Poznając możliwości języka SQL, bardzo szybko dochodzimy do wniosku, że identyczny zbiór wynikowy można uzyskać na wiele różnych sposobów. Jest to moim zdaniem jedna z fajniejszych cech tego języka. Podobnie jak w programowaniu czy ogólnie algorytmice, stawiane jest wyzwanie – osiągnąć cel najniższym kosztem.
Artykuł ten jest wprowadzeniem do zagadnień związanych z optymalizacją zapytań. Temat ten jest tak obszerny, że nie sposób umieścić w krótkim rozdziale tego kursu wszystkich (czy nawet najważniejszych) aspektów związanych z badaniem wydajności. Nie mniej jednak, chciałbym Tobie przybliżyć podstawy, związane z fizycznym wykonywaniem zapytań w SQL Server. Omówić metodologię pomiarów oraz narzędzi związanych z badaniem i porównywaniem wydajności zapytań.
Na początek kilka słów na temat przetwarzania zapytań w SQL Server, buforowania planów i wyjaśnienie w jaki sposób przygotować środowisko do testów i badania wydajności zapytań.
Wykonywanie zapytań w SQL Server
Sam proces wykonywania kwerendy jest ostatnim z kilku etapów przetwarzania. Każde nowe zapytanie wysłane do serwera bazy danych jest realizowane w następujących krokach :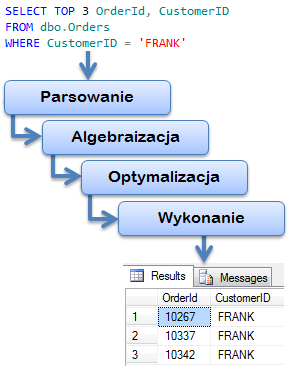
- Sprawdzenie poprawności syntaktycznej (parsowanie). Na tym etapie weryfikacji podlega tylko sama składnia, czy zachowany jest szyk słów kluczowych, poprawność użytych znaków (literówki w słowach kluczowych), nawiasów, cudzysłowów itd.
- Algebraizacja – wieloetapowe przetwarzanie wstępne. Jeśli kwerenda jest poprawna pod kątem składniowym, weryfikacji podlegają wszystkie obiekty (tabele, kolumny czy funkcje) do których się odwołujemy – rozwiązywanie nazw. Sprawdzane są także szczegółowo uprawnienia a także wykonywana jest analiza pod kątem późniejszych operacji (np. grupowania) – tworzone jest drzewo wyrażeń.
- Optymalizacja – przygotowanie planów wykonania zapytania i wybór optymalnego. Do każdego celu można dojść różnymi drogami. Szukając nazwiska w książce adresowej, można posłużyć się indeksem lub przekartkować całość. W zależności od jakości indeksu, może okazać się, że szybciej znajdziemy poszukiwany rekord przeglądając całą książkę. Podobnie jest w SQL. Przygotowywane są różne plany wykonania (ale nie wszystkie możliwe, bo to mogłoby zająć znacznie więcej czasu niż wykonanie nawet najgorszego z nich). Następnie wybierany jest najlepszy spośród znalezionych (może to być pierwszy lepszy, jeśli spełni określone kryteria optymalizatora). Wybrany plan wykonania jest umieszczany w specjalnym buforze – do ewentualnego wykorzystanie w przyszłości. Dzięki temu ponowne wykonanie tej samej kwerendy, może zostać wykonane znacznie szybciej, bo z pominięciem wcześniejszych kroków.
- Wykonanie zapytania zgodnie z wybranym planem, fizyczne i logiczne odczytywanie danych.
- Zwrócenie rezultatu
Jak widać droga od zadania pytania do otrzymania odpowiedzi jest długa i w praktyce pochłaniać może sporo czasu. Z punktu widzenia wydajności serwera, bardzo ważne jest, aby czas i zasoby poświęcone na utworzenia planu wykonania, nie były zmarnowane. Dlatego istotne jest buforowanie planów i ponowne ich wykorzystanie w momencie pojawienia się tego samego (lub podobnego, ale o tym później) zapytania.
