Polecenie BULK INSERT jest rozszerzeniem języka T-SQL, funkcjonalnym odpowiednikiem narzędzia bcp z parametrem in. Za jego pomocą możemy wykonać szybki, masowy import danych z pliku tekstowego do istniejącej tabeli w bazie danych – z poziomu skryptu T-SQL. Idealnie nadaje się więc do automatyzacji zadań, definiowanych np. w JOBach, procedurach składowanych, czy skryptach adhoc, mających na celu import danych z plików tekstowych do bazy.
Artykuł ten ma na celu pokazanie najczęściej stosowanych parametrów, praktyczne przykłady użycia BULK INSERT.
Import surowej zawartości pliku tekstowego do tabeli
W najprostszym zastosowaniu, możemy zaimportować dowolny plik tekstowy do istniejącej tabeli w bazie SQL Server. Bardziej skróconej wersji zastosowania BULK INSERT nie ma.
create table dbo.test
(
Full_Row varchar(1000)
)
BULK INSERT dbo.test
FROM 'C:\temp\plik.txt'
Jest to najkrótsza i najskromniejsza komenda BULK INSERT. W tym przypadku, zastosowane będą domyślne znaczniki końca wartości kolumny (atrybutu) tzw. FIELDTERMINATOR którym będzie symbol /t czyli tabulator. Drugim istotnym symbolem – końca wiersza – ROWTERMINATOR będzie domyślnie złączenie /n/r, next row + carriage return. Ponieważ ładujemy wszystko do tabeli tymczasowej, która posiada tylko jedną kolumnę (Full_Row), domyślny znacznik FIELDTERMINATOR, nie będzie zastosowany. Każdy wiersz czytanego pliku, będzie ładowany do nowego wiersza tej tabelki.
Powyższa składnia jest o tyle przyjemna, że można w ten sposób wrzucić do tabeli tymczasowej zawartość dowolnego pliku tekstowego w zasadzie bez rozróżniania jego struktury, biorąc pod uwagę tylko koniec wiersza.
Import strukturyzowanej zawartości pliku tekstowego do tabeli
W typowej sytuacji importu, przechowujemy dane zorganizowane w określony sposób. Plik tekstowy reprezntuje, zazwyczaj tabelaryczny zbiór elementów, opisany za pomocą atrybutów (kolumn), których wartości rozdzielone są znakiem specjalnym (FIELDTERMINATOR).
Importując dane, musimy zadbać aby liczba kolumn, typy danych, były zgodne pomiędzy tabelą docelową a zawartością pliku. W przypadku niedopasowania typu danych oraz braku możliwości wykonania niejawnej konwersji typu danych, otrzymamy komunikat :
Msg 4864, Level 16, State 1, Line 2 Bulk load data conversion error (type mismatch or invalid character for the specified codepage) for row 1, column 3 (kolumna).
Skupmy się jednak na składni BULK INSERT. Żeby jawnie określić znaki terminujące wartości kolumn oraz wiersza (elementu), stosujemy parametry FIELDTERMINATOR oraz ROWTERMINATOR. Określane są one w bloku WITH.
Zawartość pliku który będziemy chcieli zaimportować niech wygląda tak :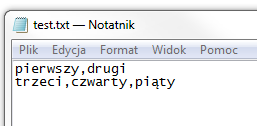
Jak widać, są w nim dwa wiersze, składające się z dwóch oraz trzech wartości. W takim razie do dzieła :
use TempDB
go
IF OBJECT_ID('dbo.test') is not null drop table dbo.test
create table dbo.test
(
Field1 varchar(1000),
Field2 varchar(1000)
)
-- tutaj zaczyna się import z pliku C:\temp\test.txt do tabeli dbo.test
BULK INSERT dbo.test
FROM 'C:\temp\test.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
CODEPAGE = 'ACP' -- | 'OEM' | 'RAW' | 'code_page'
)
select * from dbo.test
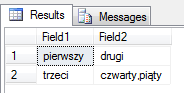
W powyższym przykładzie zastosowałem parametr opcjonalny CODEPAGE, który określa stronę kodową znaków. ACP czyli kodowanie ANSI. W zależności od zawartości importowanego pliku, możemy zastosować inną, odpowiednią dla naszego środowiska stronę kodową (code_page).
Zauważ, że liczba atrybutów (kolumn) w pliku jest różna. W tej sytuacji nastąpi próba dopasowania struktury pliku do tabeli docelowej. W wierszu drugim, wartość czwarty,piąty została potraktowana jako jedna (druga kolumna).
