CTE, czyli wspólne wyrażenia tablicowe, zostały wprowadzone po raz pierwszy w SQL Server 2005, jako rozszerzenie składni T-SQL.
Upraszczają i poprawiają przejrzystość kodu SQL. W tym zakresie, ich stosowanie nie ma wpływu na wydajność zapytań, tylko na jego czytelność. Oprócz funkcji czysto estetycznej, posiadają jeszcze jedną, specjalną właściwość – ich struktura pozwala na realizację rekurencji.
Wspólne wyrażenia tablicowe CTE – czytelność kodu
CTE, możemy stosować praktycznie wszędzie – w widokach, funkcjach, procedurach składowanych, skryptach etc. Składnia jest prosta i omówię ją na przykładzie :
-- definicja wyrażenia tablicowego o nazwie Sales_CTE
WITH Sales_CTE (SalesPersonID, NumberOfOrders, MaxDate)
AS
(
SELECT top 5 SalesPersonID, COUNT(*) , MAX(OrderDate)
FROM Sales.SalesOrderHeader
GROUP BY SalesPersonID
ORDER BY 2 ASC
)
-- bezpośrednio po definicji, kwerenda odwołująca się m.in do tego CTE
SELECT P.FirstName, P.LastName, c.NumberOfOrders, c.MaxDate
FROM Sales_CTE c left join Person.Person AS P
ON c.SalesPersonID = P.BusinessEntityID

Definicję CTE otwiera słowo kluczowe WITH z nazwą zbioru, który zostanie za jej pomocą utworzony. Do niej będziemy odwoływać się w kwerendzie, tak jak do zwykłej tabeli.
Obowiązują te same reguły jak w przypadku każdego obiektu tabelarycznego, do którego chcemy się w jakikolwiek sposób odnosić w zapytaniu.
Nazwy kolumn (atrybutów) muszą być unikalne w ramach zbioru. Jeśli określimy je w „ciele” wyrażenia tablicowego, nie jest wymagane ich ponowne nazywanie w klauzuli WITH – co jest często stosowanym skrótem. W kodzie produkcyjnym, zalecane jest jednak jawne wyszczególnianie nazw.
WITH Sales_CTE
AS
( -- określenie unikalnych nazw kolumn
SELECT SalesPersonID, COUNT(*) as NumberOfOrders ,
MAX(OrderDate) as MaxDate
FROM Sales.SalesOrderHeader
GROUP BY SalesPersonID
)
SELECT * from Sales
Do raz zdefiniowanego CTE, możemy się odnosić wiele razy w kwerendzie z którą jest związany. Zakres widoczności jest bardzo wąski i obejmuje tylko i wyłącznie zapytanie następujące po nim, ale w pełnym zakresie. Dokładnie tak jakbyśmy odpytywali zbiór, tabelę lub widok, określoną w tym przypadku przez CTE.
Możemy definiować kilka wyrażeń tablicowych i co istotne, widoczne są one nie tylko w kwerendzie powiązanej z WITH, ale również w kolejno określanych CTE (jeśli jest ich więcej niż 1)
WITH CTE_1 -- definicja pierwszego CTE
AS
(
SELECT SalesPersonID, COUNT(*) as NumberOfOrders ,
MAX(OrderDate) as MaxDate
FROM Sales.SalesOrderHeader
GROUP BY SalesPersonID
),
CTE_2 -- definicja drugiego CTE, możemy odwołaś się już do CTE_1
AS
(
SELECT SalesPersonID, NumberOfOrders, MaxDate
FROM CTE_1
WHERE NumberOfOrders < 200
)
-- tutaj możemy odwołać się do wszystkich CTE określonych w WITH
SELECT top 10 CTE_1.*, CTE_2.*
FROM CTE_1 LEFT JOIN CTE_2
ON CTE_1.SalesPersonID= CTE_2.SalesPersonID
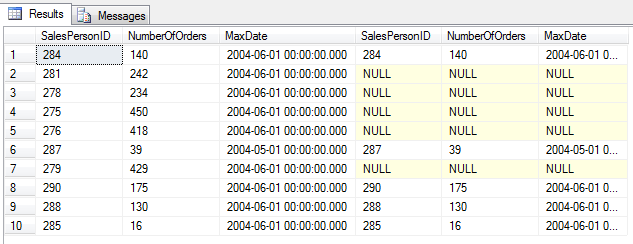
CTE są szczególnie użyteczne w przypadku rozbudowanych zapytań, łączących wiele tabel, które chcemy użyć w kolejnym kroku, wykonując na nich dodatkowe operacje.