Buforowanie planów wykonania
Temat buforowania planów i umiejętność ich wielokrotnego wykorzystania, jest szczególnie istotna dla programistów, aby świadomie optymalizować obciążenie serwera. Jeśli interesują Cię aspekty wydajnościowe, ważne aby zrozumieć w jaki sposób badać wydajność całego procesu.
Porównując dwie kwerendy, chcemy zazwyczaj mierzyć pełen czas ich „kompilacji” – od wysłania zapytania do otrzymania wyniku, a nie tylko kolejne wywoływania z pamięci podręcznej już przetworzonych zapytań. W dalszej części pokażę, na czym polega buforowanie planów i dlaczego w procesie pomiarowym, należy czyścić pamięć podręczna i bufory SQL Server.
Przygotujmy środowisko do testów. Użyjemy do tego dwóch procedur : DBCC FREEPROCACHE oraz DBCC DROPCLEANBUFFERS związanych z czyszczeniem pamięci podręcznej z planów i buforów (dane). Dodatkowo, można wywołać jawny CHECKPOINT, czyli zrzucenie dirty-pages z pamięci na dysk, aby zapobiec wystąpieniu tego cyklicznego zdarzenia w trakcie wykonywania kwerendy, co mogłoby wypaczyć ewentualne wynik porównań. W dalszej części, będę zawsze wykonywał poniższy tercet, chcąc rozpocząć dowolny test w czystym środowisku.
USE NORTHWIND
GO
-- Uwaga ! używaj tylko w celach edukacyjnych na serwerze testowym :)
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT
GO
W tym momencie stan pamięci / buforów naszej instancji SQL Server, jest zupełnie wyczyszczony. Możemy zacząć testować. Wykonajmy pierwsze zapytanie i od razu sprawdźmy, co znajduje się w cache :
SELECT * FROM dbo.Orders
GO
-- sprawdzenie informacji o istniejących planach w cache
SELECT qt.TEXT as SQL_Query, usecounts, size_in_bytes ,
cacheobjtype, objtype
FROM sys.dm_exec_cached_plans p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) qt
WHERE qt.TEXT not like '%dm_exec%'

Za pomocą widoku systemowego (DMV) sys.dm_exec_cached_plans, możemy zajrzeć do bufora planów. Widać w nim nasze zapytanie, z kilkoma podstawowymi informacjami m.in. o rozmiarze skompilowanego planu i liczniku wykonania. Teraz wykonajmy jeszcze kilka, niemal identycznych kwerend :
SELECT * FROM dbo.Orders
GO 3
SELECT * FROM Orders
GO
SELECT * FROM Orders
GO
SELECT qt.TEXT as SQL_Query, usecounts, size_in_bytes ,
cacheobjtype, objtype
FROM sys.dm_exec_cached_plans p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) qt
WHERE qt.TEXT like '%Orders%'
and qt.TEXT not like '%dm_exec %'
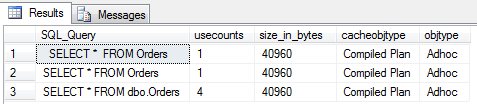
Powyższy wynik pokazuje charakterystyczną cechę buforowania planów wykonania. Każda unikalna kwerenda, posiada swój własny unikalny plan (i zajmuje konkretną liczbę bajtów pamięci). Nawet jeśli logicznie jest identyczna a różni się nieznacznie syntaktycznie, np. brakiem schematu (druga) lub tylko dodatkową spacją (ostatnie zapytanie). Każda z nich przeszła pełen proces „kompilacji” i optymalizacji. Wyjątkiem jest kwerenda wyświetlana w wynikach jako ostatnia – ją wykonałem w sumie 4 razy, w oparciu o ten sam plan, ponieważ udało się dopasować w 100% zapytanie do istniejącego, w pamięci podręcznej.
Naturalnie nasuwa się od razu pytanie, co w sytuacji gdy wykonujemy kwerendy z warunkami, czyli ogólnie mówiąc parametryzowane.