Gdy importowane dane zawierają różne liczby kolumn oraz operacja niejawnego dopasowania jest możliwa – zostanie to wykonane. Należy jednak uważać na tego typu wyjątki, operacje importu/eksportu powinny być ściśle określone aby uniknąć pomyłek. Najlepiej w tym celu stosować dodatkowego parametru określającego plik formatu FORMATFILE (fmt). Tworzymy go np. za pomocą bcp i zawiera on informację o strukturze przechowywanych danych.
W przypadku braku możliwości dopasowania, lub jeśli np n-ty wiersz importowanych danych będzie zawierał mniej kolumn niż oczekuje tego struktura tabeli docelowej – otrzymasz następujacy, niewiele mówiący komunikat o błędzie.
Msg 4832, Level 16, State 1, Line 13 Bulk load: An unexpected end of file was encountered in the data file. Msg 7399, Level 16, State 1, Line 13 The OLE DB provider "BULK" for linked server "(null)" reported an error. The provider did not give any information about the error. Msg 7330, Level 16, State 2, Line 13 Cannot fetch a row from OLE DB provider "BULK" for linked server "(null)".
Pozostałe przydatne opcje BULK INSERT
FIRSTROW – od którego wiersza z pliku importować (wartość integer).
LASTROW – który wiersz ma być tym ostatnim (wartość integer).
KEEPNULLS – w trakcie importu możesz się spotkać z sytuacją, że będziesz importował dane zawierające null w kolumnach, na których jest zdefiniowana wartość domyslna (DEFAULT VALUE). W większości przypadków operacja eksportu i importu, powinna być symetryczna. Dlatego jeśli chcesz być pewien, że importowane dane będą dokładnie odzwierciedlone w tabeli docelowej (nie zostanie zamieniony NULL na DEFAULT VALUE) – skorzystaj z tej opcji.
KEEPIDENTITY – zachowuje oryginalne wartości IDENTITY w tabeli do której importujemy, nawet jeśli dane dla tej kolumny są określone. Właściwość wyłączania mechanizmów integralności wewnętrznej danych (constraints, foreign_keys) jest charakterystyczna dla importu masowego.
Poniższy przykład obrazuje zachowanie KEEPIDENTITY.
use tempdb
go
IF OBJECT_ID('dbo.test') is not null drop table dbo.test
create table dbo.test
(
-- na kolumnie id jest IDENTITY, powinno więc ono nadawać
-- kolejne numery wierszy poczynając od 1
id int IDENTITY(1,1),
Field varchar(1000)
)
GO
BULK INSERT dbo.test
FROM 'C:\temp\test2.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
KEEPIDENTITY
)
-- 3 razy zostanie wykonany BULK INSERT - GO 3
GO 3
select * from dbo.test

Jak widać, pomimo istnienia IDENTITY na kolumnie Id – numeracja jest zgodna z danymi importowanymi z pliku.
FIRE_TRIGGERS – domyślnie w operacji BULK INSERT wszystkie triggery związane z operacją INSERT na danej tabeli są wyłączone. Operacja BULK INSERT jest importem masowym. W domyśle stosowany do zasilenia bazy maksymalnie szybko, dużymi ilościami danych. Często zależy nam na tym, aby wszelkiego rodzaju spowalniacze były domyślnie wyłączone – właśnie z powodu apsketu wydajnościowego.
Jeśli jednak od działania triggerów zależy spójność danych i powinny zostać wywołane, trzeba jawnie określić ich włączenie tym parametrem.
Pamiętać trzeba, że w SQL Server, triggery wywoływane są w kontekście całego batcha. Jeśli cały import jest wykonywany w jednym logicznym kroku (batch’u), triggery będą wywołane raz dla wszystkich wierszy. Jeśli import podzielony zostanie na n-batch’y (opcje BATCHSIZE i KILOBYTES_PER_BATCH), triggery wykonają się n razy na n partiach ładowanych wierszach.