Inny przykład zastosowań to skomplikowane wyrażenia w klauzuli SELECT (np. z CASE WHEN) zapytania, które również chcemy dalej przetwarzać, np. połączyć wewnętrznie z samą sobą. Nie będziemy musieli powielać tego samego kodu zapytania lub materializować (choć czasem się opłaca) tabeli pośredniej.
CTE jest po prostu wygodnym opakowaniem, tabel pośrednich, dzięki któremu łatwiej odnaleźć się w kodzie.
Trzeba pamiętać, że słowo kluczowe WITH, używane jest również do innych celów np. do przekazywania hintów (podpowiedzi dla silnika relacyjnego) w zapytaniach. Z tego względu, jeśli chcemy definiować CTE w ramach skryptu zawierającego kilka odrębnych komend T-SQL np. w procedurze składowanej, konieczne jest jawne określania końca poleceń poprzedzających – czyli stosowanie znaku średnika, przynajmniej na końcu polecania SQL poprzedzającego CTE.
Jeśli o tym zapomnimy – parser, zasygnalizuje błąd, bo będzie traktował słowo kluczowe WITH jako kontynuację poprzedniej komendy SQL. Stosowanie ’;’ jest jedną z dobrych praktyk pisania poleceń SQL i nic nie stoi na przeszkodzie, aby umieszczać je zawsze na koniec komendy.
Rekurencyjne wyrażenia tablicowe (recursive CTE)
Interesującą i bardzo użyteczną właściwością wspólnych wyrażeń tablicowych, jest możliwość stosowania rekurencji w ich wnętrzu. Tego typu funkcjonalność, wykorzystujemy w zbiorach z określoną hierarchią elementów (pracownicy / przełożeni, struktura folderów na dysku, wątków na forum itp.). Rekurencja pozwala rozwiązywać skomplikowane zadania, typu wyznaczanie drzew rozpinających, grafów.
Składnię rekurencyjnych wyrażeń CTE, przeanalizujemy na przykładzie hierarchicznej struktury zatrudnienia w firmie Northwind:
USE NORTHWIND
GO
WITH recursive_CTE
AS
(
-- zapytanie zakotwiczające, określa korzeń, najwyższy poziom hierarchii
-- w tym przypadku tylko TOP Management (nie mają przełożonych)
select EmployeeId, ReportsTo, FirstName, LastName, 0 as Organization_Level
from dbo.Employees
where ReportsTo is null
-- operator UNION ALL – obowiązkowy w rekurencji,
-- łączący ostetecznie wyniki z kolejnych iteracji (przebiegów) wykonania
UNION ALL
-- Zapytanie rekurencyjne działające zawsze na zbiorze wynikowym z kroku n-1.
-- Zwróć uwagę, że jest powiązane po nazwie wyrażenia tablicowego CTE
select e.EmployeeId, e.ReportsTo, e.FirstName, e.LastName, Organization_Level + 1
from dbo.Employees e inner join recursive_CTE r
on e.ReportsTo = r.EmployeeId
)
Select * from recursive_CTE
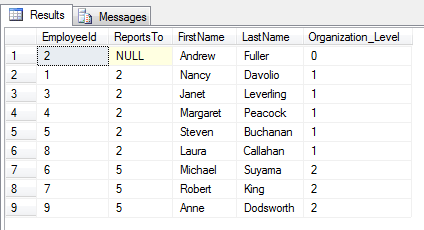
Definicja wyrażeń rekurencyjnych CTE składa się z 3 elementów.
- rozpoczyna się przez określenie zapytania zakotwiczającego. Jest to zazwyczaj zbiór elementów stanowiących korzeń (lub korzenie). W naszym przykładzie jest to TOP management czyli pracownicy, którzy do nikogo nie raportują. Od tych elementów będziemy rekurencyjnie „rozpinać” nasze struktury drzew.