Wielokrotne wykorzystanie tych samych planów wykonania
Weźmy teraz pod uwagę dwa zapytania, które ze swej natury muszą być różne, a dla których plan wykonania z pewnością jest taki sam :
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT;
GO
SELECT * FROM dbo.Orders WHERE CustomerID = 'ERNSH'
GO
SELECT * FROM dbo.Orders WHERE CustomerID = 'FRANK'
GO
SELECT qt.TEXT as SQL_Query, usecounts, size_in_bytes ,
cacheobjtype, objtype
FROM sys.dm_exec_cached_plans p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) qt
WHERE qt.TEXT like '%Orders%'
and qt.TEXT not like '%dm_exec%'

Znów mamy dwa osobne plany, każda z tych kwerend przeszła wszystkie kroki w procesie przetwarzania zapytania. Może być to niepokojące, szczególnie gdy tego typu zapytań są setki czy tysiące. Czy za każdym razem serwer przygotowuje pełną ścieżkę dla tak podobnych zapytań?
Rozwiązaniem problemu parametryzacji jest tzw. kontekst wykonania zapytania, który jest bezpośrednio powiązany z planem. Kwerendy sparametryzowane, spotykamy najczęściej w procedurach składowanych, funkcjach tabelarycznych. Wykorzystują one zamiast czystych zmiennych – parametry, dlatego z punktu widzenia silnika są identyczne i możliwe jest dla nich ponowne użycie już utworzonego planu.
Przeanalizujmy teraz wywołanie naszej wcześniejszej kwerendy, ale zapisanej trochę inaczej (z wykorzystaniem procedury sp_executesql, aby zadać prawdziwie sparametryzowane pytanie) :
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
CHECKPOINT;
EXEC sp_executesql
N'SELECT * FROM dbo.Orders WHERE CustomerID = @CustID',
N'@CustID CHAR(5)', N'ERNSH'
EXEC sp_executesql
N'SELECT * FROM dbo.Orders WHERE CustomerID = @CustID',
N'@CustID CHAR(5)', N'FRANK'
SELECT qt.TEXT as SQL_Query, usecounts, size_in_bytes ,
cacheobjtype, objtype
FROM sys.dm_exec_cached_plans p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) qt
WHERE qt.TEXT like '%Orders%'
and qt.TEXT not like '%dm_exec%'

Różnica jest widoczna na pierwszy rzut oka. Dla każdej z nich, plan zapytania jest ten sam – zawiera parametr @CustID. Co więcej, widać licznik użycia = 2, czyli faktycznie druga kwerenda wykonana zostanie z pewnością szybciej niż pierwsza (skorzysta z istniejącego planu wykonania).
Buforowanie danych
SQL Server buforuje obiekty różnego typu, nie tylko plany zapytania. Od początku istnienia systemów bazodanowych, dostęp do zasobów dyskowych, operacje IO były najwolniejszym ogniwem i najczęstszym powodem problemów wydajnościowych. Dlatego silnik bazodanowy, stara się jak najrzadziej korzystać z fizycznych odczytów. Raz pobrane informacje (rekordy), są przechowywane tak długo jak to tylko możliwe w buforze. Statystyki odczytów są więc jednymi z dwóch głównych (obok czasu) wyznaczników jakości zapytania (im mniej tym lepiej).
Najprostszym sposobem na sprawdzenie statystyk odczytów jest włączenie zmiennej SET STATISTICS IO ON. Zróbmy prosty test :
DBCC DROPCLEANBUFFERS; -- czyszczenie pamięci podręcznej
SET STATISTICS IO ON
SELECT * FROM dbo.Orders WHERE CustomerID = 'FRANK'
GO
SELECT * FROM dbo.Orders WHERE CustomerID = 'FRANK'
GO

Wykonaliśmy dwa razy to samo zapytanie a statystyki odczytów są różne. W pierwszym wyniku, mamy oprócz odczytów logicznych (z pamięci operacyjnej) obecne także odczyty fizyczne (1+20). Trzeba było w końcu te dane najpierw przeczytać z dysku. Kolejne wykonanie tej samej kwerendy nie sięgania fizycznie do zasobów dyskowych – czyta wszystko z pamięci.