Poniżej mały przykład pokazujący, że bez FIRE_TRIGGER w trakcie importu BULK INSERT, zdefiniowane triggery, na tabeli do której importujemy, nie działają.
use tempdb
go
IF OBJECT_ID('dbo.test') is not null drop table dbo.test
IF OBJECT_ID('dbo.test_arch') is not null drop table dbo.test_arch
create table dbo.test
(
id int identity(1,1),
Field1 varchar(1000)
)
GO
create table dbo.test_arch
(
id int identity(1,1),
Field_Arch varchar(1000)
)
GO
-- na tabeli dbo.test tworzymy trigger, który w ciemno kopiuje
-- wszystko co jest insertowane do dbo.test do tabeli dbo.test_arch
CREATE TRIGGER arch
on dbo.test
AFTER INSERT
AS
BEGIN
insert into dbo.test_arch
select 'new_' + Field1 from inserted
END
GO
BULK INSERT dbo.test
FROM 'c:\temp\test2.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
)
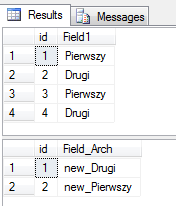
select * from dbo.test
select * from dbo.test_arch
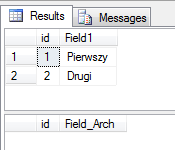
Tym razem BULK INSERT z opcją FIRE_TRIGGER
BULK INSERT dbo.test
FROM 'c:\temp\test2.txt'
WITH
(
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
FIRE_TRIGGERS
)
select * from dbo.test
select * from dbo.test_arch
CHECK_CONSTRAINTS – podobnie jak triggery, domyślnie wszelkie ograniczenia sprawdzające, w tym również klucze obce, są ignorowane w trakcie wykonywania importu masowego. Wynika to z definicji – import masowy ma być wykonywany maksymalnie szybko, dane powinny być wcześniej zweryfikowane.
Po imporcie wszelkie ograniczenia na tabeli są oznaczane flagą not-trusted. Może skutkować to poważnymi konsekwencjami, nie tylko z punktu widzenia zachowania spójności danych, ale także degradacją wydajności wykonywanych zapytań. Po imporcie masowym, wszelkie ograniczenia (constraints oraz foreign_keys) powinny zostać zweryfikowane i oznaczone jako trusted.
Jeśli chcesz szybko znaleźć informacje o niezaufanych ograniczeniach wykonaj po imporcie następujące zapytanie :
SELECT OBJECT_NAME(parent_object_id) AS table_name, name, is_disabled , is_not_trusted
FROM sys.check_constraints
Where is_not_trusted = 1 or is_disabled = 1
UNION ALL
SELECT OBJECT_NAME(parent_object_id) AS table_name, name, is_disabled , is_not_trusted
FROM sys.foreign_keys
Where is_not_trusted = 1 or is_disabled = 1
ORDER BY table_name
Da ono odpowiedź o wszystkich niezaufanych lub wyłączonych ograniczeniach. Żeby teraz na nowo aktywować/sprawdzić i oznaczyć jako zaufane, należy wykonać polecenie z double check.
-- sprawdzi i oznaczy jako zaufane (o ile nie będzie w kolumnach nieprawidłowych wartości)
-- wszystkie ograniczenia na tabeli dbo.tabela
ALTER TABLE dbo.tabela WITH CHECK CHECK CONSTRAINT all
Jeśli chcesz wykonać aktualizację na wszystkich tabelach w bazie, możesz do tego celu zastosowwać nieudokumentowną, ale użyteczną procedurkę sp_msforeachtable :
exec sp_msforeachtable 'ALTER TABLE ? WITH CHECK CHECK CONSTRAINT all'
KILOBYTES_PER_BATCH oraz BATCHSIZE – określają podział importu na n części, wykonywanych w osobnych transakcjach. Paczki (batche) mogą być określone przez liczbę rekordów (BATCHSIZE) lub wielkość bezwzględną wyrażoną w KB.
TABLOCK – zakłada blokadę na całej tabeli do której importujemy dane. Przyspiesza to czas wykonania importu.
ORDER – określa sposób sortowania przed importem, aby również przyspieszyć jego wykonanie. Ma to szczególne znaczenie, gdy importujemy do tabeli z indeksem klastrowym, wtedy dodając posortowane elementy zgodnie z jego definicją, operacje przebudowy i utrzymania indeksu w trakcie importu są zoptymalizowane.
FORMATFILE – określa ścieżkę do pliku przechowującego informacje o metadanych importowanej struktury. Plik formatu możesz utworzyć za pomocą narzędzia bcp, jako część eksportu. Przydaje się w szczególności, gdy np. wykesportowane dane mają zamienione kolejności kolumn w stosunku do struktury tabeli do której je importujemy lub poprostu ich liczba się różni.