- Zapytanie rekursywne – skorelowane z wynikiem zwracanym przez zapytanie poprzednie. To tu odwołujemy się do struktury hierarchicznej. W naszym przypadku, w pierwszym kroku jest to powiązanie TOP managementu z bezpośrednimi podwładnymi. W następnym kroku, będzie to powiązanie tych bezopśrednich podwładnych z ich własnymi podwładnymi czyli kolejny poziom niżej itd.
Operator UNION ALL łączy wszystkie przebiegi w finalny zbiór wynikowy. Ważne jest, aby zrozumieć, że w każdym kroku działamy tylko na zbiorze zwracanym przez krok poprzedni (u nas to będzie za każdym razem, zbiór pracowników, kolejnego, niższego szczebla). - – Niejaweny warunek zakończenia rekurencji. Jeśli zapytanie rekurencyjne, skorelowane, nie zwróci żadego elementy, działanie CTE zostaje porzerwane.
Istnieje kilka istotnych faktów związanych z tą strukturą. Warunek zakończenia jest niejawny, dlatego jeśli w naszych danych występują cykle, i rekurencja wpadnie w taką pętle, zapytanie CTE zostanie przerwane dopiero po osiągnięciu maksymalnego poziomu – 32767 przebiegów.
Może to trwać bardzo długo. Na szczęście możemy jawnie określić maksymalną ilość wykonywanych przebiegów za pomocą opcji MAXRECURSION :
WITH recursive_CTE
AS
(
select EmployeeId, ReportsTo, FirstName, LastName, 0 as Organization_Level
from dbo.Employees
where ReportsTo is null
UNION ALL
select e.EmployeeId, e.ReportsTo, e.FirstName, e.LastName, Organization_Level + 1
from dbo.Employees e inner join recursive_CTE r on e.ReportsTo = r.EmployeeId
)
Select * from recursive_CTE
option (maxrecursion 1)
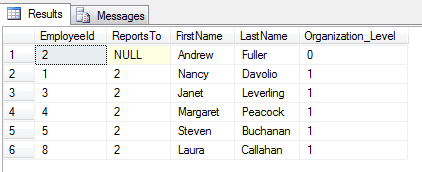
W sytuacji gdy CTE samo nie zakończy działania na n-tym przebiegu, czyli jeśli zwróci w n-tym kroku niepusty zbiór, opcja 'MAXRECURSION n’ wymusi jej zakończenie. Zostanie również zwrócona informacji o błędzie :
Msg 530, Level 16, State 1, Line 2 The statement terminated. The maximum recursion 1 has been exhausted before statement completion.
Jeśli chcemy umieszczać tego typu „hamulce”, trzeba zapewnić obsługę błędów (np. za pomocą try catch). Maksymalna liczba przebiegów które możemy z góry określić za pomocą MAXRECURSION to 32767. Ewentualnie pozostaje opcja „infinitive” czyli MAXRECURSION = 0.
ostatni ratunek przed dzisiejszym kolosem, super wytłumaczone!
Prosto i na temat.
Świetnie wyjaśnione – w przystępnej formie 🙂
Swietne wytlumaczenie.
Moja ulubiona strona, polecam wszystko wyjaśnione krok po kroku.
za…isty art!!!
Hmm, w C++ rekurencja była jakby bardziej zrozumiała, ja rekurencję rozumiem tutaj jako pętlę, której warunkiem zakończenia jest zwrócenie niczego w joinie.
Rekurencja to nie pętla, pętla jest iteracyjna. Rekurencja to definicja, która używa do definiowania obiektu definiowanego. Np. silnię można zapisać rekurencyjnie i iteracyjnie:
np.
rekurencyjnie: n! = n * (n-1)!
iteracyjnie: n! = ILOCZYN(od 1 do n)
ale nie wszystkie algorytmy rekurencyjne da się zapisać iteracyjnie.
SQL nie jest językiem programowania, ale rekurencja nie jest przywiązana do języków programowania. W językach programowania rekurencja jest wtedy gdy funkcja którą definiujesz wywołuje sama siebie, np:
long silnia(long n) {
if (n <= 1) return 1;
else return n * silnia(n – 1);
}
W SQLu oczywiście może występować silnia, jeśli CTE definiujesz przy użyciu tego samego CTE, tak jak w podanym tutaj przykładzie.
Super, lepszego wyjaśnienia CTE nie znalazłem. Polecam!
Świetna strona.