Warto od razu zaznaczyć, że informacje na temat statystyk prezentowane za pomocą tej opcji, bywają przekłamane i nie można w 100% na nich polegać. Opisuję ten problem szczegółowo w artykule na temat metodyki pomiaru wydajności zapytań za pomocą Extended Events, Profilera czy dynamicznych widoków systemowych.
Podsumowanie
Powyższe informacje miały na celu pokazanie, ogólnej koncepcji mechanizmów wykonywania zapytań SQL przez silnik bazodanowy. Podczas testowania zapytań, konieczne jest czyszczenie pamięci podręcznej z planów oraz innych obiektów (danych), aby metrologia procesu porównywania wydajności miała sens.
Dzięki, za przedstawienie w prosty sposób wiedzy 😉
Szkoda, że dopiero teraz znalazłem tą stronkę ale widocznie przypadków nie ma i tak miało być. Co do optymalizacji to w mojej firmie generowanie pewnych danych trwało od 4 do 5 godz (wykonywanie w nocy) a po przepisaniu i optymalizacji kwerend doszedłem do 20 min ;D. Mam nadzieję że po zapoznaniu się z wiedzą którą mi jeszcze brakuje zoptymalizuje kwerendy i zaoszczędzę jeszcze kilka min.
Jeszcze raz dzięki za wiedzę.
Pozdrawiam
Baza Northwind zawiera mało danych i pewnie w jej przypadku optymalizacja zapytań (a co za tym idzie, wzrost ich wydajności) nie ma sensu. Zysk kilkunastu milisekund jest niezauważalny. Ale gdybyśmy wzięli pod uwagę prawdziwe bazy danych, takie używane w firmach, albo coś większego np. hurtownie danych. Jak w ich przypadku wygląda porównanie czasu wykonania zapytań niezoptymalizowanych (albo wręcz nieoptymalnie napisanych) i zoptymalizowanych? Czy w wyniku optymalizacji zyskujemy zaledwie kilka sekund na zapytaniu, czy ta różnica czasu jest znacznie większa?
Różnice mogą być bardzo duże. Zapytania wykonujące się wiele minut, po odpowiedniej optymalizacji, mogą trwać ułamki sekund. Pewnie nie ma sensu optymalizować o milisekundy, gdy na bazie działa kilku użytkowników i jest mało danych. Z drugiej strony, czasem jest niby mało danych, ale może być bardzo wielu użytkowników i wtedy redukcja czasu, liczby odczytów może mieć spore znaczenie. Szczególnie przy wzroście wydajności wielodostępu i współbieżności transakcji. Pozdrowienia !
No właśnie, ile to jest te wiele minut w niezoptymalizowanych zapytaniach? Domyślam się że rozrzut może być duży, ale tak mniej więcej? 1-5-10 minut? No bo więcej to chyba nie?
Myślę, że nie ma górnej granicy 🙂 wszystko zależy od implementacji, rozmiaru bazy i wyobraźni developerów. Spotyka się systemy w których zapytania wykonują się nawet parę godzin, a po optymalizacji, dodaniu/modyfikacji odpowiednich struktur parę minut czy nawet sekund. Poziom wiedzy robi się coraz wyższy, łatwo doczytać różne informacje i uniknąć podstawowych błędów, ale wciąż można spotkać tego typu kwiatki.
„parę godzin” – aż tyle?! No to faktycznie teraz widać potrzebę optymalizacji zapytań. Dziękuję za wyjaśnienia.
Poniższy kod oblicza czas zapytania do bazy danych. Owszem, jest prosty, ale co Pan o nim sądzi? Czy nadaje się, czy zawiera jakieś podstawowe błędy, np. związane z czyszczeniem pamięci? Czy wyniki uzyskane za jego pomocą można uznać za wiarygodne?
Generalnie ok. można tak mierzyć, tylko ustawienie zmiennej @czas zrobiłbym po CHECKPOINT, tuż przed zapytaniem bo chodzi nam o czas samego zapytania.
Świetny wpis!
Dzięki