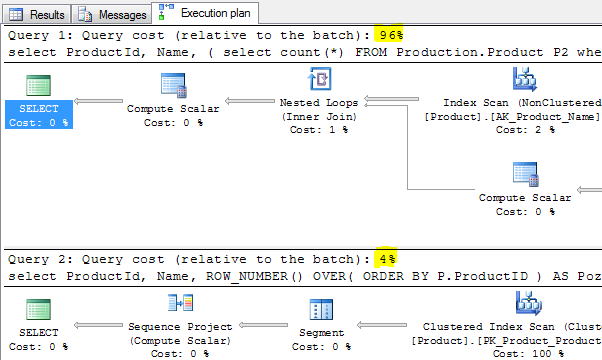
Wynik mówi sam za siebie – w trakcie wykonania części pierwszej (zapytanie skorelowane), wykonanych zostało 4235 logicznych odczytów i 505 skanów indeksu. Zapytanie z ROW_NUMBER() kosztowało 15 odczytów i 1 index scan. Ponadto przypadek drugi pochłonął tylko 4% całkowitego kosztu wykonania skryptu.
hej,
jedna rzecz mi nie pasuje…
dlaczego w rezultacie 1szego zapytania w kolumnie „Pozycja” nie ma samych jedynek?
w moim rozumieniu zapytanie to robi ranking tak jakby bylo partycjonowane po kazdej kolumnie.
Sprawdzilem tez to zapytanie u siebie lokalnie i tez nie mam samych jedynek.
czy moze mi ktos wytlumaczyc dokladnie jak dziala 1sze zapytanie z powyzszego artykułu, czyli to:
dzieki!
Marek
No nie jest to akurat partycjonowane wogóle… żeby było, trzeba by było użyć PARTITION BY a w tym zapytaniu tego wogóle nie ma więc cały zbiór to jedna wielka partycja. Czyli np tak :